 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSP: Self-Supervised Prompting for Cross-Lingual Transfer to Low-Resource Languages using Large Language Models
Jun 27, 2024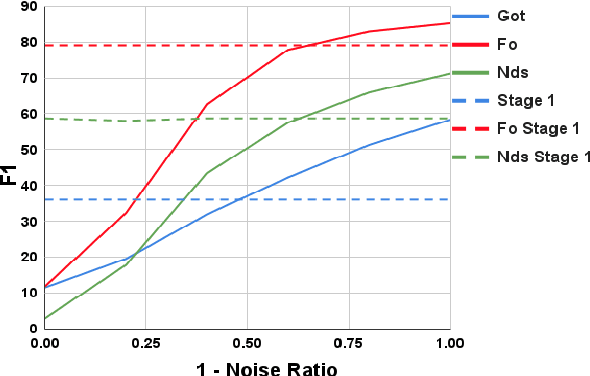
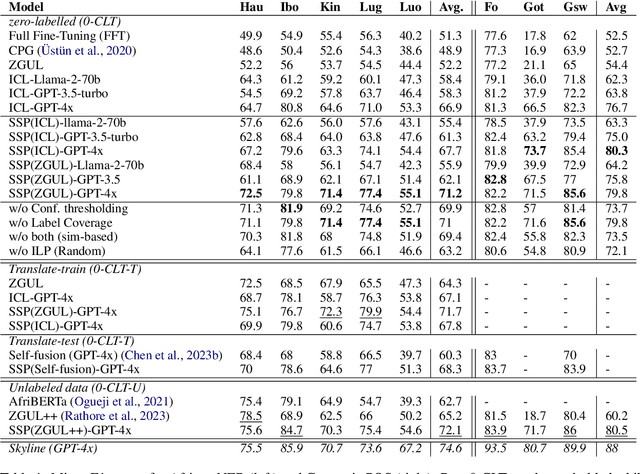
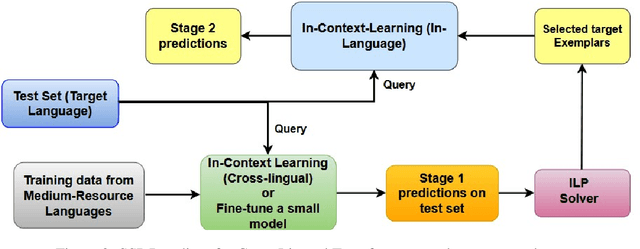
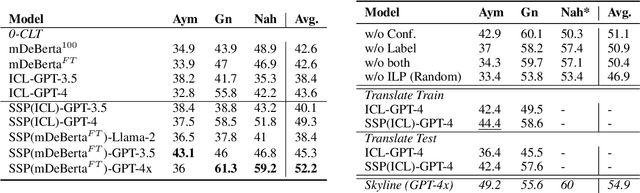
Recently, very large language models (LLMs) have shown exceptional performance on several English NLP tasks with just in-context learning (ICL), but their utility in other languages is still underexplored. We investigate their effectiveness for NLP tasks in low-resource languages (LRLs), especially in the setting of zero-labelled cross-lingual transfer (0-CLT), where no labelled training data for the target language is available -- however training data from one or more related medium-resource languages (MRLs) is utilized, alongside the available unlabeled test data for a target language. We introduce Self-Supervised Prompting (SSP), a novel ICL approach tailored for the 0-CLT setting. SSP is based on the key observation that LLMs output more accurate labels if in-context exemplars are from the target language (even if their labels are slightly noisy). To operationalize this, since target language training data is not available in 0-CLT, SSP operates in two stages. In Stage I, using source MRL training data, target language's test data is noisily labeled. In Stage II, these noisy test data points are used as exemplars in ICL for further improved labelling. Additionally, our implementation of SSP uses a novel Integer Linear Programming (ILP)-based exemplar selection that balances similarity, prediction confidence (when available) and label coverage. Experiments on three tasks and eleven LRLs (from three regions) demonstrate that SSP strongly outperforms existing SOTA fine-tuned and prompting-based baselines in 0-CLT setup.
ZGUL: Zero-shot Generalization to Unseen Languages using Multi-source Ensembling of Language Adapters
Oct 25, 2023



We tackle the problem of zero-shot cross-lingual transfer in NLP tasks via the use of language adapters (LAs). Most of the earlier works have explored training with adapter of a single source (often English), and testing either using the target LA or LA of another related language. Training target LA requires unlabeled data, which may not be readily available for low resource unseen languages: those that are neither seen by the underlying multilingual language model (e.g., mBERT), nor do we have any (labeled or unlabeled) data for them. We posit that for more effective cross-lingual transfer, instead of just one source LA, we need to leverage LAs of multiple (linguistically or geographically related) source languages, both at train and test-time - which we investigate via our novel neural architecture, ZGUL. Extensive experimentation across four language groups, covering 15 unseen target languages, demonstrates improvements of up to 3.2 average F1 points over standard fine-tuning and other strong baselines on POS tagging and NER tasks. We also extend ZGUL to settings where either (1) some unlabeled data or (2) few-shot training examples are available for the target language. We find that ZGUL continues to outperform baselines in these settings too.
Towards Fair and Calibrated Models
Oct 16, 2023Recent literature has seen a significant focus on building machine learning models with specific properties such as fairness, i.e., being non-biased with respect to a given set of attributes, calibration i.e., model confidence being aligned with its predictive accuracy, and explainability, i.e., ability to be understandable to humans. While there has been work focusing on each of these aspects individually, researchers have shied away from simultaneously addressing more than one of these dimensions. In this work, we address the problem of building models which are both fair and calibrated. We work with a specific definition of fairness, which closely matches [Biswas et. al. 2019], and has the nice property that Bayes optimal classifier has the maximum possible fairness under our definition. We show that an existing negative result towards achieving a fair and calibrated model [Kleinberg et. al. 2017] does not hold for our definition of fairness. Further, we show that ensuring group-wise calibration with respect to the sensitive attributes automatically results in a fair model under our definition. Using this result, we provide a first cut approach for achieving fair and calibrated models, via a simple post-processing technique based on temperature scaling. We then propose modifications of existing calibration losses to perform group-wise calibration, as a way of achieving fair and calibrated models in a variety of settings. Finally, we perform extensive experimentation of these techniques on a diverse benchmark of datasets, and present insights on the pareto-optimality of the resulting solutions.
A Simple, Strong and Robust Baseline for Distantly Supervised Relation Extraction
Oct 14, 2021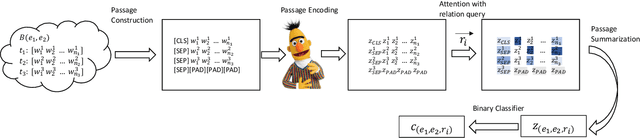
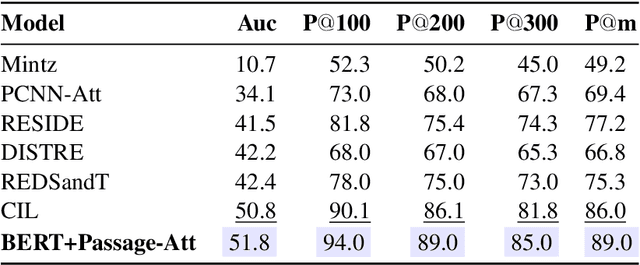
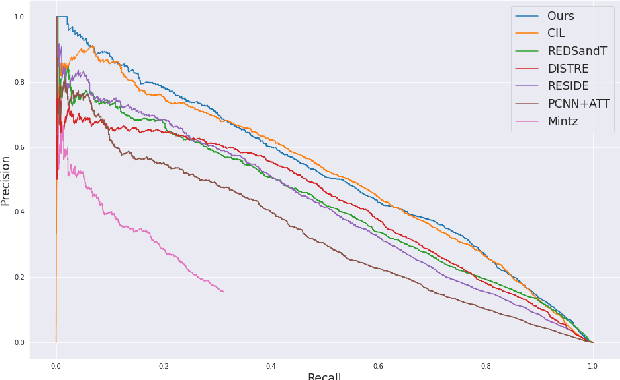
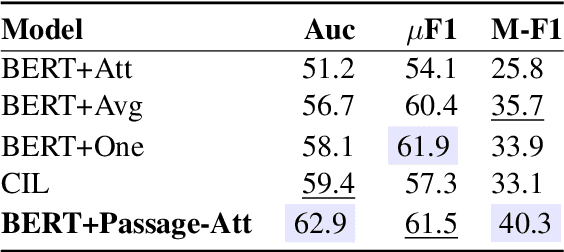
Distantly supervised relation extraction (DS-RE) is generally framed as a multi-instance multi-label (MI-ML) task, where the optimal aggregation of information from multiple instances is of key importance. Intra-bag attention (Lin et al., 2016) is an example of a popularly used aggregation scheme for this framework. Apart from this scheme, however, there is not much to choose from in the DS-RE literature as most of the advances in this field are focused on improving the instance-encoding step rather than the instance-aggregation step. With recent works leveraging large pre-trained language models as encoders, the increased capacity of models might allow for more flexibility in the instance-aggregation step. In this work, we explore this hypothesis and come up with a novel aggregation scheme which we call Passage-Att. Under this aggregation scheme, we combine all instances mentioning an entity pair into a "passage of instances", which is summarized independently for each relation class. These summaries are used to predict the validity of a potential triple. We show that our Passage-Att with BERT as passage encoder achieves state-of-the-art performance in three different settings (monolingual DS, monolingual DS with manually-annotated test set, multilingual DS).
IMoJIE: Iterative Memory-Based Joint Open Information Extraction
May 17, 2020
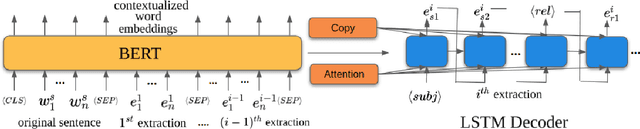


While traditional systems for Open Information Extraction were statistical and rule-based, recently neural models have been introduced for the task. Our work builds upon CopyAttention, a sequence generation OpenIE model (Cui et. al., 2018). Our analysis reveals that CopyAttention produces a constant number of extractions per sentence, and its extracted tuples often express redundant information. We present IMoJIE, an extension to CopyAttention, which produces the next extraction conditioned on all previously extracted tuples. This approach overcomes both shortcomings of CopyAttention, resulting in a variable number of diverse extractions per sentence. We train IMoJIE on training data bootstrapped from extractions of several non-neural systems, which have been automatically filtered to reduce redundancy and noise. IMoJIE outperforms CopyAttention by about 18 F1 pts, and a BERT-based strong baseline by 2 F1 pts, establishing a new state of the art for the task.