 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Turn Puzzles: Evaluating Interactive Reasoning and Strategic Dialogue in LLMs
Aug 13, 2025Large language models (LLMs) excel at solving problems with clear and complete statements, but often struggle with nuanced environments or interactive tasks which are common in most real-world scenarios. This highlights the critical need for developing LLMs that can effectively engage in logically consistent multi-turn dialogue, seek information and reason with incomplete data. To this end, we introduce a novel benchmark comprising a suite of multi-turn tasks each designed to test specific reasoning, interactive dialogue, and information-seeking abilities. These tasks have deterministic scoring mechanisms, thus eliminating the need for human intervention. Evaluating frontier models on our benchmark reveals significant headroom. Our analysis shows that most errors emerge from poor instruction following, reasoning failures, and poor planning. This benchmark provides valuable insights into the strengths and weaknesses of current LLMs in handling complex, interactive scenarios and offers a robust platform for future research aimed at improving these critical capabilities.
Proactive Agents for Multi-Turn Text-to-Image Generation Under Uncertainty
Dec 09, 2024User prompts for generative AI models are often underspecified, leading to sub-optimal responses. This problem is particularly evident in text-to-image (T2I) generation, where users commonly struggle to articulate their precise intent. This disconnect between the user's vision and the model's interpretation often forces users to painstakingly and repeatedly refine their prompts. To address this, we propose a design for proactive T2I agents equipped with an interface to (1) actively ask clarification questions when uncertain, and (2) present their understanding of user intent as an understandable belief graph that a user can edit. We build simple prototypes for such agents and verify their effectiveness through both human studies and automated evaluation. We observed that at least 90% of human subjects found these agents and their belief graphs helpful for their T2I workflow. Moreover, we develop a scalable automated evaluation approach using two agents, one with a ground truth image and the other tries to ask as few questions as possible to align with the ground truth. On DesignBench, a benchmark we created for artists and designers, the COCO dataset (Lin et al., 2014), and ImageInWords (Garg et al., 2024), we observed that these T2I agents were able to ask informative questions and elicit crucial information to achieve successful alignment with at least 2 times higher VQAScore (Lin et al., 2024) than the standard single-turn T2I generation. Demo: https://github.com/google-deepmind/proactive_t2i_agents.
Gemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Parameter-Efficient Finetuning for Robust Continual Multilingual Learning
Sep 14, 2022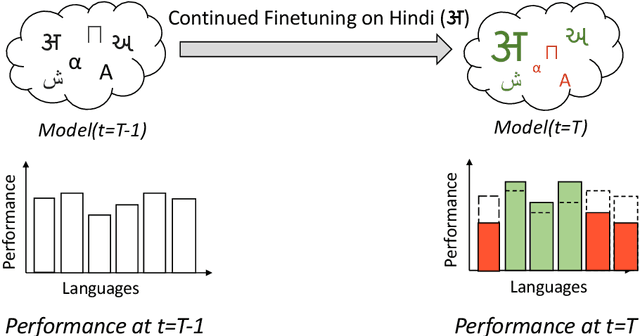

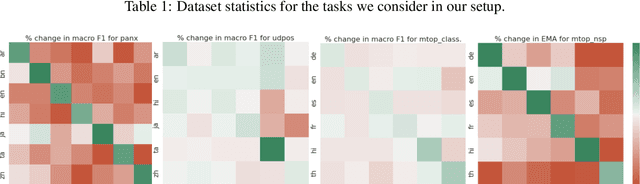
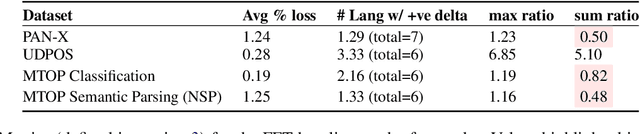
NLU systems deployed in the real world are expected to be regularly updated by retraining or finetuning the underlying neural network on new training examples accumulated over time. In our work, we focus on the multilingual setting where we would want to further finetune a multilingual model on new training data for the same NLU task on which the aforementioned model has already been trained for. We show that under certain conditions, naively updating the multilingual model can lead to losses in performance over a subset of languages although the aggregated performance metric shows an improvement. We establish this phenomenon over four tasks belonging to three task families (token-level, sentence-level and seq2seq) and find that the baseline is far from ideal for the setting at hand. We then build upon recent advances in parameter-efficient finetuning to develop novel finetuning pipelines that allow us to jointly minimize catastrophic forgetting while encouraging positive cross-lingual transfer, hence improving the spread of gains over different languages while reducing the losses incurred in this setup.
A Simple, Strong and Robust Baseline for Distantly Supervised Relation Extraction
Oct 14, 2021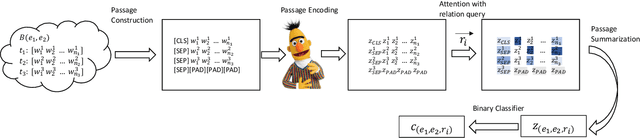
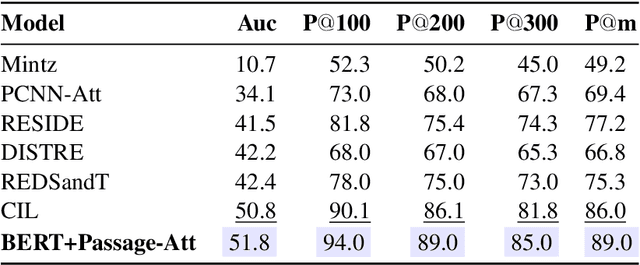
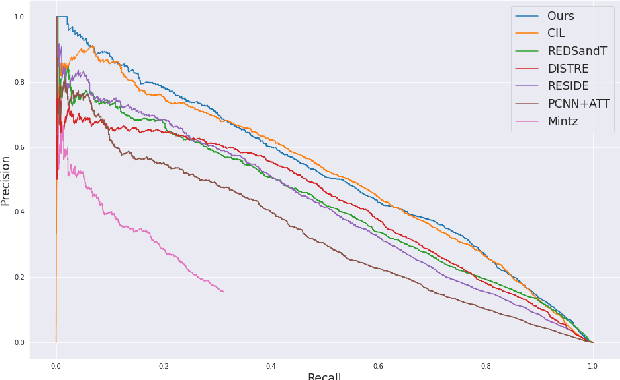
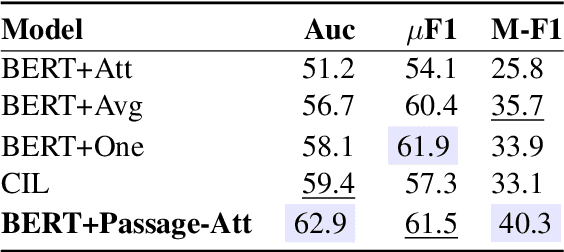
Distantly supervised relation extraction (DS-RE) is generally framed as a multi-instance multi-label (MI-ML) task, where the optimal aggregation of information from multiple instances is of key importance. Intra-bag attention (Lin et al., 2016) is an example of a popularly used aggregation scheme for this framework. Apart from this scheme, however, there is not much to choose from in the DS-RE literature as most of the advances in this field are focused on improving the instance-encoding step rather than the instance-aggregation step. With recent works leveraging large pre-trained language models as encoders, the increased capacity of models might allow for more flexibility in the instance-aggregation step. In this work, we explore this hypothesis and come up with a novel aggregation scheme which we call Passage-Att. Under this aggregation scheme, we combine all instances mentioning an entity pair into a "passage of instances", which is summarized independently for each relation class. These summaries are used to predict the validity of a potential triple. We show that our Passage-Att with BERT as passage encoder achieves state-of-the-art performance in three different settings (monolingual DS, monolingual DS with manually-annotated test set, multilingual DS).
DiS-ReX: A Multilingual Dataset for Distantly Supervised Relation Extraction
Apr 17, 2021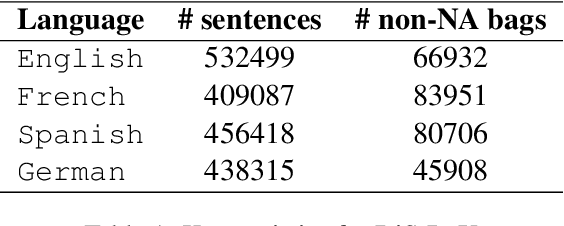
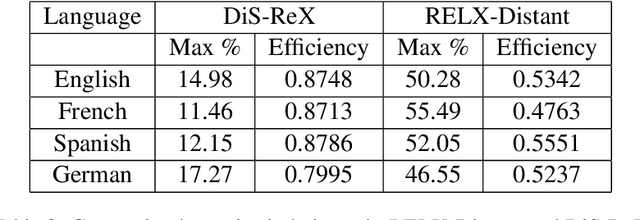
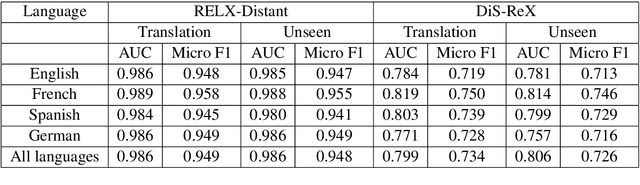
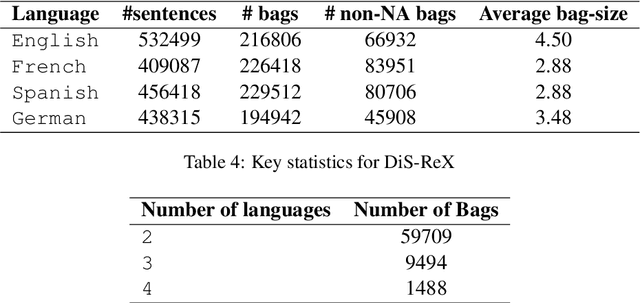
Distant supervision (DS) is a well established technique for creating large-scale datasets for relation extraction (RE) without using human annotations. However, research in DS-RE has been mostly limited to the English language. Constraining RE to a single language inhibits utilization of large amounts of data in other languages which could allow extraction of more diverse facts. Very recently, a dataset for multilingual DS-RE has been released. However, our analysis reveals that the proposed dataset exhibits unrealistic characteristics such as 1) lack of sentences that do not express any relation, and 2) all sentences for a given entity pair expressing exactly one relation. We show that these characteristics lead to a gross overestimation of the model performance. In response, we propose a new dataset, DiS-ReX, which alleviates these issues. Our dataset has more than 1.5 million sentences, spanning across 4 languages with 36 relation classes + 1 no relation (NA) class. We also modify the widely used bag attention models by encoding sentences using mBERT and provide the first benchmark results on multilingual DS-RE. Unlike the competing dataset, we show that our dataset is challenging and leaves enough room for future research to take place in this field.
Coordination Among Neural Modules Through a Shared Global Workspace
Mar 01, 2021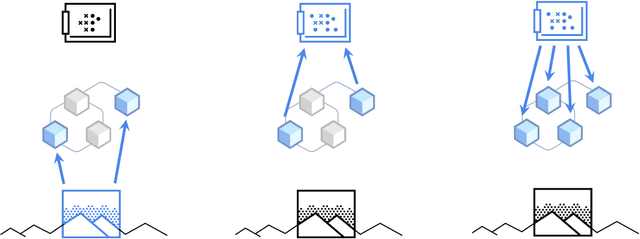
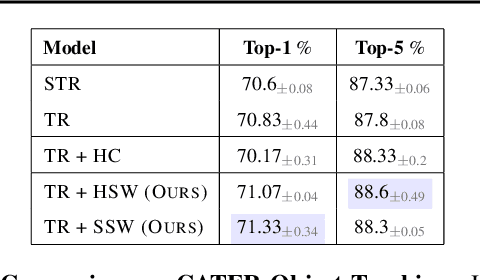
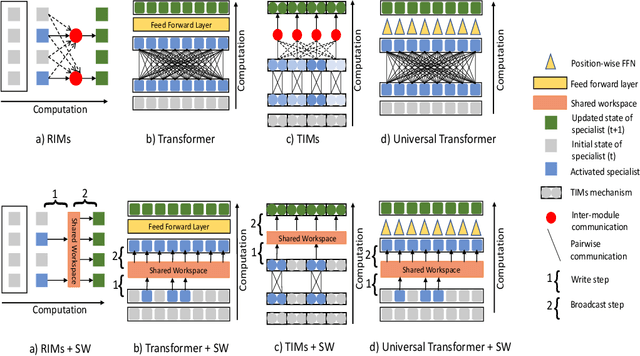
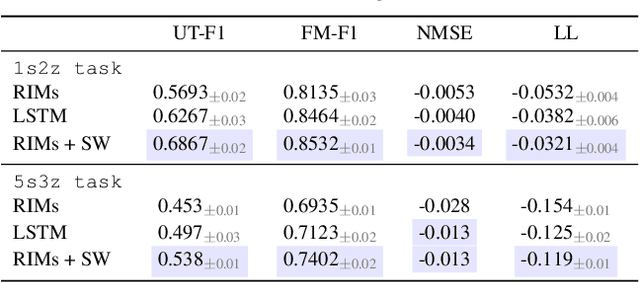
Deep learning has seen a movement away from representing examples with a monolithic hidden state towards a richly structured state. For example, Transformers segment by position, and object-centric architectures decompose images into entities. In all these architectures, interactions between different elements are modeled via pairwise interactions: Transformers make use of self-attention to incorporate information from other positions; object-centric architectures make use of graph neural networks to model interactions among entities. However, pairwise interactions may not achieve global coordination or a coherent, integrated representation that can be used for downstream tasks. In cognitive science, a global workspace architecture has been proposed in which functionally specialized components share information through a common, bandwidth-limited communication channel. We explore the use of such a communication channel in the context of deep learning for modeling the structure of complex environments. The proposed method includes a shared workspace through which communication among different specialist modules takes place but due to limits on the communication bandwidth, specialist modules must compete for access. We show that capacity limitations have a rational basis in that (1) they encourage specialization and compositionality and (2) they facilitate the synchronization of otherwise independent specialists.
Twin Augmented Architectures for Robust Classification of COVID-19 Chest X-Ray Images
Feb 16, 2021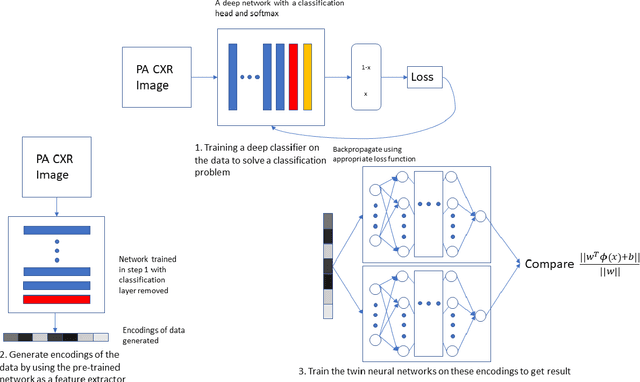
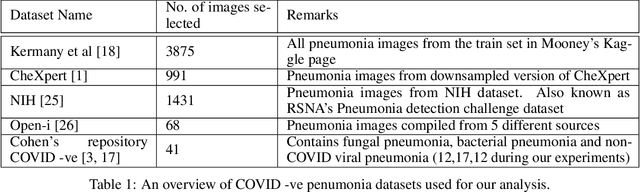
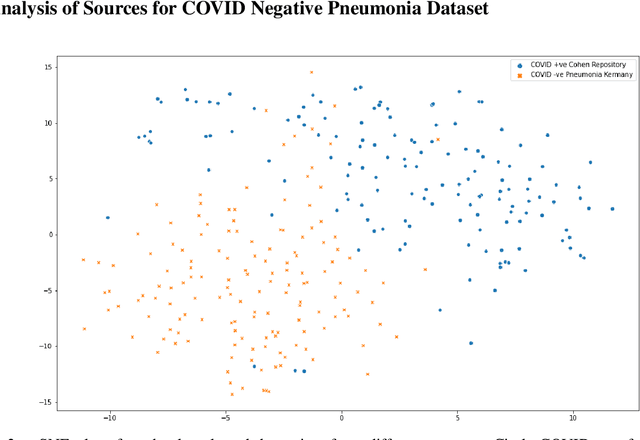
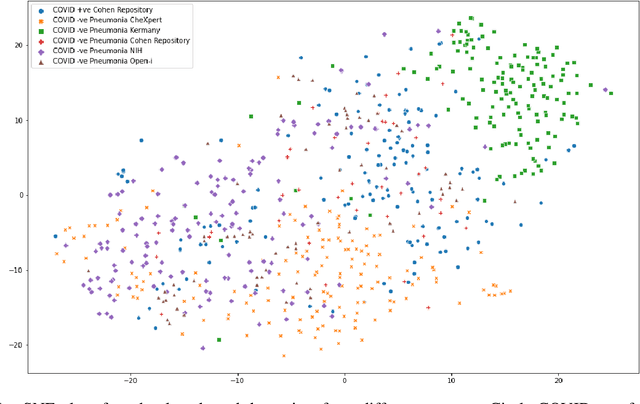
The gold standard for COVID-19 is RT-PCR, testing facilities for which are limited and not always optimally distributed. Test results are delayed, which impacts treatment. Expert radiologists, one of whom is a co-author, are able to diagnose COVID-19 positivity from Chest X-Rays (CXR) and CT scans, that can facilitate timely treatment. Such diagnosis is particularly valuable in locations lacking radiologists with sufficient expertise and familiarity with COVID-19 patients. This paper has two contributions. One, we analyse literature on CXR based COVID-19 diagnosis. We show that popular choices of dataset selection suffer from data homogeneity, leading to misleading results. We compile and analyse a viable benchmark dataset from multiple existing heterogeneous sources. Such a benchmark is important for realistically testing models. Our second contribution relates to learning from imbalanced data. Datasets for COVID X-Ray classification face severe class imbalance, since most subjects are COVID -ve. Twin Support Vector Machines (Twin SVM) and Twin Neural Networks (Twin NN) have, in recent years, emerged as effective ways of handling skewed data. We introduce a state-of-the-art technique, termed as Twin Augmentation, for modifying popular pre-trained deep learning models. Twin Augmentation boosts the performance of a pre-trained deep neural network without requiring re-training. Experiments show, that across a multitude of classifiers, Twin Augmentation is very effective in boosting the performance of given pre-trained model for classification in imbalanced settings.