 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Routing Dynamics in Mixture-of-Experts Models for Efficient Language Adaptation
May 28, 2026Mixture-of-Experts (MoE) models are widely used to scale language models, yet their expert routing behavior and adaptation in a multilingual setting remain underexplored. In this work, we study multilingual routing dynamics during continual pre-training of an English-centric MoE model on a multilingual corpus, analyzing how expert usage varies across languages. We find that continual multilingual pre-training leads to diffused, language-agnostic routing in early and middle layers, with language specialization primarily emerging in the final layers. We also show that token-level vocabulary overlap between languages plays an important role in how languages are routed. Motivated by these findings, we propose a parameter-efficient adaptation strategy that updates language-specific and shared experts in the final MoE layers. Experiments on MultiBLiMP and Belebele show that our method achieves a strong performance-efficiency trade-off, attaining competitive performance relative to fine-tuning complete final layers, while updating less than 2% of the parameters. Overall, our findings provide insights into where and how language specialization emerges in MoEs during continual pre-training and provide practical insights for low-resource multilingual adaptation. Our code is available at https://github.com/aditi184/moe-routing-adaptation.
Multilingual Amnesia: On the Transferability of Unlearning in Multilingual LLMs
Jan 09, 2026As multilingual large language models become more widely used, ensuring their safety and fairness across diverse linguistic contexts presents unique challenges. While existing research on machine unlearning has primarily focused on monolingual settings, typically English, multilingual environments introduce additional complexities due to cross-lingual knowledge transfer and biases embedded in both pretraining and fine-tuning data. In this work, we study multilingual unlearning using the Aya-Expanse 8B model under two settings: (1) data unlearning and (2) concept unlearning. We extend benchmarks for factual knowledge and stereotypes to ten languages through translation: English, French, Arabic, Japanese, Russian, Farsi, Korean, Hindi, Hebrew, and Indonesian. These languages span five language families and a wide range of resource levels. Our experiments show that unlearning in high-resource languages is generally more stable, with asymmetric transfer effects observed between typologically related languages. Furthermore, our analysis of linguistic distances indicates that syntactic similarity is the strongest predictor of cross-lingual unlearning behavior.
Cross-Lingual Multi-Hop Knowledge Editing -- Benchmarks, Analysis and a Simple Contrastive Learning based Approach
Jul 14, 2024



Large language models are often expected to constantly adapt to new sources of knowledge and knowledge editing techniques aim to efficiently patch the outdated model knowledge, with minimal modification. Most prior works focus on monolingual knowledge editing in English, even though new information can emerge in any language from any part of the world. We propose the Cross-Lingual Multi-Hop Knowledge Editing paradigm, for measuring and analyzing the performance of various SoTA knowledge editing techniques in a cross-lingual setup. Specifically, we create a parallel cross-lingual benchmark, CROLIN-MQUAKE for measuring the knowledge editing capabilities. Our extensive analysis over various knowledge editing techniques uncover significant gaps in performance between the cross-lingual and English-centric setting. Following this, we propose a significantly improved system for cross-lingual multi-hop knowledge editing, CLEVER-CKE. CLEVER-CKE is based on a retrieve, verify and generate knowledge editing framework, where a retriever is formulated to recall edited facts and support an LLM to adhere to knowledge edits. We develop language-aware and hard-negative based contrastive objectives for improving the cross-lingual and fine-grained fact retrieval and verification process used in this framework. Extensive experiments on three LLMs, eight languages, and two datasets show CLEVER-CKE's significant gains of up to 30% over prior methods.
Ethical Reasoning and Moral Value Alignment of LLMs Depend on the Language we Prompt them in
Apr 29, 2024



Ethical reasoning is a crucial skill for Large Language Models (LLMs). However, moral values are not universal, but rather influenced by language and culture. This paper explores how three prominent LLMs -- GPT-4, ChatGPT, and Llama2-70B-Chat -- perform ethical reasoning in different languages and if their moral judgement depend on the language in which they are prompted. We extend the study of ethical reasoning of LLMs by Rao et al. (2023) to a multilingual setup following their framework of probing LLMs with ethical dilemmas and policies from three branches of normative ethics: deontology, virtue, and consequentialism. We experiment with six languages: English, Spanish, Russian, Chinese, Hindi, and Swahili. We find that GPT-4 is the most consistent and unbiased ethical reasoner across languages, while ChatGPT and Llama2-70B-Chat show significant moral value bias when we move to languages other than English. Interestingly, the nature of this bias significantly vary across languages for all LLMs, including GPT-4.
Do Moral Judgment and Reasoning Capability of LLMs Change with Language? A Study using the Multilingual Defining Issues Test
Feb 03, 2024



This paper explores the moral judgment and moral reasoning abilities exhibited by Large Language Models (LLMs) across languages through the Defining Issues Test. It is a well known fact that moral judgment depends on the language in which the question is asked. We extend the work of beyond English, to 5 new languages (Chinese, Hindi, Russian, Spanish and Swahili), and probe three LLMs -- ChatGPT, GPT-4 and Llama2Chat-70B -- that shows substantial multilingual text processing and generation abilities. Our study shows that the moral reasoning ability for all models, as indicated by the post-conventional score, is substantially inferior for Hindi and Swahili, compared to Spanish, Russian, Chinese and English, while there is no clear trend for the performance of the latter four languages. The moral judgments too vary considerably by the language.
Ethical Reasoning over Moral Alignment: A Case and Framework for In-Context Ethical Policies in LLMs
Oct 11, 2023In this position paper, we argue that instead of morally aligning LLMs to specific set of ethical principles, we should infuse generic ethical reasoning capabilities into them so that they can handle value pluralism at a global scale. When provided with an ethical policy, an LLM should be capable of making decisions that are ethically consistent to the policy. We develop a framework that integrates moral dilemmas with moral principles pertaining to different foramlisms of normative ethics, and at different levels of abstractions. Initial experiments with GPT-x models shows that while GPT-4 is a nearly perfect ethical reasoner, the models still have bias towards the moral values of Western and English speaking societies.
Exploring Large Language Models' Cognitive Moral Development through Defining Issues Test
Sep 23, 2023



The development of large language models has instilled widespread interest among the researchers to understand their inherent reasoning and problem-solving capabilities. Despite good amount of research going on to elucidate these capabilities, there is a still an appreciable gap in understanding moral development and judgments of these models. The current approaches of evaluating the ethical reasoning abilities of these models as a classification task pose numerous inaccuracies because of over-simplification. In this study, we built a psychological connection by bridging two disparate fields-human psychology and AI. We proposed an effective evaluation framework which can help to delineate the model's ethical reasoning ability in terms of moral consistency and Kohlberg's moral development stages with the help of Psychometric Assessment Tool-Defining Issues Test.
DUBLIN -- Document Understanding By Language-Image Network
May 24, 2023

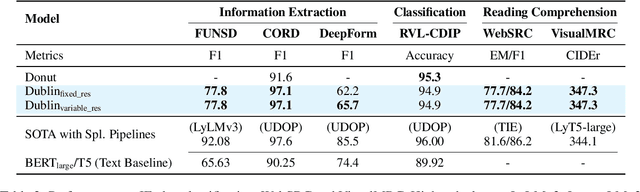

Visual document understanding is a complex task that involves analyzing both the text and the visual elements in document images. Existing models often rely on manual feature engineering or domain-specific pipelines, which limit their generalization ability across different document types and languages. In this paper, we propose DUBLIN, which is pretrained on web pages using three novel objectives: Masked Document Content Generation Task, Bounding Box Task, and Rendered Question Answering Task, that leverage both the spatial and semantic information in the document images. Our model achieves competitive or state-of-the-art results on several benchmarks, such as Web-Based Structural Reading Comprehension, Document Visual Question Answering, Key Information Extraction, Diagram Understanding, and Table Question Answering. In particular, we show that DUBLIN is the first pixel-based model to achieve an EM of 77.75 and F1 of 84.25 on the WebSRC dataset. We also show that our model outperforms the current pixel-based SoTA models on DocVQA and AI2D datasets by 2% and 21%, respectively. Also, DUBLIN is the first ever pixel-based model which achieves comparable performance to text-based SoTA methods on XFUND dataset for Semantic Entity Recognition showcasing its multilingual capability. Moreover, we create new baselines for text-based datasets by rendering them as document images to promote research in this direction.