 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVendi Novelty Scores for Out-of-Distribution Detection
Feb 10, 2026Out-of-distribution (OOD) detection is critical for the safe deployment of machine learning systems. Existing post-hoc detectors typically rely on model confidence scores or likelihood estimates in feature space, often under restrictive distributional assumptions. In this work, we introduce a third paradigm and formulate OOD detection from a diversity perspective. We propose the Vendi Novelty Score (VNS), an OOD detector based on the Vendi Scores (VS), a family of similarity-based diversity metrics. VNS quantifies how much a test sample increases the VS of the in-distribution feature set, providing a principled notion of novelty that does not require density modeling. VNS is linear-time, non-parametric, and naturally combines class-conditional (local) and dataset-level (global) novelty signals. Across multiple image classification benchmarks and network architectures, VNS achieves state-of-the-art OOD detection performance. Remarkably, VNS retains this performance when computed using only 1% of the training data, enabling deployment in memory- or access-constrained settings.
Alternators With Noise Models
May 18, 2025Alternators have recently been introduced as a framework for modeling time-dependent data. They often outperform other popular frameworks, such as state-space models and diffusion models, on challenging time-series tasks. This paper introduces a new Alternator model, called Alternator++, which enhances the flexibility of traditional Alternators by explicitly modeling the noise terms used to sample the latent and observed trajectories, drawing on the idea of noise models from the diffusion modeling literature. Alternator++ optimizes the sum of the Alternator loss and a noise-matching loss. The latter forces the noise trajectories generated by the two noise models to approximate the noise trajectories that produce the observed and latent trajectories. We demonstrate the effectiveness of Alternator++ in tasks such as density estimation, time series imputation, and forecasting, showing that it outperforms several strong baselines, including Mambas, ScoreGrad, and Dyffusion.
Building Machine Learning Challenges for Anomaly Detection in Science
Mar 03, 2025



Scientific discoveries are often made by finding a pattern or object that was not predicted by the known rules of science. Oftentimes, these anomalous events or objects that do not conform to the norms are an indication that the rules of science governing the data are incomplete, and something new needs to be present to explain these unexpected outliers. The challenge of finding anomalies can be confounding since it requires codifying a complete knowledge of the known scientific behaviors and then projecting these known behaviors on the data to look for deviations. When utilizing machine learning, this presents a particular challenge since we require that the model not only understands scientific data perfectly but also recognizes when the data is inconsistent and out of the scope of its trained behavior. In this paper, we present three datasets aimed at developing machine learning-based anomaly detection for disparate scientific domains covering astrophysics, genomics, and polar science. We present the different datasets along with a scheme to make machine learning challenges around the three datasets findable, accessible, interoperable, and reusable (FAIR). Furthermore, we present an approach that generalizes to future machine learning challenges, enabling the possibility of large, more compute-intensive challenges that can ultimately lead to scientific discovery.
The $α$-Alternator: Dynamic Adaptation To Varying Noise Levels In Sequences Using The Vendi Score For Improved Robustness and Performance
Feb 07, 2025



Current state-of-the-art dynamical models, such as Mamba, assume the same level of noisiness for all elements of a given sequence, which limits their performance on noisy temporal data. In this paper, we introduce the $\alpha$-Alternator, a novel generative model for time-dependent data that dynamically adapts to the complexity introduced by varying noise levels in sequences. The $\alpha$-Alternator leverages the Vendi Score (VS), a flexible similarity-based diversity metric, to adjust, at each time step $t$, the influence of the sequence element at time $t$ and the latent representation of the dynamics up to that time step on the predicted future dynamics. This influence is captured by a parameter that is learned and shared across all sequences in a given dataset. The sign of this parameter determines the direction of influence. A negative value indicates a noisy dataset, where a sequence element that increases the VS is considered noisy, and the model relies more on the latent history when processing that element. Conversely, when the parameter is positive, a sequence element that increases the VS is considered informative, and the $\alpha$-Alternator relies more on this new input than on the latent history when updating its predicted latent dynamics. The $\alpha$-Alternator is trained using a combination of observation masking and Alternator loss minimization. Masking simulates varying noise levels in sequences, enabling the model to be more robust to these fluctuations and improving its performance in trajectory prediction, imputation, and forecasting. Our experimental results demonstrate that the $\alpha$-Alternator outperforms both Alternators and state-of-the-art state-space models across neural decoding and time-series forecasting benchmarks.
LLM4Mat-Bench: Benchmarking Large Language Models for Materials Property Prediction
Oct 31, 2024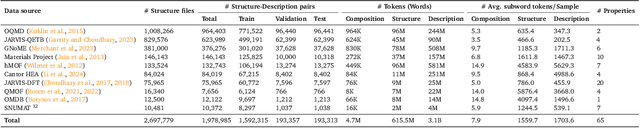
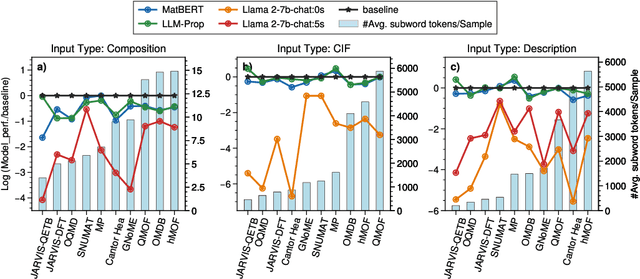

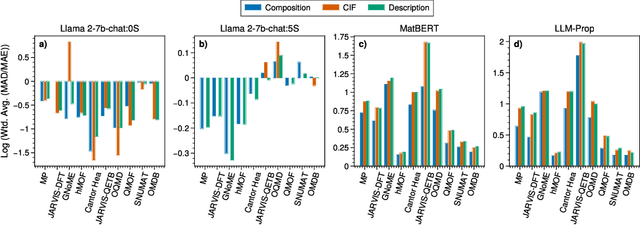
Large language models (LLMs) are increasingly being used in materials science. However, little attention has been given to benchmarking and standardized evaluation for LLM-based materials property prediction, which hinders progress. We present LLM4Mat-Bench, the largest benchmark to date for evaluating the performance of LLMs in predicting the properties of crystalline materials. LLM4Mat-Bench contains about 1.9M crystal structures in total, collected from 10 publicly available materials data sources, and 45 distinct properties. LLM4Mat-Bench features different input modalities: crystal composition, CIF, and crystal text description, with 4.7M, 615.5M, and 3.1B tokens in total for each modality, respectively. We use LLM4Mat-Bench to fine-tune models with different sizes, including LLM-Prop and MatBERT, and provide zero-shot and few-shot prompts to evaluate the property prediction capabilities of LLM-chat-like models, including Llama, Gemma, and Mistral. The results highlight the challenges of general-purpose LLMs in materials science and the need for task-specific predictive models and task-specific instruction-tuned LLMs in materials property prediction.
Beyond Aesthetics: Cultural Competence in Text-to-Image Models
Jul 11, 2024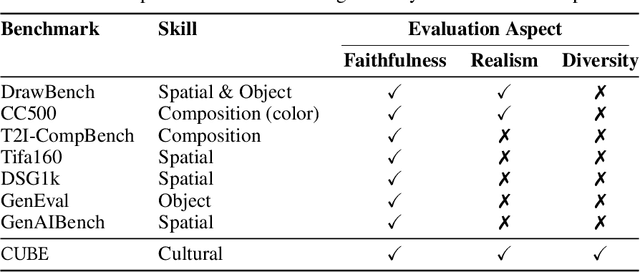
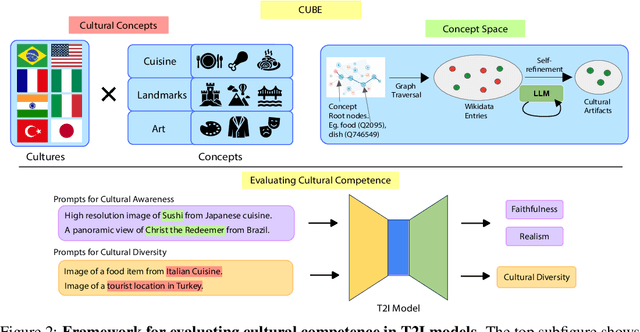


Text-to-Image (T2I) models are being increasingly adopted in diverse global communities where they create visual representations of their unique cultures. Current T2I benchmarks primarily focus on faithfulness, aesthetics, and realism of generated images, overlooking the critical dimension of cultural competence. In this work, we introduce a framework to evaluate cultural competence of T2I models along two crucial dimensions: cultural awareness and cultural diversity, and present a scalable approach using a combination of structured knowledge bases and large language models to build a large dataset of cultural artifacts to enable this evaluation. In particular, we apply this approach to build CUBE (CUltural BEnchmark for Text-to-Image models), a first-of-its-kind benchmark to evaluate cultural competence of T2I models. CUBE covers cultural artifacts associated with 8 countries across different geo-cultural regions and along 3 concepts: cuisine, landmarks, and art. CUBE consists of 1) CUBE-1K, a set of high-quality prompts that enable the evaluation of cultural awareness, and 2) CUBE-CSpace, a larger dataset of cultural artifacts that serves as grounding to evaluate cultural diversity. We also introduce cultural diversity as a novel T2I evaluation component, leveraging quality-weighted Vendi score. Our evaluations reveal significant gaps in the cultural awareness of existing models across countries and provide valuable insights into the cultural diversity of T2I outputs for under-specified prompts. Our methodology is extendable to other cultural regions and concepts, and can facilitate the development of T2I models that better cater to the global population.
Relational Reasoning On Graphs Using Opinion Dynamics
Jun 20, 2024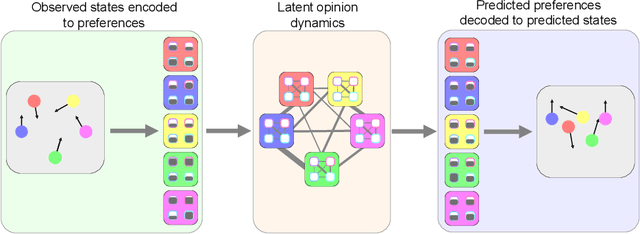


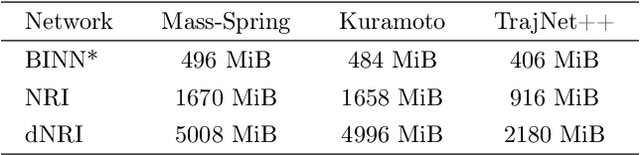
From pedestrians to Kuramoto oscillators, interactions between agents govern how a multitude of dynamical systems evolve in space and time. Discovering how these agents relate to each other can improve our understanding of the often complex dynamics that underlie these systems. Recent works learn to categorize relationships between agents based on observations of their physical behavior. These approaches are limited in that the relationship categories are modelled as independent and mutually exclusive, when in real world systems categories are often interacting. In this work, we introduce a level of abstraction between the physical behavior of agents and the categories that define their behavior. To do this, we learn a mapping from the agents' states to their affinities for each category in a graph neural network. We integrate the physical proximity of agents and their affinities in a nonlinear opinion dynamics model which provides a mechanism to identify mutually exclusive categories, predict an agent's evolution in time, and control an agent's behavior. We demonstrate the utility of our model for learning interpretable categories for mechanical systems, and demonstrate its efficacy on several long-horizon trajectory prediction benchmarks where we consistently out perform existing methods.
Constraint-Aware Diffusion Models for Trajectory Optimization
Jun 03, 2024



The diffusion model has shown success in generating high-quality and diverse solutions to trajectory optimization problems. However, diffusion models with neural networks inevitably make prediction errors, which leads to constraint violations such as unmet goals or collisions. This paper presents a novel constraint-aware diffusion model for trajectory optimization. We introduce a novel hybrid loss function for training that minimizes the constraint violation of diffusion samples compared to the groundtruth while recovering the original data distribution. Our model is demonstrated on tabletop manipulation and two-car reach-avoid problems, outperforming traditional diffusion models in minimizing constraint violations while generating samples close to locally optimal solutions.
Alternators For Sequence Modeling
May 20, 2024



This paper introduces alternators, a novel family of non-Markovian dynamical models for sequences. An alternator features two neural networks: the observation trajectory network (OTN) and the feature trajectory network (FTN). The OTN and the FTN work in conjunction, alternating between outputting samples in the observation space and some feature space, respectively, over a cycle. The parameters of the OTN and the FTN are not time-dependent and are learned via a minimum cross-entropy criterion over the trajectories. Alternators are versatile. They can be used as dynamical latent-variable generative models or as sequence-to-sequence predictors. When alternators are used as generative models, the FTN produces interpretable low-dimensional latent variables that capture the dynamics governing the observations. When alternators are used as sequence-to-sequence predictors, the FTN learns to predict the observed features. In both cases, the OTN learns to produce sequences that match the data. Alternators can uncover the latent dynamics underlying complex sequential data, accurately forecast and impute missing data, and sample new trajectories. We showcase the capabilities of alternators in three applications. We first used alternators to model the Lorenz equations, often used to describe chaotic behavior. We then applied alternators to Neuroscience, to map brain activity to physical activity. Finally, we applied alternators to Climate Science, focusing on sea-surface temperature forecasting. In all our experiments, we found alternators are stable to train, fast to sample from, yield high-quality generated samples and latent variables, and outperform strong baselines such as neural ODEs and diffusion models in the domains we studied.
Quality-Weighted Vendi Scores And Their Application To Diverse Experimental Design
May 03, 2024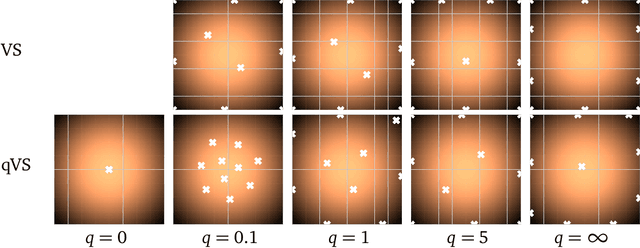
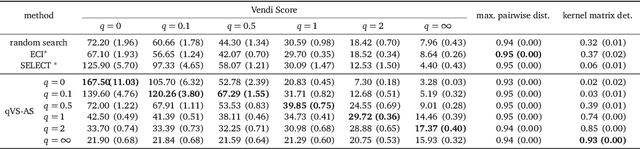
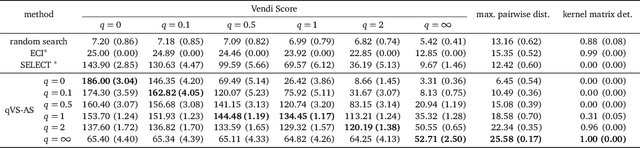
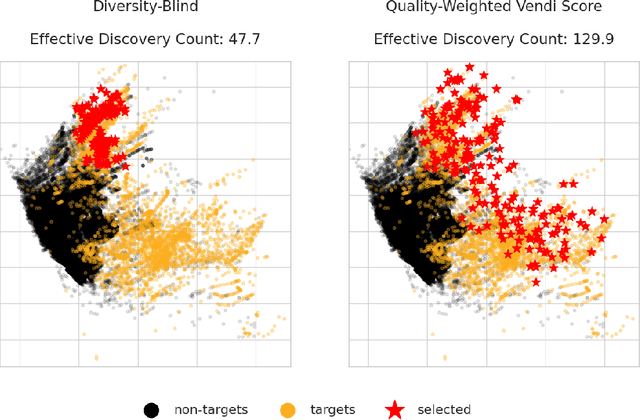
Experimental design techniques such as active search and Bayesian optimization are widely used in the natural sciences for data collection and discovery. However, existing techniques tend to favor exploitation over exploration of the search space, which causes them to get stuck in local optima. This ``collapse" problem prevents experimental design algorithms from yielding diverse high-quality data. In this paper, we extend the Vendi scores -- a family of interpretable similarity-based diversity metrics -- to account for quality. We then leverage these quality-weighted Vendi scores to tackle experimental design problems across various applications, including drug discovery, materials discovery, and reinforcement learning. We found that quality-weighted Vendi scores allow us to construct policies for experimental design that flexibly balance quality and diversity, and ultimately assemble rich and diverse sets of high-performing data points. Our algorithms led to a 70%-170% increase in the number of effective discoveries compared to baselines.