 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSP: Self-Supervised Prompting for Cross-Lingual Transfer to Low-Resource Languages using Large Language Models
Jun 27, 2024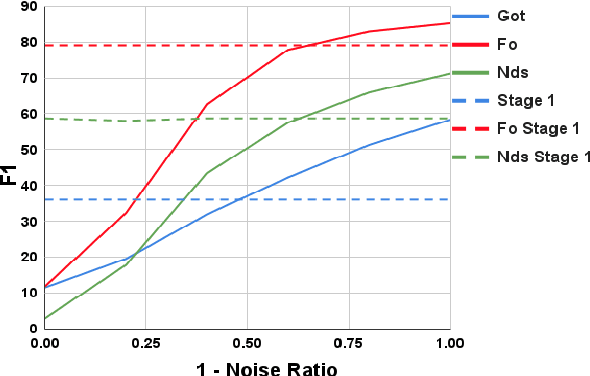
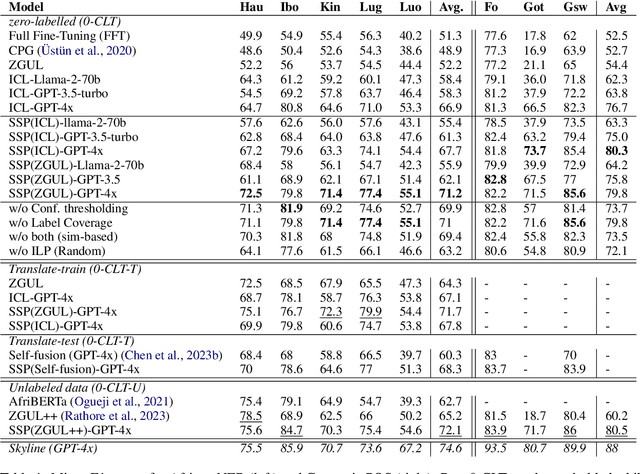
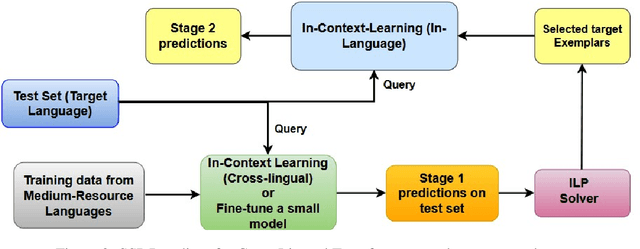
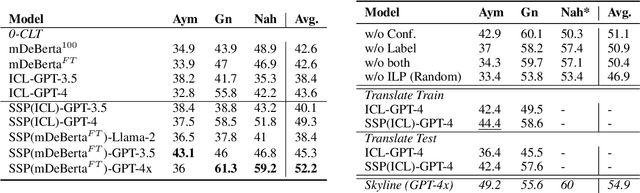
Recently, very large language models (LLMs) have shown exceptional performance on several English NLP tasks with just in-context learning (ICL), but their utility in other languages is still underexplored. We investigate their effectiveness for NLP tasks in low-resource languages (LRLs), especially in the setting of zero-labelled cross-lingual transfer (0-CLT), where no labelled training data for the target language is available -- however training data from one or more related medium-resource languages (MRLs) is utilized, alongside the available unlabeled test data for a target language. We introduce Self-Supervised Prompting (SSP), a novel ICL approach tailored for the 0-CLT setting. SSP is based on the key observation that LLMs output more accurate labels if in-context exemplars are from the target language (even if their labels are slightly noisy). To operationalize this, since target language training data is not available in 0-CLT, SSP operates in two stages. In Stage I, using source MRL training data, target language's test data is noisily labeled. In Stage II, these noisy test data points are used as exemplars in ICL for further improved labelling. Additionally, our implementation of SSP uses a novel Integer Linear Programming (ILP)-based exemplar selection that balances similarity, prediction confidence (when available) and label coverage. Experiments on three tasks and eleven LRLs (from three regions) demonstrate that SSP strongly outperforms existing SOTA fine-tuned and prompting-based baselines in 0-CLT setup.
Fill in the Blank: Exploring and Enhancing LLM Capabilities for Backward Reasoning in Math Word Problems
Oct 03, 2023

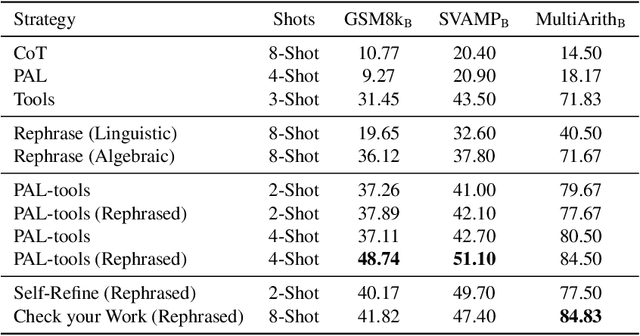

While forward reasoning (i.e. find the answer given the question) has been explored extensively in the recent literature, backward reasoning is relatively unexplored. We examine the backward reasoning capabilities of LLMs on Math Word Problems (MWPs): given a mathematical question and its answer, with some details omitted from the question, can LLMs effectively retrieve the missing information? In this paper, we formally define the backward reasoning task on math word problems and modify three datasets to evaluate this task: GSM8k, SVAMP and MultiArith. Our findings show a significant drop in the accuracy of models on backward reasoning compared to forward reasoning across four SOTA LLMs (GPT4, GPT3.5, PaLM-2, and LLaMa-2). Utilizing the specific format of this task, we propose three novel techniques that improve performance: Rephrase reformulates the given problem into a forward reasoning problem, PAL-Tools combines the idea of Program-Aided LLMs to produce a set of equations that can be solved by an external solver, and Check your Work exploits the availability of natural verifier of high accuracy in the forward direction, interleaving solving and verification steps. Finally, realizing that each of our base methods correctly solves a different set of problems, we propose a novel Bayesian formulation for creating an ensemble over these base methods aided by a verifier to further boost the accuracy by a significant margin. Extensive experimentation demonstrates that our techniques successively improve the performance of LLMs on the backward reasoning task, with the final ensemble-based method resulting in a substantial performance gain compared to the raw LLMs with standard prompting techniques such as chain-of-thought.