 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Cultural Archives: Cultural Commonsense Knowledge Graph Extraction
Jan 25, 2026Large language models (LLMs) encode rich cultural knowledge learned from diverse web-scale data, offering an unprecedented opportunity to model cultural commonsense at scale. Yet this knowledge remains mostly implicit and unstructured, limiting its interpretability and use. We present an iterative, prompt-based framework for constructing a Cultural Commonsense Knowledge Graph (CCKG) that treats LLMs as cultural archives, systematically eliciting culture-specific entities, relations, and practices and composing them into multi-step inferential chains across languages. We evaluate CCKG on five countries with human judgments of cultural relevance, correctness, and path coherence. We find that the cultural knowledge graphs are better realized in English, even when the target culture is non-English (e.g., Chinese, Indonesian, Arabic), indicating uneven cultural encoding in current LLMs. Augmenting smaller LLMs with CCKG improves performance on cultural reasoning and story generation, with the largest gains from English chains. Our results show both the promise and limits of LLMs as cultural technologies and that chain-structured cultural knowledge is a practical substrate for culturally grounded NLP.
Preserving Fairness and Safety in Quantized LLMs Through Critical Weight Protection
Jan 17, 2026Quantization is widely adopted to reduce the computational cost of large language models (LLMs); however, its implications for fairness and safety, particularly in dynamic quantization and multilingual contexts, remain underexplored. In this work, we conduct a systematic study of how static and dynamic quantization methods impact fairness and safety across benchmarks measuring intrinsic and extrinsic bias and safety alignment. For fairness, we evaluate English, French, Dutch, Spanish, and Turkish; for safety, we focus on English, Korean, and Arabic. Our findings reveal that quantization consistently degrades fairness and safety, with dynamic methods demonstrating greater stability than static ones. Moreover, fairness degradation varies across languages, while safety deterioration is especially pronounced in non-English settings. To address these risks, we introduce Critical Weight Protection, a novel technique that identifies and preserves fairness- and safety-critical weights during quantization. This approach effectively mitigates bias and safety deterioration without costly retraining or alignment, maintaining trustworthiness while retaining efficiency.
AMIR-GRPO: Inducing Implicit Preference Signals into GRPO
Jan 07, 2026Reinforcement learning has become the primary paradigm for aligning large language models (LLMs) on complex reasoning tasks, with group relative policy optimization (GRPO) widely used in large-scale post-training. However, GRPO faces structural limitations in reasoning-heavy settings: sequence-level advantage normalization introduces systematic length bias, penalties for low-quality trajectories are diluted, and the scalar objective discards rich pairwise preference information embedded in within-group reward rankings. As a result, valuable supervision from costly rollouts remains underutilized. We propose AMIR-GRPO, which augments GRPO with an implicit DPO-style contrastive regularizer constructed directly from intra-group reward rankings, requiring no additional annotations. This mechanism amplifies suppression of low-reward trajectories, attenuates response-level length bias, and transforms each rollout group into a denser set of supervision constraints. Across multiple mathematical reasoning benchmarks, AMIR-GRPO consistently outperforms strong GRPO baselines, yields clearer separation between correct and incorrect reasoning chains, and delivers broader coverage gains beyond the subset of instances solved by standard GRPO.
Revisiting Metric Reliability for Fine-grained Evaluation of Machine Translation and Summarization in Indian Languages
Oct 08, 2025While automatic metrics drive progress in Machine Translation (MT) and Text Summarization (TS), existing metrics have been developed and validated almost exclusively for English and other high-resource languages. This narrow focus leaves Indian languages, spoken by over 1.5 billion people, largely overlooked, casting doubt on the universality of current evaluation practices. To address this gap, we introduce ITEM, a large-scale benchmark that systematically evaluates the alignment of 26 automatic metrics with human judgments across six major Indian languages, enriched with fine-grained annotations. Our extensive evaluation, covering agreement with human judgments, sensitivity to outliers, language-specific reliability, inter-metric correlations, and resilience to controlled perturbations, reveals four central findings: (1) LLM-based evaluators show the strongest alignment with human judgments at both segment and system levels; (2) outliers exert a significant impact on metric-human agreement; (3) in TS, metrics are more effective at capturing content fidelity, whereas in MT, they better reflect fluency; and (4) metrics differ in their robustness and sensitivity when subjected to diverse perturbations. Collectively, these findings offer critical guidance for advancing metric design and evaluation in Indian languages.
Entropy2Vec: Crosslingual Language Modeling Entropy as End-to-End Learnable Language Representations
Sep 05, 2025We introduce Entropy2Vec, a novel framework for deriving cross-lingual language representations by leveraging the entropy of monolingual language models. Unlike traditional typological inventories that suffer from feature sparsity and static snapshots, Entropy2Vec uses the inherent uncertainty in language models to capture typological relationships between languages. By training a language model on a single language, we hypothesize that the entropy of its predictions reflects its structural similarity to other languages: Low entropy indicates high similarity, while high entropy suggests greater divergence. This approach yields dense, non-sparse language embeddings that are adaptable to different timeframes and free from missing values. Empirical evaluations demonstrate that Entropy2Vec embeddings align with established typological categories and achieved competitive performance in downstream multilingual NLP tasks, such as those addressed by the LinguAlchemy framework.
SEADialogues: A Multilingual Culturally Grounded Multi-turn Dialogue Dataset on Southeast Asian Languages
Aug 09, 2025Although numerous datasets have been developed to support dialogue systems, most existing chit-chat datasets overlook the cultural nuances inherent in natural human conversations. To address this gap, we introduce SEADialogues, a culturally grounded dialogue dataset centered on Southeast Asia, a region with over 700 million people and immense cultural diversity. Our dataset features dialogues in eight languages from six Southeast Asian countries, many of which are low-resource despite having sizable speaker populations. To enhance cultural relevance and personalization, each dialogue includes persona attributes and two culturally grounded topics that reflect everyday life in the respective communities. Furthermore, we release a multi-turn dialogue dataset to advance research on culturally aware and human-centric large language models, including conversational dialogue agents.
Language Surgery in Multilingual Large Language Models
Jun 14, 2025Large Language Models (LLMs) have demonstrated remarkable generalization capabilities across tasks and languages, revolutionizing natural language processing. This paper investigates the naturally emerging representation alignment in LLMs, particularly in the middle layers, and its implications for disentangling language-specific and language-agnostic information. We empirically confirm the existence of this alignment, analyze its behavior in comparison to explicitly designed alignment models, and demonstrate its potential for language-specific manipulation without semantic degradation. Building on these findings, we propose Inference-Time Language Control (ITLC), a novel method that leverages latent injection to enable precise cross-lingual language control and mitigate language confusion in LLMs. Our experiments highlight ITLC's strong cross-lingual control capabilities while preserving semantic integrity in target languages. Furthermore, we demonstrate its effectiveness in alleviating the cross-lingual language confusion problem, which persists even in current large-scale LLMs, leading to inconsistent language generation. This work advances our understanding of representation alignment in LLMs and introduces a practical solution for enhancing their cross-lingual performance.
What Do Indonesians Really Need from Language Technology? A Nationwide Survey
Jun 09, 2025



There is an emerging effort to develop NLP for Indonesias 700+ local languages, but progress remains costly due to the need for direct engagement with native speakers. However, it is unclear what these language communities truly need from language technology. To address this, we conduct a nationwide survey to assess the actual needs of native speakers in Indonesia. Our findings indicate that addressing language barriers, particularly through machine translation and information retrieval, is the most critical priority. Although there is strong enthusiasm for advancements in language technology, concerns around privacy, bias, and the use of public data for AI training highlight the need for greater transparency and clear communication to support broader AI adoption.
Evaluating Vision-Language and Large Language Models for Automated Student Assessment in Indonesian Classrooms
Jun 05, 2025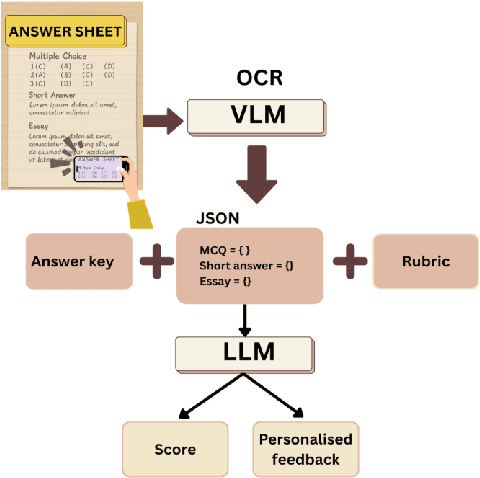
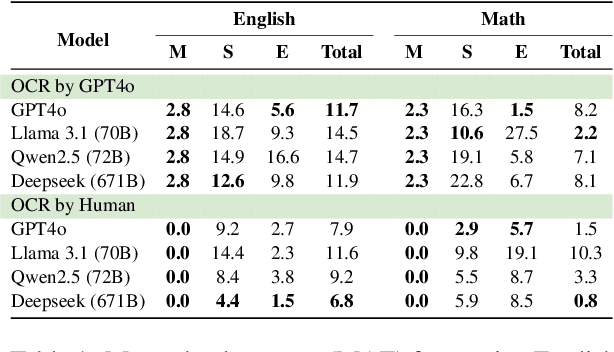
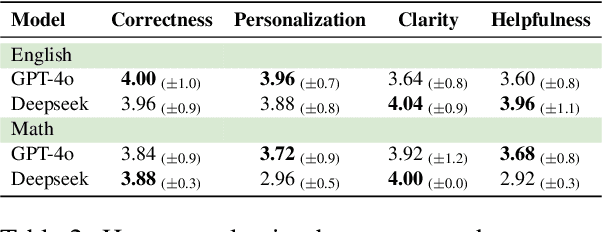

Although vision-language and large language models (VLM and LLM) offer promising opportunities for AI-driven educational assessment, their effectiveness in real-world classroom settings, particularly in underrepresented educational contexts, remains underexplored. In this study, we evaluated the performance of a state-of-the-art VLM and several LLMs on 646 handwritten exam responses from grade 4 students in six Indonesian schools, covering two subjects: Mathematics and English. These sheets contain more than 14K student answers that span multiple choice, short answer, and essay questions. Assessment tasks include grading these responses and generating personalized feedback. Our findings show that the VLM often struggles to accurately recognize student handwriting, leading to error propagation in downstream LLM grading. Nevertheless, LLM-generated feedback retains some utility, even when derived from imperfect input, although limitations in personalization and contextual relevance persist.
Simulating LLM-to-LLM Tutoring for Multilingual Math Feedback
Jun 05, 2025Large language models (LLMs) have demonstrated the ability to generate formative feedback and instructional hints in English, making them increasingly relevant for AI-assisted education. However, their ability to provide effective instructional support across different languages, especially for mathematically grounded reasoning tasks, remains largely unexamined. In this work, we present the first large-scale simulation of multilingual tutor-student interactions using LLMs. A stronger model plays the role of the tutor, generating feedback in the form of hints, while a weaker model simulates the student. We explore 352 experimental settings across 11 typologically diverse languages, four state-of-the-art LLMs, and multiple prompting strategies to assess whether language-specific feedback leads to measurable learning gains. Our study examines how student input language, teacher feedback language, model choice, and language resource level jointly influence performance. Results show that multilingual hints can significantly improve learning outcomes, particularly in low-resource languages when feedback is aligned with the student's native language. These findings offer practical insights for developing multilingual, LLM-based educational tools that are both effective and inclusive.