 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCETBench: A Novel Dataset constructed via Transformations over Programs for Benchmarking LLMs for Code-Equivalence Checking
Jun 04, 2025LLMs have been extensively used for the task of automated code generation. In this work, we examine the applicability of LLMs for the related but relatively unexplored task of code-equivalence checking, i.e., given two programs, whether they are functionally equivalent or not. This is an important problem since benchmarking code equivalence can play a critical role in evaluating LLM capabilities for tasks such as code re-writing and code translation. Towards this end, we present CETBench - Code Equivalence with Transformations Benchmark, constructed via a repository of programs, where two programs in the repository may be solving the same or different tasks. Each instance in our dataset is obtained by taking a pair of programs in the repository and applying a random series of pre-defined code transformations, resulting in (non-)equivalent pairs. Our analysis on this dataset reveals a surprising finding that very simple code transformations in the underlying pair of programs can result in a significant drop in performance of SOTA LLMs for the task of code-equivalence checking. To remedy this, we present a simple fine-tuning-based approach to boost LLM performance on the transformed pairs of programs. Our approach for dataset generation is generic, and can be used with repositories with varying program difficulty levels and allows for applying varying numbers as well as kinds of transformations. In our experiments, we perform ablations over the difficulty level of original programs, as well as the kind of transformations used in generating pairs for equivalence checking. Our analysis presents deep insights into the working of LLMs for the task of code-equivalence, and points to the fact that they may still be far from what could be termed as a semantic understanding of the underlying code.
An Approach to Build Zero-Shot Slot-Filling System for Industry-Grade Conversational Assistants
Jun 13, 2024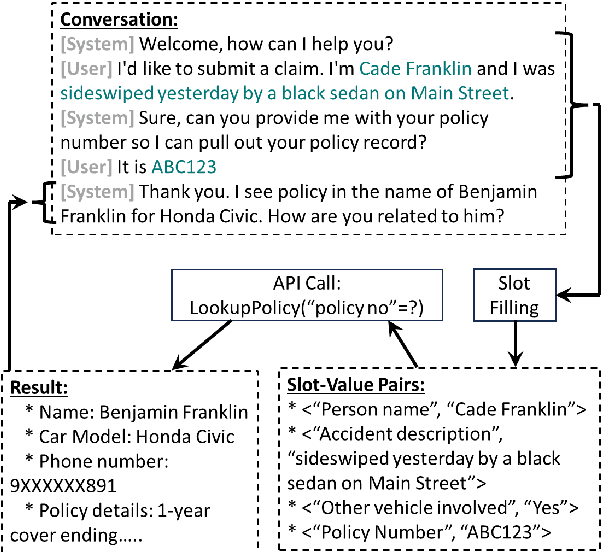
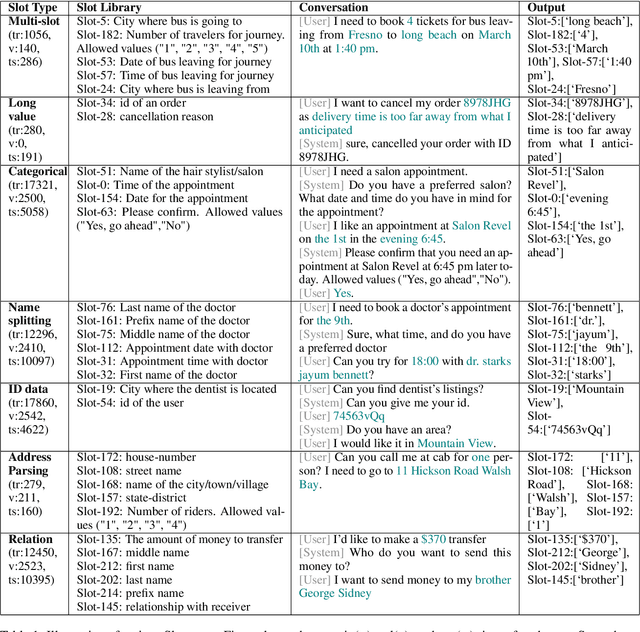
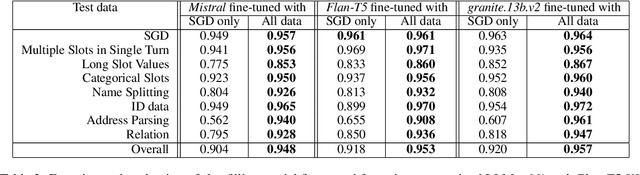

We present an approach to build Large Language Model (LLM) based slot-filling system to perform Dialogue State Tracking in conversational assistants serving across a wide variety of industry-grade applications. Key requirements of this system include: 1) usage of smaller-sized models to meet low latency requirements and to enable convenient and cost-effective cloud and customer premise deployments, and 2) zero-shot capabilities to serve across a wide variety of domains, slot types and conversational scenarios. We adopt a fine-tuning approach where a pre-trained LLM is fine-tuned into a slot-filling model using task specific data. The fine-tuning data is prepared carefully to cover a wide variety of slot-filling task scenarios that the model is expected to face across various domains. We give details of the data preparation and model building process. We also give a detailed analysis of the results of our experimental evaluations. Results show that our prescribed approach for slot-filling model building has resulted in 6.9% relative improvement of F1 metric over the best baseline on a realistic benchmark, while at the same time reducing the latency by 57%. More over, the data we prepared has helped improve F1 on an average by 4.2% relative across various slot-types.
Read between the lines -- Functionality Extraction From READMEs
Mar 15, 2024While text summarization is a well-known NLP task, in this paper, we introduce a novel and useful variant of it called functionality extraction from Git README files. Though this task is a text2text generation at an abstract level, it involves its own peculiarities and challenges making existing text2text generation systems not very useful. The motivation behind this task stems from a recent surge in research and development activities around the use of large language models for code-related tasks, such as code refactoring, code summarization, etc. We also release a human-annotated dataset called FuncRead, and develop a battery of models for the task. Our exhaustive experimentation shows that small size fine-tuned models beat any baseline models that can be designed using popular black-box or white-box large language models (LLMs) such as ChatGPT and Bard. Our best fine-tuned 7 Billion CodeLlama model exhibit 70% and 20% gain on the F1 score against ChatGPT and Bard respectively.
Fill in the Blank: Exploring and Enhancing LLM Capabilities for Backward Reasoning in Math Word Problems
Oct 03, 2023

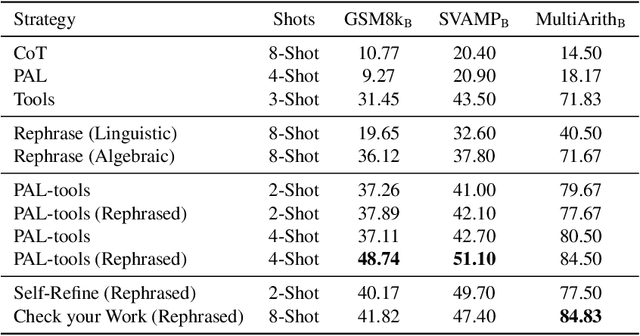

While forward reasoning (i.e. find the answer given the question) has been explored extensively in the recent literature, backward reasoning is relatively unexplored. We examine the backward reasoning capabilities of LLMs on Math Word Problems (MWPs): given a mathematical question and its answer, with some details omitted from the question, can LLMs effectively retrieve the missing information? In this paper, we formally define the backward reasoning task on math word problems and modify three datasets to evaluate this task: GSM8k, SVAMP and MultiArith. Our findings show a significant drop in the accuracy of models on backward reasoning compared to forward reasoning across four SOTA LLMs (GPT4, GPT3.5, PaLM-2, and LLaMa-2). Utilizing the specific format of this task, we propose three novel techniques that improve performance: Rephrase reformulates the given problem into a forward reasoning problem, PAL-Tools combines the idea of Program-Aided LLMs to produce a set of equations that can be solved by an external solver, and Check your Work exploits the availability of natural verifier of high accuracy in the forward direction, interleaving solving and verification steps. Finally, realizing that each of our base methods correctly solves a different set of problems, we propose a novel Bayesian formulation for creating an ensemble over these base methods aided by a verifier to further boost the accuracy by a significant margin. Extensive experimentation demonstrates that our techniques successively improve the performance of LLMs on the backward reasoning task, with the final ensemble-based method resulting in a substantial performance gain compared to the raw LLMs with standard prompting techniques such as chain-of-thought.
Image Manipulation via Multi-Hop Instructions -- A New Dataset and Weakly-Supervised Neuro-Symbolic Approach
May 23, 2023
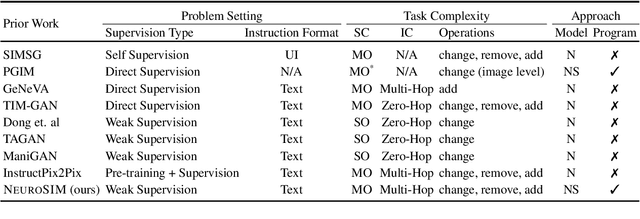
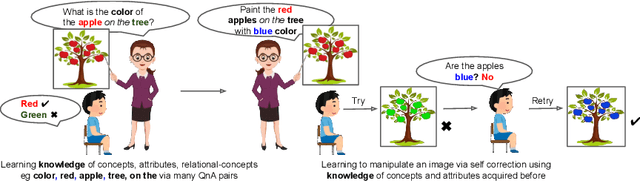
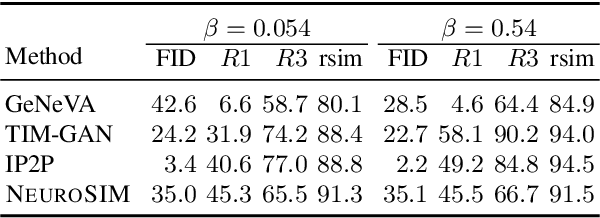
We are interested in image manipulation via natural language text -- a task that is useful for multiple AI applications but requires complex reasoning over multi-modal spaces. We extend recently proposed Neuro Symbolic Concept Learning (NSCL), which has been quite effective for the task of Visual Question Answering (VQA), for the task of image manipulation. Our system referred to as NeuroSIM can perform complex multi-hop reasoning over multi-object scenes and only requires weak supervision in the form of annotated data for VQA. NeuroSIM parses an instruction into a symbolic program, based on a Domain Specific Language (DSL) comprising of object attributes and manipulation operations, that guides its execution. We create a new dataset for the task, and extensive experiments demonstrate that NeuroSIM is highly competitive with or beats SOTA baselines that make use of supervised data for manipulation.
A Benchmark for Generalizable and Interpretable Temporal Question Answering over Knowledge Bases
Jan 15, 2022
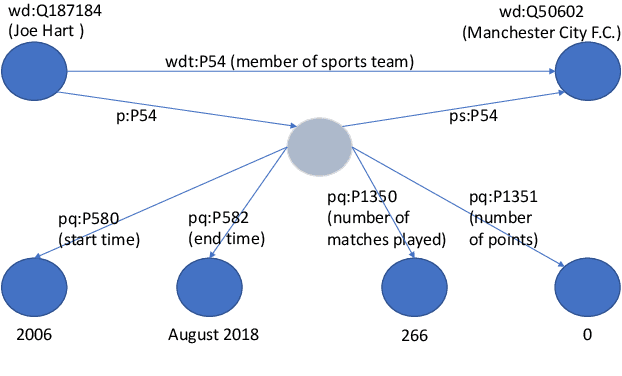


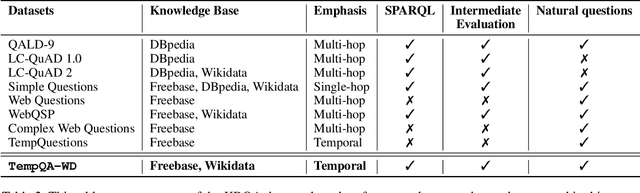
Knowledge Base Question Answering (KBQA) tasks that involve complex reasoning are emerging as an important research direction. However, most existing KBQA datasets focus primarily on generic multi-hop reasoning over explicit facts, largely ignoring other reasoning types such as temporal, spatial, and taxonomic reasoning. In this paper, we present a benchmark dataset for temporal reasoning, TempQA-WD, to encourage research in extending the present approaches to target a more challenging set of complex reasoning tasks. Specifically, our benchmark is a temporal question answering dataset with the following advantages: (a) it is based on Wikidata, which is the most frequently curated, openly available knowledge base, (b) it includes intermediate sparql queries to facilitate the evaluation of semantic parsing based approaches for KBQA, and (c) it generalizes to multiple knowledge bases: Freebase and Wikidata. The TempQA-WD dataset is available at https://github.com/IBM/tempqa-wd.
SYGMA: System for Generalizable Modular Question Answering OverKnowledge Bases
Sep 28, 2021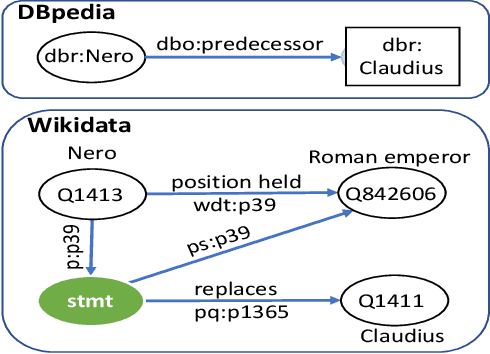


Knowledge Base Question Answering (KBQA) tasks that in-volve complex reasoning are emerging as an important re-search direction. However, most KBQA systems struggle withgeneralizability, particularly on two dimensions: (a) acrossmultiple reasoning types where both datasets and systems haveprimarily focused on multi-hop reasoning, and (b) across mul-tiple knowledge bases, where KBQA approaches are specif-ically tuned to a single knowledge base. In this paper, wepresent SYGMA, a modular approach facilitating general-izability across multiple knowledge bases and multiple rea-soning types. Specifically, SYGMA contains three high levelmodules: 1) KB-agnostic question understanding module thatis common across KBs 2) Rules to support additional reason-ing types and 3) KB-specific question mapping and answeringmodule to address the KB-specific aspects of the answer ex-traction. We demonstrate effectiveness of our system by evalu-ating on datasets belonging to two distinct knowledge bases,DBpedia and Wikidata. In addition, to demonstrate extensi-bility to additional reasoning types we evaluate on multi-hopreasoning datasets and a new Temporal KBQA benchmarkdataset on Wikidata, namedTempQA-WD1, introduced in thispaper. We show that our generalizable approach has bettercompetetive performance on multiple datasets on DBpediaand Wikidata that requires both multi-hop and temporal rea-soning
Knowledge Graph Question Answering via SPARQL Silhouette Generation
Sep 06, 2021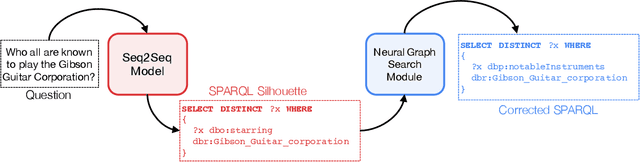
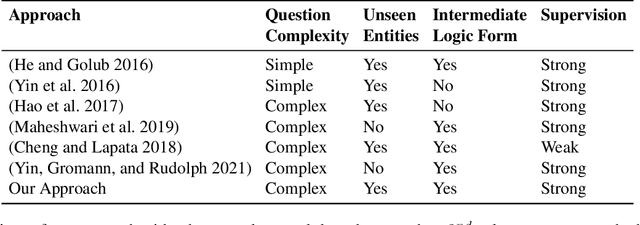
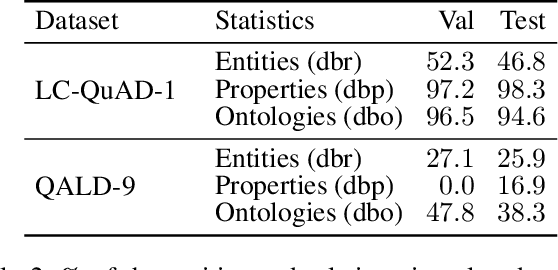
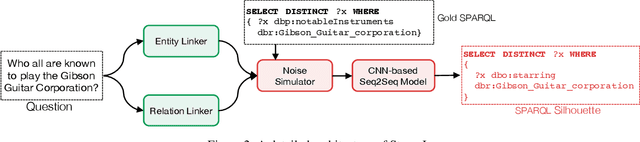
Knowledge Graph Question Answering (KGQA) has become a prominent area in natural language processing due to the emergence of large-scale Knowledge Graphs (KGs). Recently Neural Machine Translation based approaches are gaining momentum that translates natural language queries to structured query languages thereby solving the KGQA task. However, most of these methods struggle with out-of-vocabulary words where test entities and relations are not seen during training time. In this work, we propose a modular two-stage neural architecture to solve the KGQA task. The first stage generates a sketch of the target SPARQL called SPARQL silhouette for the input question. This comprises of (1) Noise simulator to facilitate out-of-vocabulary words and to reduce vocabulary size (2) seq2seq model for text to SPARQL silhouette generation. The second stage is a Neural Graph Search Module. SPARQL silhouette generated in the first stage is distilled in the second stage by substituting precise relation in the predicted structure. We simulate ideal and realistic scenarios by designing a noise simulator. Experimental results show that the quality of generated SPARQL silhouette in the first stage is outstanding for the ideal scenarios but for realistic scenarios (i.e. noisy linker), the quality of the resulting SPARQL silhouette drops drastically. However, our neural graph search module recovers it considerably. We show that our method can achieve reasonable performance improving the state-of-art by a margin of 3.72% F1 for the LC-QuAD-1 dataset. We believe, our proposed approach is novel and will lead to dynamic KGQA solutions that are suited for practical applications.
Question Answering over Knowledge Bases by Leveraging Semantic Parsing and Neuro-Symbolic Reasoning
Dec 03, 2020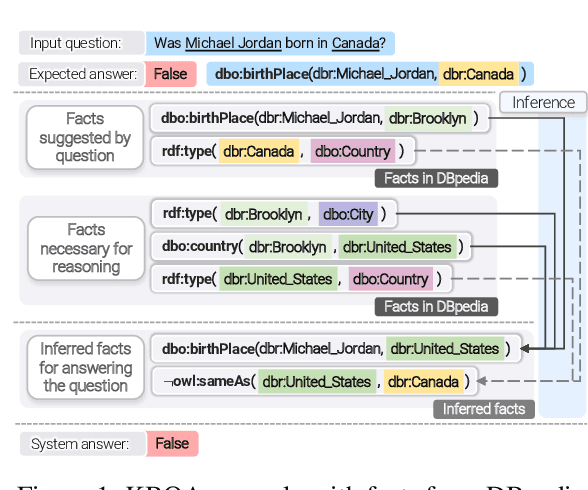
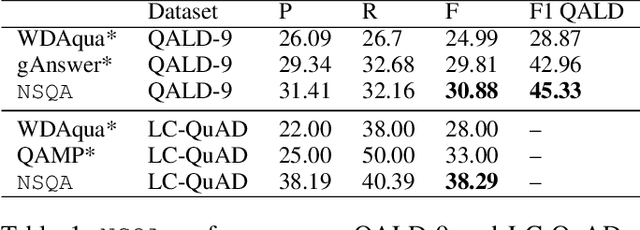
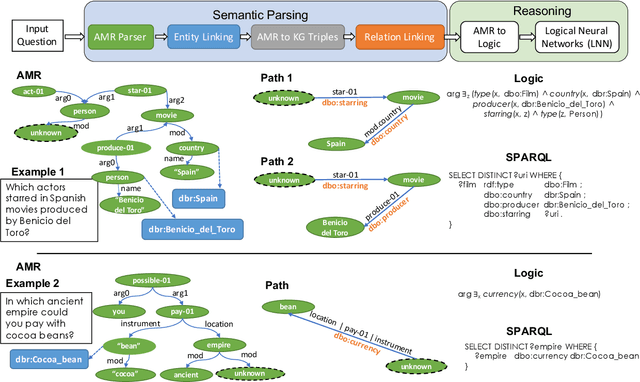

Knowledge base question answering (KBQA) is an important task in Natural Language Processing. Existing approaches face significant challenges including complex question understanding, necessity for reasoning, and lack of large training datasets. In this work, we propose a semantic parsing and reasoning-based Neuro-Symbolic Question Answering(NSQA) system, that leverages (1) Abstract Meaning Representation (AMR) parses for task-independent question under-standing; (2) a novel path-based approach to transform AMR parses into candidate logical queries that are aligned to the KB; (3) a neuro-symbolic reasoner called Logical Neural Net-work (LNN) that executes logical queries and reasons over KB facts to provide an answer; (4) system of systems approach,which integrates multiple, reusable modules that are trained specifically for their individual tasks (e.g. semantic parsing,entity linking, and relationship linking) and do not require end-to-end training data. NSQA achieves state-of-the-art performance on QALD-9 and LC-QuAD 1.0. NSQA's novelty lies in its modular neuro-symbolic architecture and its task-general approach to interpreting natural language questions.
The TechQA Dataset
Nov 08, 2019

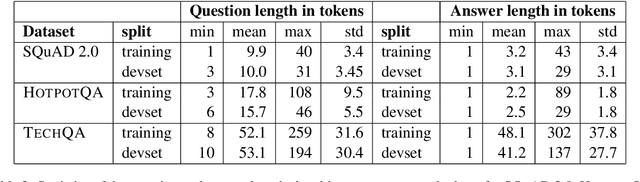
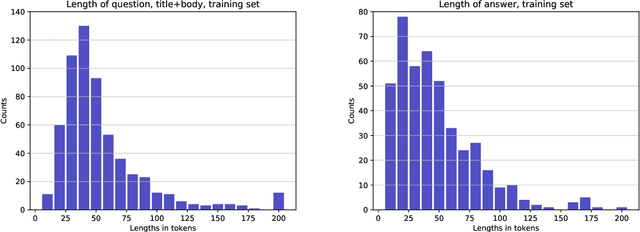
We introduce TechQA, a domain-adaptation question answering dataset for the technical support domain. The TechQA corpus highlights two real-world issues from the automated customer support domain. First, it contains actual questions posed by users on a technical forum, rather than questions generated specifically for a competition or a task. Second, it has a real-world size -- 600 training, 310 dev, and 490 evaluation question/answer pairs -- thus reflecting the cost of creating large labeled datasets with actual data. Consequently, TechQA is meant to stimulate research in domain adaptation rather than being a resource to build QA systems from scratch. The dataset was obtained by crawling the IBM Developer and IBM DeveloperWorks forums for questions with accepted answers that appear in a published IBM Technote---a technical document that addresses a specific technical issue. We also release a collection of the 801,998 publicly available Technotes as of April 4, 2019 as a companion resource that might be used for pretraining, to learn representations of the IT domain language.