 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal-Canonicalization Equivariant Graph Neural Networks for Sample-Efficient and Generalizable Swarm Robot Control
Sep 17, 2025Multi-agent reinforcement learning (MARL) has emerged as a powerful paradigm for coordinating swarms of agents in complex decision-making, yet major challenges remain. In competitive settings such as pursuer-evader tasks, simultaneous adaptation can destabilize training; non-kinetic countermeasures often fail under adverse conditions; and policies trained in one configuration rarely generalize to environments with a different number of agents. To address these issues, we propose the Local-Canonicalization Equivariant Graph Neural Networks (LEGO) framework, which integrates seamlessly with popular MARL algorithms such as MAPPO. LEGO employs graph neural networks to capture permutation equivariance and generalization to different agent numbers, canonicalization to enforce E(n)-equivariance, and heterogeneous representations to encode role-specific inductive biases. Experiments on cooperative and competitive swarm benchmarks show that LEGO outperforms strong baselines and improves generalization. In real-world experiments, LEGO demonstrates robustness to varying team sizes and agent failure.
Understanding Oversmoothing in GNNs as Consensus in Opinion Dynamics
Jan 31, 2025In contrast to classes of neural networks where the learned representations become increasingly expressive with network depth, the learned representations in graph neural networks (GNNs), tend to become increasingly similar. This phenomena, known as oversmoothing, is characterized by learned representations that cannot be reliably differentiated leading to reduced predictive performance. In this paper, we propose an analogy between oversmoothing in GNNs and consensus or agreement in opinion dynamics. Through this analogy, we show that the message passing structure of recent continuous-depth GNNs is equivalent to a special case of opinion dynamics (i.e., linear consensus models) which has been theoretically proven to converge to consensus (i.e., oversmoothing) for all inputs. Using the understanding developed through this analogy, we design a new continuous-depth GNN model based on nonlinear opinion dynamics and prove that our model, which we call behavior-inspired message passing neural network (BIMP) circumvents oversmoothing for general inputs. Through extensive experiments, we show that BIMP is robust to oversmoothing and adversarial attack, and consistently outperforms competitive baselines on numerous benchmarks.
Relational Reasoning On Graphs Using Opinion Dynamics
Jun 20, 2024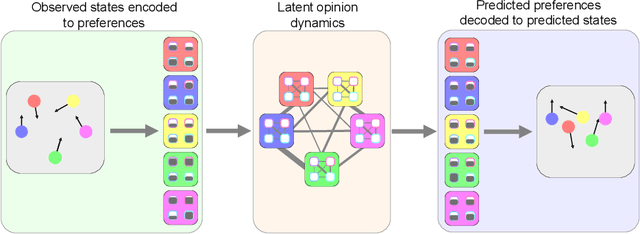


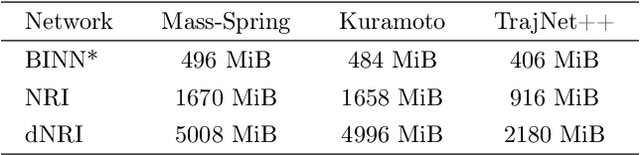
From pedestrians to Kuramoto oscillators, interactions between agents govern how a multitude of dynamical systems evolve in space and time. Discovering how these agents relate to each other can improve our understanding of the often complex dynamics that underlie these systems. Recent works learn to categorize relationships between agents based on observations of their physical behavior. These approaches are limited in that the relationship categories are modelled as independent and mutually exclusive, when in real world systems categories are often interacting. In this work, we introduce a level of abstraction between the physical behavior of agents and the categories that define their behavior. To do this, we learn a mapping from the agents' states to their affinities for each category in a graph neural network. We integrate the physical proximity of agents and their affinities in a nonlinear opinion dynamics model which provides a mechanism to identify mutually exclusive categories, predict an agent's evolution in time, and control an agent's behavior. We demonstrate the utility of our model for learning interpretable categories for mechanical systems, and demonstrate its efficacy on several long-horizon trajectory prediction benchmarks where we consistently out perform existing methods.
MAN: Multi-Action Networks Learning
Sep 19, 2022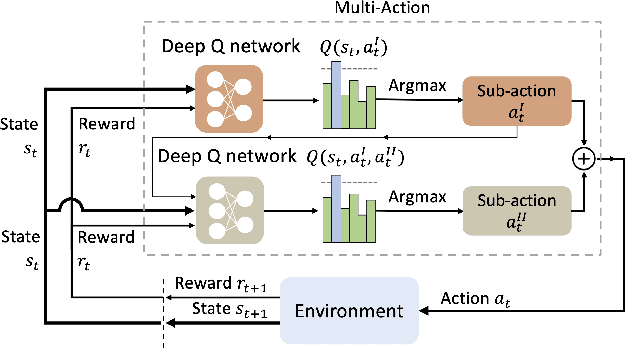

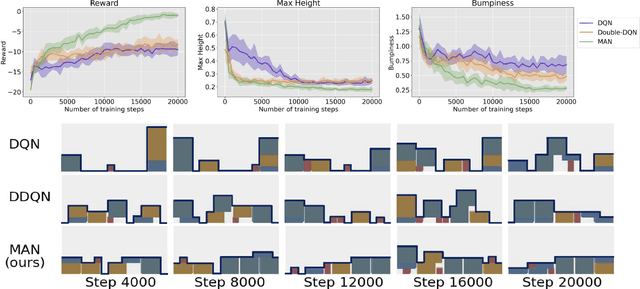

Learning control policies with large action spaces is a challenging problem in the field of reinforcement learning due to present inefficiencies in exploration. In this work, we introduce a Deep Reinforcement Learning (DRL) algorithm call Multi-Action Networks (MAN) Learning that addresses the challenge of large discrete action spaces. We propose separating the action space into two components, creating a Value Neural Network for each sub-action. Then, MAN uses temporal-difference learning to train the networks synchronously, which is simpler than training a single network with a large action output directly. To evaluate the proposed method, we test MAN on a block stacking task, and then extend MAN to handle 12 games from the Atari Arcade Learning environment with 18 action spaces. Our results indicate that MAN learns faster than both Deep Q-Learning and Double Deep Q-Learning, implying our method is a better performing synchronous temporal difference algorithm than those currently available for large action spaces.