 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$V_1$: Unifying Generation and Self-Verification for Parallel Reasoners
Mar 04, 2026Test-time scaling for complex reasoning tasks shows that leveraging inference-time compute, by methods such as independently sampling and aggregating multiple solutions, results in significantly better task outcomes. However, a critical bottleneck is verification: sampling is only effective if correct solutions can be reliably identified among candidates. While existing approaches typically evaluate candidates independently via scalar scoring, we demonstrate that models are substantially stronger at pairwise self-verification. Leveraging this insight, we introduce $V_1$, a framework that unifies generation and verification through efficient pairwise ranking. $V_1$ comprises two components: $V_1$-Infer, an uncertainty-guided algorithm using a tournament-based ranking that dynamically allocates self-verification compute to candidate pairs whose relative correctness is most uncertain; and $V_1$-PairRL, an RL framework that jointly trains a single model as both generator and pairwise self-verifier, ensuring the verifier adapts to the generator's evolving distribution. On code generation (LiveCodeBench, CodeContests, SWE-Bench) and math reasoning (AIME, HMMT) benchmarks, $V_1$-Infer improves Pass@1 by up to $10%$ over pointwise verification and outperforms recent test-time scaling methods while being significantly more efficient. Furthermore, $V_1$-PairRL achieves $7$--$9%$ test-time scaling gains over standard RL and pointwise joint training, and improves base Pass@1 by up to 8.7% over standard RL in a code-generation setting.
Residual Context Diffusion Language Models
Jan 30, 2026Diffusion Large Language Models (dLLMs) have emerged as a promising alternative to purely autoregressive language models because they can decode multiple tokens in parallel. However, state-of-the-art block-wise dLLMs rely on a "remasking" mechanism that decodes only the most confident tokens and discards the rest, effectively wasting computation. We demonstrate that recycling computation from the discarded tokens is beneficial, as these tokens retain contextual information useful for subsequent decoding iterations. In light of this, we propose Residual Context Diffusion (RCD), a module that converts these discarded token representations into contextual residuals and injects them back for the next denoising step. RCD uses a decoupled two-stage training pipeline to bypass the memory bottlenecks associated with backpropagation. We validate our method on both long CoT reasoning (SDAR) and short CoT instruction following (LLaDA) models. We demonstrate that a standard dLLM can be efficiently converted to the RCD paradigm with merely ~1 billion tokens. RCD consistently improves frontier dLLMs by 5-10 points in accuracy with minimal extra computation overhead across a wide range of benchmarks. Notably, on the most challenging AIME tasks, RCD nearly doubles baseline accuracy and attains up to 4-5x fewer denoising steps at equivalent accuracy levels.
CURVE: A Benchmark for Cultural and Multilingual Long Video Reasoning
Jan 15, 2026Recent advancements in video models have shown tremendous progress, particularly in long video understanding. However, current benchmarks predominantly feature western-centric data and English as the dominant language, introducing significant biases in evaluation. To address this, we introduce CURVE (Cultural Understanding and Reasoning in Video Evaluation), a challenging benchmark for multicultural and multilingual video reasoning. CURVE comprises high-quality, entirely human-generated annotations from diverse, region-specific cultural videos across 18 global locales. Unlike prior work that relies on automatic translations, CURVE provides complex questions, answers, and multi-step reasoning steps, all crafted in native languages. Making progress on CURVE requires a deeply situated understanding of visual cultural context. Furthermore, we leverage CURVE's reasoning traces to construct evidence-based graphs and propose a novel iterative strategy using these graphs to identify fine-grained errors in reasoning. Our evaluations reveal that SoTA Video-LLMs struggle significantly, performing substantially below human-level accuracy, with errors primarily stemming from the visual perception of cultural elements. CURVE will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva-cultural
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
GraPE: A Generate-Plan-Edit Framework for Compositional T2I Synthesis
Dec 08, 2024
Text-to-image (T2I) generation has seen significant progress with diffusion models, enabling generation of photo-realistic images from text prompts. Despite this progress, existing methods still face challenges in following complex text prompts, especially those requiring compositional and multi-step reasoning. Given such complex instructions, SOTA models often make mistakes in faithfully modeling object attributes, and relationships among them. In this work, we present an alternate paradigm for T2I synthesis, decomposing the task of complex multi-step generation into three steps, (a) Generate: we first generate an image using existing diffusion models (b) Plan: we make use of Multi-Modal LLMs (MLLMs) to identify the mistakes in the generated image expressed in terms of individual objects and their properties, and produce a sequence of corrective steps required in the form of an edit-plan. (c) Edit: we make use of an existing text-guided image editing models to sequentially execute our edit-plan over the generated image to get the desired image which is faithful to the original instruction. Our approach derives its strength from the fact that it is modular in nature, is training free, and can be applied over any combination of image generation and editing models. As an added contribution, we also develop a model capable of compositional editing, which further helps improve the overall accuracy of our proposed approach. Our method flexibly trades inference time compute with performance on compositional text prompts. We perform extensive experimental evaluation across 3 benchmarks and 10 T2I models including DALLE-3 and the latest -- SD-3.5-Large. Our approach not only improves the performance of the SOTA models, by upto 3 points, it also reduces the performance gap between weaker and stronger models. $\href{https://dair-iitd.github.io/GraPE/}{https://dair-iitd.github.io/GraPE/}$
STAB: Speech Tokenizer Assessment Benchmark
Sep 04, 2024
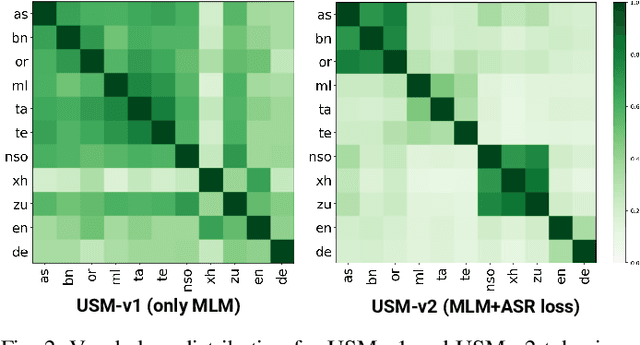
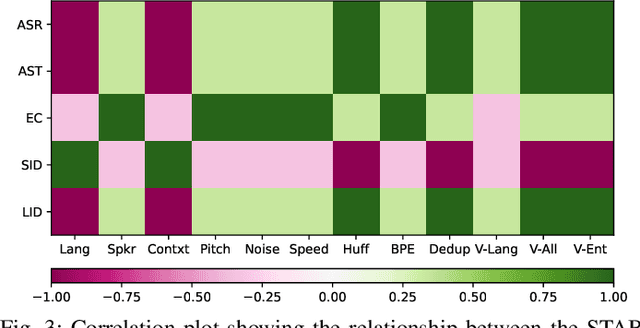
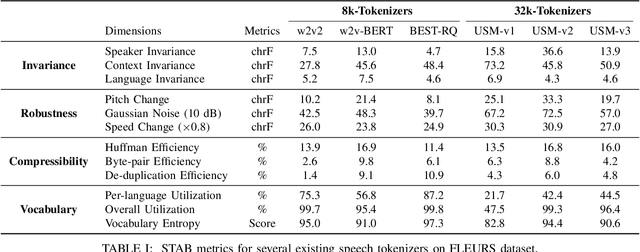
Representing speech as discrete tokens provides a framework for transforming speech into a format that closely resembles text, thus enabling the use of speech as an input to the widely successful large language models (LLMs). Currently, while several speech tokenizers have been proposed, there is ambiguity regarding the properties that are desired from a tokenizer for specific downstream tasks and its overall generalizability. Evaluating the performance of tokenizers across different downstream tasks is a computationally intensive effort that poses challenges for scalability. To circumvent this requirement, we present STAB (Speech Tokenizer Assessment Benchmark), a systematic evaluation framework designed to assess speech tokenizers comprehensively and shed light on their inherent characteristics. This framework provides a deeper understanding of the underlying mechanisms of speech tokenization, thereby offering a valuable resource for expediting the advancement of future tokenizer models and enabling comparative analysis using a standardized benchmark. We evaluate the STAB metrics and correlate this with downstream task performance across a range of speech tasks and tokenizer choices.
Cross-Lingual Multi-Hop Knowledge Editing -- Benchmarks, Analysis and a Simple Contrastive Learning based Approach
Jul 14, 2024



Large language models are often expected to constantly adapt to new sources of knowledge and knowledge editing techniques aim to efficiently patch the outdated model knowledge, with minimal modification. Most prior works focus on monolingual knowledge editing in English, even though new information can emerge in any language from any part of the world. We propose the Cross-Lingual Multi-Hop Knowledge Editing paradigm, for measuring and analyzing the performance of various SoTA knowledge editing techniques in a cross-lingual setup. Specifically, we create a parallel cross-lingual benchmark, CROLIN-MQUAKE for measuring the knowledge editing capabilities. Our extensive analysis over various knowledge editing techniques uncover significant gaps in performance between the cross-lingual and English-centric setting. Following this, we propose a significantly improved system for cross-lingual multi-hop knowledge editing, CLEVER-CKE. CLEVER-CKE is based on a retrieve, verify and generate knowledge editing framework, where a retriever is formulated to recall edited facts and support an LLM to adhere to knowledge edits. We develop language-aware and hard-negative based contrastive objectives for improving the cross-lingual and fine-grained fact retrieval and verification process used in this framework. Extensive experiments on three LLMs, eight languages, and two datasets show CLEVER-CKE's significant gains of up to 30% over prior methods.
IndicGenBench: A Multilingual Benchmark to Evaluate Generation Capabilities of LLMs on Indic Languages
Apr 25, 2024As large language models (LLMs) see increasing adoption across the globe, it is imperative for LLMs to be representative of the linguistic diversity of the world. India is a linguistically diverse country of 1.4 Billion people. To facilitate research on multilingual LLM evaluation, we release IndicGenBench - the largest benchmark for evaluating LLMs on user-facing generation tasks across a diverse set 29 of Indic languages covering 13 scripts and 4 language families. IndicGenBench is composed of diverse generation tasks like cross-lingual summarization, machine translation, and cross-lingual question answering. IndicGenBench extends existing benchmarks to many Indic languages through human curation providing multi-way parallel evaluation data for many under-represented Indic languages for the first time. We evaluate a wide range of proprietary and open-source LLMs including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM and LLaMA on IndicGenBench in a variety of settings. The largest PaLM-2 models performs the best on most tasks, however, there is a significant performance gap in all languages compared to English showing that further research is needed for the development of more inclusive multilingual language models. IndicGenBench is released at www.github.com/google-research-datasets/indic-gen-bench
Coarse-to-Fine Contrastive Learning in Image-Text-Graph Space for Improved Vision-Language Compositionality
May 23, 2023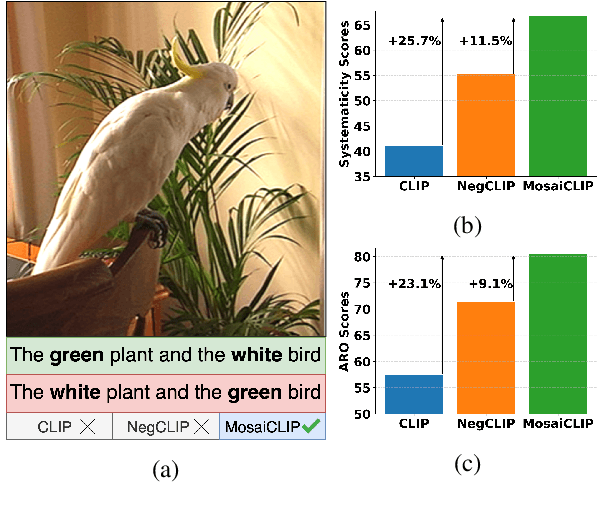



Contrastively trained vision-language models have achieved remarkable progress in vision and language representation learning, leading to state-of-the-art models for various downstream multimodal tasks. However, recent research has highlighted severe limitations of these models in their ability to perform compositional reasoning over objects, attributes, and relations. Scene graphs have emerged as an effective way to understand images compositionally. These are graph-structured semantic representations of images that contain objects, their attributes, and relations with other objects in a scene. In this work, we consider the scene graph parsed from text as a proxy for the image scene graph and propose a graph decomposition and augmentation framework along with a coarse-to-fine contrastive learning objective between images and text that aligns sentences of various complexities to the same image. Along with this, we propose novel negative mining techniques in the scene graph space for improving attribute binding and relation understanding. Through extensive experiments, we demonstrate the effectiveness of our approach that significantly improves attribute binding, relation understanding, systematic generalization, and productivity on multiple recently proposed benchmarks (For example, improvements upto $18\%$ for systematic generalization, $16.5\%$ for relation understanding over a strong baseline), while achieving similar or better performance than CLIP on various general multimodal tasks.
Image Manipulation via Multi-Hop Instructions -- A New Dataset and Weakly-Supervised Neuro-Symbolic Approach
May 23, 2023
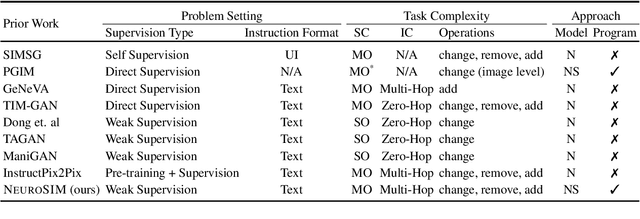
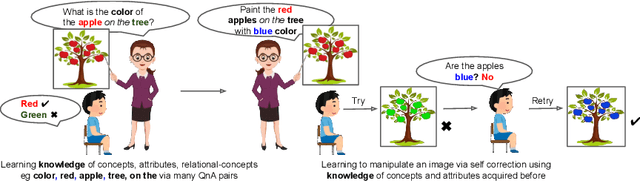
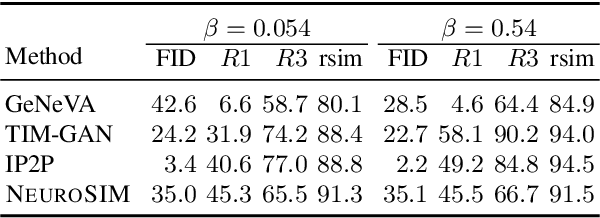
We are interested in image manipulation via natural language text -- a task that is useful for multiple AI applications but requires complex reasoning over multi-modal spaces. We extend recently proposed Neuro Symbolic Concept Learning (NSCL), which has been quite effective for the task of Visual Question Answering (VQA), for the task of image manipulation. Our system referred to as NeuroSIM can perform complex multi-hop reasoning over multi-object scenes and only requires weak supervision in the form of annotated data for VQA. NeuroSIM parses an instruction into a symbolic program, based on a Domain Specific Language (DSL) comprising of object attributes and manipulation operations, that guides its execution. We create a new dataset for the task, and extensive experiments demonstrate that NeuroSIM is highly competitive with or beats SOTA baselines that make use of supervised data for manipulation.