 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCURVE: A Benchmark for Cultural and Multilingual Long Video Reasoning
Jan 15, 2026Recent advancements in video models have shown tremendous progress, particularly in long video understanding. However, current benchmarks predominantly feature western-centric data and English as the dominant language, introducing significant biases in evaluation. To address this, we introduce CURVE (Cultural Understanding and Reasoning in Video Evaluation), a challenging benchmark for multicultural and multilingual video reasoning. CURVE comprises high-quality, entirely human-generated annotations from diverse, region-specific cultural videos across 18 global locales. Unlike prior work that relies on automatic translations, CURVE provides complex questions, answers, and multi-step reasoning steps, all crafted in native languages. Making progress on CURVE requires a deeply situated understanding of visual cultural context. Furthermore, we leverage CURVE's reasoning traces to construct evidence-based graphs and propose a novel iterative strategy using these graphs to identify fine-grained errors in reasoning. Our evaluations reveal that SoTA Video-LLMs struggle significantly, performing substantially below human-level accuracy, with errors primarily stemming from the visual perception of cultural elements. CURVE will be publicly available under https://github.com/google-deepmind/neptune?tab=readme-ov-file\#minerva-cultural
Beyond Aesthetics: Cultural Competence in Text-to-Image Models
Jul 11, 2024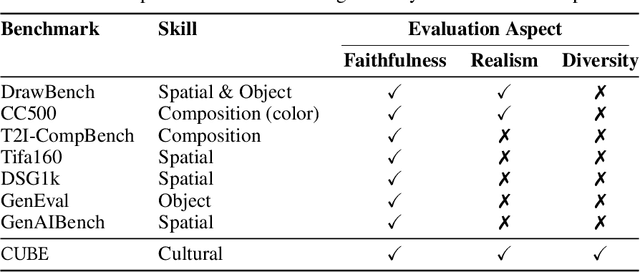
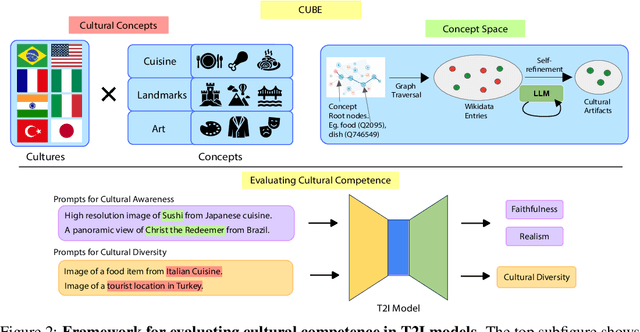


Text-to-Image (T2I) models are being increasingly adopted in diverse global communities where they create visual representations of their unique cultures. Current T2I benchmarks primarily focus on faithfulness, aesthetics, and realism of generated images, overlooking the critical dimension of cultural competence. In this work, we introduce a framework to evaluate cultural competence of T2I models along two crucial dimensions: cultural awareness and cultural diversity, and present a scalable approach using a combination of structured knowledge bases and large language models to build a large dataset of cultural artifacts to enable this evaluation. In particular, we apply this approach to build CUBE (CUltural BEnchmark for Text-to-Image models), a first-of-its-kind benchmark to evaluate cultural competence of T2I models. CUBE covers cultural artifacts associated with 8 countries across different geo-cultural regions and along 3 concepts: cuisine, landmarks, and art. CUBE consists of 1) CUBE-1K, a set of high-quality prompts that enable the evaluation of cultural awareness, and 2) CUBE-CSpace, a larger dataset of cultural artifacts that serves as grounding to evaluate cultural diversity. We also introduce cultural diversity as a novel T2I evaluation component, leveraging quality-weighted Vendi score. Our evaluations reveal significant gaps in the cultural awareness of existing models across countries and provide valuable insights into the cultural diversity of T2I outputs for under-specified prompts. Our methodology is extendable to other cultural regions and concepts, and can facilitate the development of T2I models that better cater to the global population.
GeniL: A Multilingual Dataset on Generalizing Language
Apr 08, 2024



LLMs are increasingly transforming our digital ecosystem, but they often inherit societal biases learned from their training data, for instance stereotypes associating certain attributes with specific identity groups. While whether and how these biases are mitigated may depend on the specific use cases, being able to effectively detect instances of stereotype perpetuation is a crucial first step. Current methods to assess presence of stereotypes in generated language rely on simple template or co-occurrence based measures, without accounting for the variety of sentential contexts they manifest in. We argue that understanding the sentential context is crucial for detecting instances of generalization. We distinguish two types of generalizations: (1) language that merely mentions the presence of a generalization ("people think the French are very rude"), and (2) language that reinforces such a generalization ("as French they must be rude"), from non-generalizing context ("My French friends think I am rude"). For meaningful stereotype evaluations, we need to reliably distinguish such instances of generalizations. We introduce the new task of detecting generalization in language, and build GeniL, a multilingual dataset of over 50K sentences from 9 languages (English, Arabic, Bengali, Spanish, French, Hindi, Indonesian, Malay, and Portuguese) annotated for instances of generalizations. We demonstrate that the likelihood of a co-occurrence being an instance of generalization is usually low, and varies across different languages, identity groups, and attributes. We build classifiers to detect generalization in language with an overall PR-AUC of 58.7, with varying degrees of performance across languages. Our research provides data and tools to enable a nuanced understanding of stereotype perpetuation, a crucial step towards more inclusive and responsible language technologies.
SeeGULL Multilingual: a Dataset of Geo-Culturally Situated Stereotypes
Mar 08, 2024



While generative multilingual models are rapidly being deployed, their safety and fairness evaluations are largely limited to resources collected in English. This is especially problematic for evaluations targeting inherently socio-cultural phenomena such as stereotyping, where it is important to build multi-lingual resources that reflect the stereotypes prevalent in respective language communities. However, gathering these resources, at scale, in varied languages and regions pose a significant challenge as it requires broad socio-cultural knowledge and can also be prohibitively expensive. To overcome this critical gap, we employ a recently introduced approach that couples LLM generations for scale with culturally situated validations for reliability, and build SeeGULL Multilingual, a global-scale multilingual dataset of social stereotypes, containing over 25K stereotypes, spanning 20 languages, with human annotations across 23 regions, and demonstrate its utility in identifying gaps in model evaluations. Content warning: Stereotypes shared in this paper can be offensive.
Beyond the Surface: A Global-Scale Analysis of Visual Stereotypes in Text-to-Image Generation
Jan 12, 2024



Recent studies have highlighted the issue of stereotypical depictions for people of different identity groups in Text-to-Image (T2I) model generations. However, these existing approaches have several key limitations, including a noticeable lack of coverage of global identity groups in their evaluation, and the range of their associated stereotypes. Additionally, they often lack a critical distinction between inherently visual stereotypes, such as `underweight' or `sombrero', and culturally dependent stereotypes like `attractive' or `terrorist'. In this work, we address these limitations with a multifaceted approach that leverages existing textual resources to ground our evaluation of geo-cultural stereotypes in the generated images from T2I models. We employ existing stereotype benchmarks to identify and evaluate visual stereotypes at a global scale, spanning 135 nationality-based identity groups. We demonstrate that stereotypical attributes are thrice as likely to be present in images of these identities as compared to other attributes. We further investigate how disparately offensive the depictions of generated images are for different nationalities. Finally, through a detailed case study, we reveal how the 'default' representations of all identity groups have a stereotypical appearance. Moreover, for the Global South, images across different attributes are visually similar, even when explicitly prompted otherwise. CONTENT WARNING: Some examples may contain offensive stereotypes.
Building Socio-culturally Inclusive Stereotype Resources with Community Engagement
Jul 20, 2023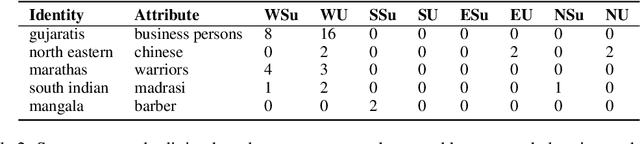



With rapid development and deployment of generative language models in global settings, there is an urgent need to also scale our measurements of harm, not just in the number and types of harms covered, but also how well they account for local cultural contexts, including marginalized identities and the social biases experienced by them. Current evaluation paradigms are limited in their abilities to address this, as they are not representative of diverse, locally situated but global, socio-cultural perspectives. It is imperative that our evaluation resources are enhanced and calibrated by including people and experiences from different cultures and societies worldwide, in order to prevent gross underestimations or skews in measurements of harm. In this work, we demonstrate a socio-culturally aware expansion of evaluation resources in the Indian societal context, specifically for the harm of stereotyping. We devise a community engaged effort to build a resource which contains stereotypes for axes of disparity that are uniquely present in India. The resultant resource increases the number of stereotypes known for and in the Indian context by over 1000 stereotypes across many unique identities. We also demonstrate the utility and effectiveness of such expanded resources for evaluations of language models. CONTENT WARNING: This paper contains examples of stereotypes that may be offensive.
SeeGULL: A Stereotype Benchmark with Broad Geo-Cultural Coverage Leveraging Generative Models
May 19, 2023Stereotype benchmark datasets are crucial to detect and mitigate social stereotypes about groups of people in NLP models. However, existing datasets are limited in size and coverage, and are largely restricted to stereotypes prevalent in the Western society. This is especially problematic as language technologies gain hold across the globe. To address this gap, we present SeeGULL, a broad-coverage stereotype dataset, built by utilizing generative capabilities of large language models such as PaLM, and GPT-3, and leveraging a globally diverse rater pool to validate the prevalence of those stereotypes in society. SeeGULL is in English, and contains stereotypes about identity groups spanning 178 countries across 8 different geo-political regions across 6 continents, as well as state-level identities within the US and India. We also include fine-grained offensiveness scores for different stereotypes and demonstrate their global disparities. Furthermore, we include comparative annotations about the same groups by annotators living in the region vs. those that are based in North America, and demonstrate that within-region stereotypes about groups differ from those prevalent in North America. CONTENT WARNING: This paper contains stereotype examples that may be offensive.
PaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Cultural Re-contextualization of Fairness Research in Language Technologies in India
Nov 21, 2022

Recent research has revealed undesirable biases in NLP data and models. However, these efforts largely focus on social disparities in the West, and are not directly portable to other geo-cultural contexts. In this position paper, we outline a holistic research agenda to re-contextualize NLP fairness research for the Indian context, accounting for Indian societal context, bridging technological gaps in capability and resources, and adapting to Indian cultural values. We also summarize findings from an empirical study on various social biases along different axes of disparities relevant to India, demonstrating their prevalence in corpora and models.
Bootstrapping Multilingual Semantic Parsers using Large Language Models
Oct 13, 2022
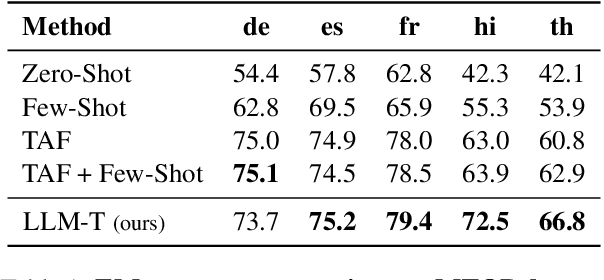

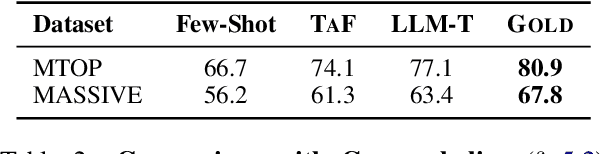
Despite cross-lingual generalization demonstrated by pre-trained multilingual models, the translate-train paradigm of transferring English datasets across multiple languages remains to be the key ingredient for training task-specific multilingual models. However, for many low-resource languages, the availability of a reliable translation service entails significant amounts of costly human-annotated translation pairs. Further, the translation services for low-resource languages may continue to be brittle due to domain mismatch between the task-specific input text and the general-purpose text used while training the translation models. We consider the task of multilingual semantic parsing and demonstrate the effectiveness and flexibility offered by large language models (LLMs) for translating English datasets into several languages via few-shot prompting. We provide (i) Extensive comparisons with prior translate-train methods across 50 languages demonstrating that LLMs can serve as highly effective data translators, outperforming prior translation based methods on 40 out of 50 languages; (ii) A comprehensive study of the key design choices that enable effective data translation via prompted LLMs.