 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Field Thermal Tomography: A Differentiable Physics Framework for Non-Destructive Evaluation
Mar 11, 2026We propose Neural Field Thermal Tomography (NeFTY), a differentiable physics framework for the quantitative 3D reconstruction of material properties from transient surface temperature measurements. While traditional thermography relies on pixel-wise 1D approximations that neglect lateral diffusion, and soft-constrained Physics-Informed Neural Networks (PINNs) often fail in transient diffusion scenarios due to gradient stiffness, NeFTY parameterizes the 3D diffusivity field as a continuous neural field optimized through a rigorous numerical solver. By leveraging a differentiable physics solver, our approach enforces thermodynamic laws as hard constraints while maintaining the memory efficiency required for high-resolution 3D tomography. Our discretize-then-optimize paradigm effectively mitigates the spectral bias and ill-posedness inherent in inverse heat conduction, enabling the recovery of subsurface defects at arbitrary scales. Experimental validation on synthetic data demonstrates that NeFTY significantly improves the accuracy of subsurface defect localization over baselines. Additional details at https://cab-lab-princeton.github.io/nefty/
A Hypertoroidal Covering for Perfect Color Equivariance
Mar 04, 2026When the color distribution of input images changes at inference, the performance of conventional neural network architectures drops considerably. A few researchers have begun to incorporate prior knowledge of color geometry in neural network design. These color equivariant architectures have modeled hue variation with 2D rotations, and saturation and luminance transformations as 1D translations. While this approach improves neural network robustness to color variations in a number of contexts, we find that approximating saturation and luminance (interval valued quantities) as 1D translations introduces appreciable artifacts. In this paper, we introduce a color equivariant architecture that is truly equivariant. Instead of approximating the interval with the real line, we lift values on the interval to values on the circle (a double-cover) and build equivariant representations there. Our approach resolves the approximation artifacts of previous methods, improves interpretability and generalizability, and achieves better predictive performance than conventional and equivariant baselines on tasks such as fine-grained classification and medical imaging tasks. Going beyond the context of color, we show that our proposed lifting can also extend to geometric transformations such as scale.
Local-Canonicalization Equivariant Graph Neural Networks for Sample-Efficient and Generalizable Swarm Robot Control
Sep 17, 2025Multi-agent reinforcement learning (MARL) has emerged as a powerful paradigm for coordinating swarms of agents in complex decision-making, yet major challenges remain. In competitive settings such as pursuer-evader tasks, simultaneous adaptation can destabilize training; non-kinetic countermeasures often fail under adverse conditions; and policies trained in one configuration rarely generalize to environments with a different number of agents. To address these issues, we propose the Local-Canonicalization Equivariant Graph Neural Networks (LEGO) framework, which integrates seamlessly with popular MARL algorithms such as MAPPO. LEGO employs graph neural networks to capture permutation equivariance and generalization to different agent numbers, canonicalization to enforce E(n)-equivariance, and heterogeneous representations to encode role-specific inductive biases. Experiments on cooperative and competitive swarm benchmarks show that LEGO outperforms strong baselines and improves generalization. In real-world experiments, LEGO demonstrates robustness to varying team sizes and agent failure.
Surrogate Modeling of 3D Rayleigh-Benard Convection with Equivariant Autoencoders
May 19, 2025



The use of machine learning for modeling, understanding, and controlling large-scale physics systems is quickly gaining in popularity, with examples ranging from electromagnetism over nuclear fusion reactors and magneto-hydrodynamics to fluid mechanics and climate modeling. These systems -- governed by partial differential equations -- present unique challenges regarding the large number of degrees of freedom and the complex dynamics over many scales both in space and time, and additional measures to improve accuracy and sample efficiency are highly desirable. We present an end-to-end equivariant surrogate model consisting of an equivariant convolutional autoencoder and an equivariant convolutional LSTM using $G$-steerable kernels. As a case study, we consider the three-dimensional Rayleigh-B\'enard convection, which describes the buoyancy-driven fluid flow between a heated bottom and a cooled top plate. While the system is E(2)-equivariant in the horizontal plane, the boundary conditions break the translational equivariance in the vertical direction. Our architecture leverages vertically stacked layers of $D_4$-steerable kernels, with additional partial kernel sharing in the vertical direction for further efficiency improvement. Our results demonstrate significant gains both in sample and parameter efficiency, as well as a better scaling to more complex dynamics, that is, larger Rayleigh numbers. The accompanying code is available under https://github.com/FynnFromme/equivariant-rb-forecasting.
GAGrasp: Geometric Algebra Diffusion for Dexterous Grasping
Mar 06, 2025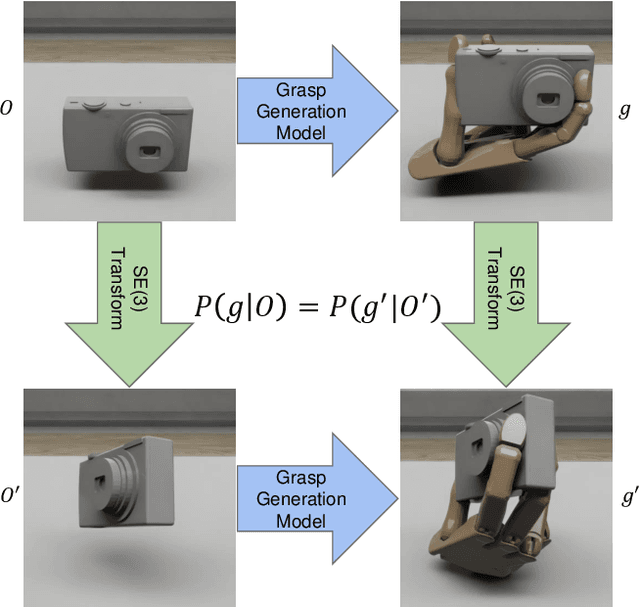
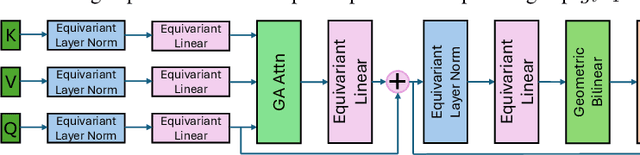

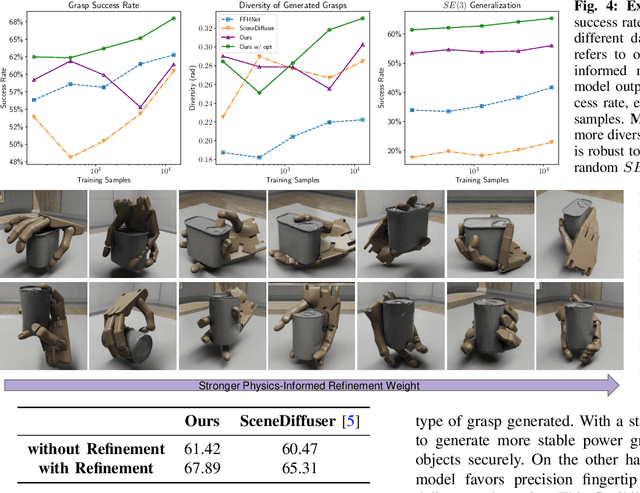
We propose GAGrasp, a novel framework for dexterous grasp generation that leverages geometric algebra representations to enforce equivariance to SE(3) transformations. By encoding the SE(3) symmetry constraint directly into the architecture, our method improves data and parameter efficiency while enabling robust grasp generation across diverse object poses. Additionally, we incorporate a differentiable physics-informed refinement layer, which ensures that generated grasps are physically plausible and stable. Extensive experiments demonstrate the model's superior performance in generalization, stability, and adaptability compared to existing methods. Additional details at https://gagrasp.github.io/
Understanding Oversmoothing in GNNs as Consensus in Opinion Dynamics
Jan 31, 2025In contrast to classes of neural networks where the learned representations become increasingly expressive with network depth, the learned representations in graph neural networks (GNNs), tend to become increasingly similar. This phenomena, known as oversmoothing, is characterized by learned representations that cannot be reliably differentiated leading to reduced predictive performance. In this paper, we propose an analogy between oversmoothing in GNNs and consensus or agreement in opinion dynamics. Through this analogy, we show that the message passing structure of recent continuous-depth GNNs is equivalent to a special case of opinion dynamics (i.e., linear consensus models) which has been theoretically proven to converge to consensus (i.e., oversmoothing) for all inputs. Using the understanding developed through this analogy, we design a new continuous-depth GNN model based on nonlinear opinion dynamics and prove that our model, which we call behavior-inspired message passing neural network (BIMP) circumvents oversmoothing for general inputs. Through extensive experiments, we show that BIMP is robust to oversmoothing and adversarial attack, and consistently outperforms competitive baselines on numerous benchmarks.
Relational Reasoning On Graphs Using Opinion Dynamics
Jun 20, 2024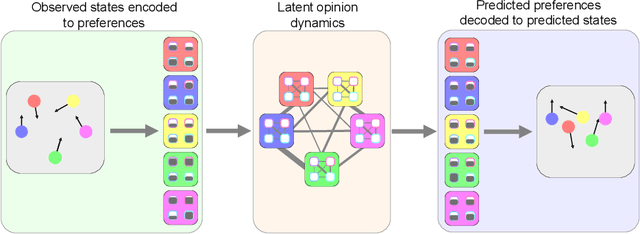


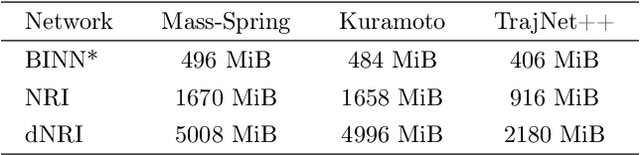
From pedestrians to Kuramoto oscillators, interactions between agents govern how a multitude of dynamical systems evolve in space and time. Discovering how these agents relate to each other can improve our understanding of the often complex dynamics that underlie these systems. Recent works learn to categorize relationships between agents based on observations of their physical behavior. These approaches are limited in that the relationship categories are modelled as independent and mutually exclusive, when in real world systems categories are often interacting. In this work, we introduce a level of abstraction between the physical behavior of agents and the categories that define their behavior. To do this, we learn a mapping from the agents' states to their affinities for each category in a graph neural network. We integrate the physical proximity of agents and their affinities in a nonlinear opinion dynamics model which provides a mechanism to identify mutually exclusive categories, predict an agent's evolution in time, and control an agent's behavior. We demonstrate the utility of our model for learning interpretable categories for mechanical systems, and demonstrate its efficacy on several long-horizon trajectory prediction benchmarks where we consistently out perform existing methods.
Color Equivariant Network
Jun 13, 2024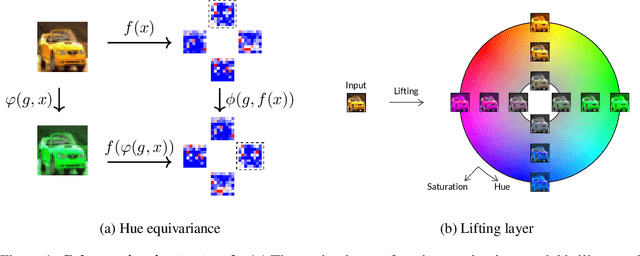

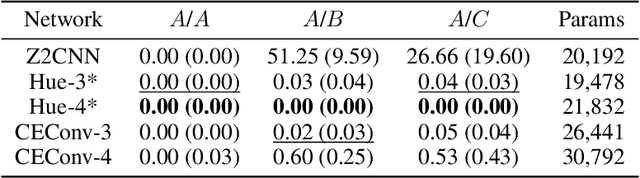
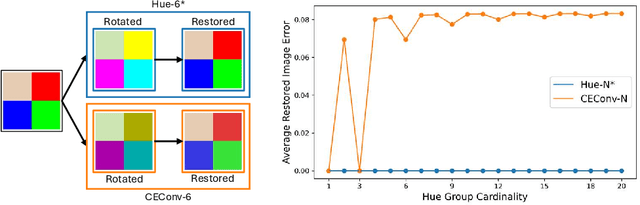
Group equivariant convolutional neural networks have been designed for a variety of geometric transformations from 2D and 3D rotation groups, to semi-groups such as scale. Despite the improved interpretability, accuracy and generalizability afforded by these architectures, group equivariant networks have seen limited application in the context of perceptual quantities such as hue and saturation, even though their variation can lead to significant reductions in classification performance. In this paper, we introduce convolutional neural networks equivariant to variations in hue and saturation by design. To achieve this, we leverage the observation that hue and saturation transformations can be identified with the 2D rotation and 1D translation groups respectively. Our hue-, saturation-, and fully color-equivariant networks achieve equivariance to these perceptual transformations without an increase in network parameters. We demonstrate the utility of our networks on synthetic and real world datasets where color and lighting variations are commonplace.
Learning to predict 3D rotational dynamics from images of a rigid body with unknown mass distribution
Aug 24, 2023

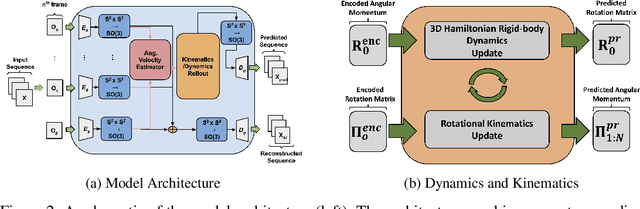

In many real-world settings, image observations of freely rotating 3D rigid bodies, may be available when low-dimensional measurements are not. However, the high-dimensionality of image data precludes the use of classical estimation techniques to learn the dynamics. The usefulness of standard deep learning methods is also limited because an image of a rigid body reveals nothing about the distribution of mass inside the body, which, together with initial angular velocity, is what determines how the body will rotate. We present a physics-informed neural network model to estimate and predict 3D rotational dynamics from image sequences. We achieve this using a multi-stage prediction pipeline that maps individual images to a latent representation homeomorphic to $\mathbf{SO}(3)$, computes angular velocities from latent pairs, and predicts future latent states using the Hamiltonian equations of motion. We demonstrate the efficacy of our approach on new rotating rigid-body datasets of sequences of synthetic images of rotating objects, including cubes, prisms and satellites, with unknown uniform and non-uniform mass distributions.
Hamiltonian GAN
Aug 22, 2023



A growing body of work leverages the Hamiltonian formalism as an inductive bias for physically plausible neural network based video generation. The structure of the Hamiltonian ensures conservation of a learned quantity (e.g., energy) and imposes a phase-space interpretation on the low-dimensional manifold underlying the input video. While this interpretation has the potential to facilitate the integration of learned representations in downstream tasks, existing methods are limited in their applicability as they require a structural prior for the configuration space at design time. In this work, we present a GAN-based video generation pipeline with a learned configuration space map and Hamiltonian neural network motion model, to learn a representation of the configuration space from data. We train our model with a physics-inspired cyclic-coordinate loss function which encourages a minimal representation of the configuration space and improves interpretability. We demonstrate the efficacy and advantages of our approach on the Hamiltonian Dynamics Suite Toy Physics dataset.