 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlama-3-Nanda-10B-Chat: An Open Generative Large Language Model for Hindi
Apr 08, 2025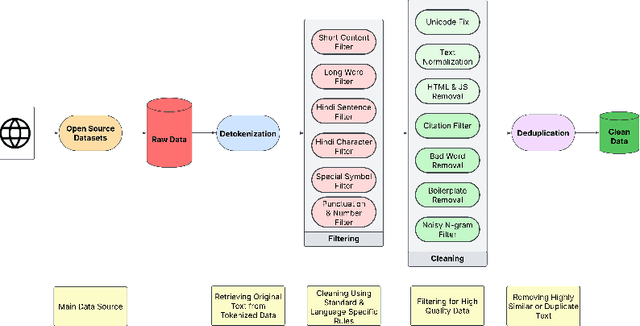

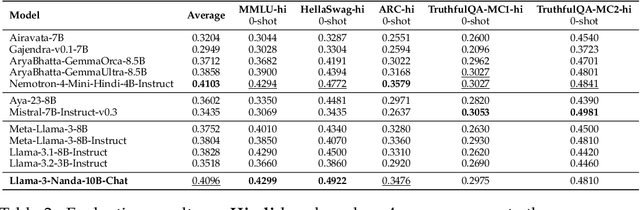

Developing high-quality large language models (LLMs) for moderately resourced languages presents unique challenges in data availability, model adaptation, and evaluation. We introduce Llama-3-Nanda-10B-Chat, or Nanda for short, a state-of-the-art Hindi-centric instruction-tuned generative LLM, designed to push the boundaries of open-source Hindi language models. Built upon Llama-3-8B, Nanda incorporates continuous pre-training with expanded transformer blocks, leveraging the Llama Pro methodology. A key challenge was the limited availability of high-quality Hindi text data; we addressed this through rigorous data curation, augmentation, and strategic bilingual training, balancing Hindi and English corpora to optimize cross-linguistic knowledge transfer. With 10 billion parameters, Nanda stands among the top-performing open-source Hindi and multilingual models of similar scale, demonstrating significant advantages over many existing models. We provide an in-depth discussion of training strategies, fine-tuning techniques, safety alignment, and evaluation metrics, demonstrating how these approaches enabled Nanda to achieve state-of-the-art results. By open-sourcing Nanda, we aim to advance research in Hindi LLMs and support a wide range of real-world applications across academia, industry, and public services.
Ethical Reasoning and Moral Value Alignment of LLMs Depend on the Language we Prompt them in
Apr 29, 2024Ethical reasoning is a crucial skill for Large Language Models (LLMs). However, moral values are not universal, but rather influenced by language and culture. This paper explores how three prominent LLMs -- GPT-4, ChatGPT, and Llama2-70B-Chat -- perform ethical reasoning in different languages and if their moral judgement depend on the language in which they are prompted. We extend the study of ethical reasoning of LLMs by Rao et al. (2023) to a multilingual setup following their framework of probing LLMs with ethical dilemmas and policies from three branches of normative ethics: deontology, virtue, and consequentialism. We experiment with six languages: English, Spanish, Russian, Chinese, Hindi, and Swahili. We find that GPT-4 is the most consistent and unbiased ethical reasoner across languages, while ChatGPT and Llama2-70B-Chat show significant moral value bias when we move to languages other than English. Interestingly, the nature of this bias significantly vary across languages for all LLMs, including GPT-4.
Do Moral Judgment and Reasoning Capability of LLMs Change with Language? A Study using the Multilingual Defining Issues Test
Feb 03, 2024This paper explores the moral judgment and moral reasoning abilities exhibited by Large Language Models (LLMs) across languages through the Defining Issues Test. It is a well known fact that moral judgment depends on the language in which the question is asked. We extend the work of beyond English, to 5 new languages (Chinese, Hindi, Russian, Spanish and Swahili), and probe three LLMs -- ChatGPT, GPT-4 and Llama2Chat-70B -- that shows substantial multilingual text processing and generation abilities. Our study shows that the moral reasoning ability for all models, as indicated by the post-conventional score, is substantially inferior for Hindi and Swahili, compared to Spanish, Russian, Chinese and English, while there is no clear trend for the performance of the latter four languages. The moral judgments too vary considerably by the language.
Ethical Reasoning over Moral Alignment: A Case and Framework for In-Context Ethical Policies in LLMs
Oct 11, 2023In this position paper, we argue that instead of morally aligning LLMs to specific set of ethical principles, we should infuse generic ethical reasoning capabilities into them so that they can handle value pluralism at a global scale. When provided with an ethical policy, an LLM should be capable of making decisions that are ethically consistent to the policy. We develop a framework that integrates moral dilemmas with moral principles pertaining to different foramlisms of normative ethics, and at different levels of abstractions. Initial experiments with GPT-x models shows that while GPT-4 is a nearly perfect ethical reasoner, the models still have bias towards the moral values of Western and English speaking societies.
Exploring Large Language Models' Cognitive Moral Development through Defining Issues Test
Sep 23, 2023The development of large language models has instilled widespread interest among the researchers to understand their inherent reasoning and problem-solving capabilities. Despite good amount of research going on to elucidate these capabilities, there is a still an appreciable gap in understanding moral development and judgments of these models. The current approaches of evaluating the ethical reasoning abilities of these models as a classification task pose numerous inaccuracies because of over-simplification. In this study, we built a psychological connection by bridging two disparate fields-human psychology and AI. We proposed an effective evaluation framework which can help to delineate the model's ethical reasoning ability in terms of moral consistency and Kohlberg's moral development stages with the help of Psychometric Assessment Tool-Defining Issues Test.