 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeX4Val: Learning Neural Surrogates for Variance-Reduced Policy Evaluation
Jun 03, 2026Rigorous evaluation of learning-based robotic systems is an essential prerequisite for deployment. However, real-world test data is expensive to gather; moreover, in a typical iterative development context, data gathered from the latest policy is necessarily limited in scale. This motivates evaluation methodologies that make use of heterogeneous data sources, including simulation, historical policy logs, and data collected from related platforms or environments. While such auxiliary data are abundant and inexpensive, they are generally not directly representative of real-world outcomes -- for example, performance in simulation may differ substantially from performance in the real world -- making their principled use for high-confidence performance estimation challenging. In this paper, we introduce X4Val, a general framework for variance-reduced real-world metric estimation in the presence of non-paired, multi-domain data. X4Val embeds samples from real and auxiliary domains into a shared representation space and learns a transferable predictor of real-world metrics; this learned predictor is then incorporated into a control-variates estimator, enabling variance reduction even when paired samples are unavailable. We provide theoretical analysis and empirical evaluations on autonomous driving and real-world robot manipulation tasks, domains across which X4Val achieves up to 38.4% variance reduction and demonstrates consistent improvements over strong baselines. These results show that non-paired, heterogeneous data can be leveraged to substantially improve the sample efficiency of rigorous robotic system validation.
StressDream: Steering Video World Models for Robust Policy Evaluation and Improvement
May 29, 2026Video world models (WMs) have shown promise for policy evaluation and improvement by imagining realistic future observations conditioned on ego-robot actions. While WMs can model distributions over futures, policy evaluation and improvement typically rely on nominal imaginations, which can miss high-impact outcomes of robot actions unless prohibitively many samples are drawn. To enable robust policy evaluation and improvement over WM imaginations, we propose StressDream, which steers imaginations toward high-impact yet plausible outcomes specified at inference time by optimizing the initial noise of diffusion-based WMs. However, optimizing high-dimensional noise is challenging: the optimization must reason about nuanced, scene-dependent target events in generated videos while avoiding out-of-distribution (OOD) noise that yields implausible imaginations. We address this with two complementary objectives: a semantic objective with a Vision-Language Model that provides informative gradients by reasoning about the generated video, and a plausibility objective that prevents the optimized noise from drifting OOD. With state-of-the-art video world models for autonomous driving and robotic manipulation, we show that StressDream effectively steers imaginations toward high-impact yet plausible outcomes specified by text at inference time, such as task failures, enabling robust policy evaluation and improvement by identifying actions whose plausible futures include undesirable outcomes. Video results are available at https://junwon.me/StressDream/.
Modular Safety Guardrails Are Necessary for Foundation-Model-Enabled Robots in the Real World
Feb 03, 2026The integration of foundation models (FMs) into robotics has accelerated real-world deployment, while introducing new safety challenges arising from open-ended semantic reasoning and embodied physical action. These challenges require safety notions beyond physical constraint satisfaction. In this paper, we characterize FM-enabled robot safety along three dimensions: action safety (physical feasibility and constraint compliance), decision safety (semantic and contextual appropriateness), and human-centered safety (conformance to human intent, norms, and expectations). We argue that existing approaches, including static verification, monolithic controllers, and end-to-end learned policies, are insufficient in settings where tasks, environments, and human expectations are open-ended, long-tailed, and subject to adaptation over time. To address this gap, we propose modular safety guardrails, consisting of monitoring (evaluation) and intervention layers, as an architectural foundation for comprehensive safety across the autonomy stack. Beyond modularity, we highlight possible cross-layer co-design opportunities through representation alignment and conservatism allocation to enable faster, less conservative, and more effective safety enforcement. We call on the community to explore richer guardrail modules and principled co-design strategies to advance safe real-world physical AI deployment.
Safety Evaluation of Motion Plans Using Trajectory Predictors as Forward Reachable Set Estimators
Jul 30, 2025

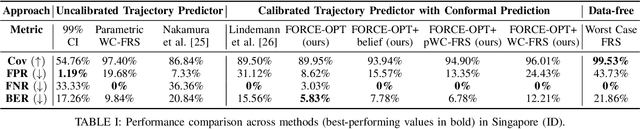

The advent of end-to-end autonomy stacks - often lacking interpretable intermediate modules - has placed an increased burden on ensuring that the final output, i.e., the motion plan, is safe in order to validate the safety of the entire stack. This requires a safety monitor that is both complete (able to detect all unsafe plans) and sound (does not flag safe plans). In this work, we propose a principled safety monitor that leverages modern multi-modal trajectory predictors to approximate forward reachable sets (FRS) of surrounding agents. By formulating a convex program, we efficiently extract these data-driven FRSs directly from the predicted state distributions, conditioned on scene context such as lane topology and agent history. To ensure completeness, we leverage conformal prediction to calibrate the FRS and guarantee coverage of ground-truth trajectories with high probability. To preserve soundness in out-of-distribution (OOD) scenarios or under predictor failure, we introduce a Bayesian filter that dynamically adjusts the FRS conservativeness based on the predictor's observed performance. We then assess the safety of the ego vehicle's motion plan by checking for intersections with these calibrated FRSs, ensuring the plan remains collision-free under plausible future behaviors of others. Extensive experiments on the nuScenes dataset show our approach significantly improves soundness while maintaining completeness, offering a practical and reliable safety monitor for learned autonomy stacks.
Leveraging Correlation Across Test Platforms for Variance-Reduced Metric Estimation
Jun 25, 2025



Learning-based robotic systems demand rigorous validation to assure reliable performance, but extensive real-world testing is often prohibitively expensive, and if conducted may still yield insufficient data for high-confidence guarantees. In this work, we introduce a general estimation framework that leverages paired data across test platforms, e.g., paired simulation and real-world observations, to achieve better estimates of real-world metrics via the method of control variates. By incorporating cheap and abundant auxiliary measurements (for example, simulator outputs) as control variates for costly real-world samples, our method provably reduces the variance of Monte Carlo estimates and thus requires significantly fewer real-world samples to attain a specified confidence bound on the mean performance. We provide theoretical analysis characterizing the variance and sample-efficiency improvement, and demonstrate empirically in autonomous driving and quadruped robotics settings that our approach achieves high-probability bounds with markedly improved sample efficiency. Our technique can lower the real-world testing burden for validating the performance of the stack, thereby enabling more efficient and cost-effective experimental evaluation of robotic systems.
RealDrive: Retrieval-Augmented Driving with Diffusion Models
May 30, 2025



Learning-based planners generate natural human-like driving behaviors by learning to reason about nuanced interactions from data, overcoming the rigid behaviors that arise from rule-based planners. Nonetheless, data-driven approaches often struggle with rare, safety-critical scenarios and offer limited controllability over the generated trajectories. To address these challenges, we propose RealDrive, a Retrieval-Augmented Generation (RAG) framework that initializes a diffusion-based planning policy by retrieving the most relevant expert demonstrations from the training dataset. By interpolating between current observations and retrieved examples through a denoising process, our approach enables fine-grained control and safe behavior across diverse scenarios, leveraging the strong prior provided by the retrieved scenario. Another key insight we produce is that a task-relevant retrieval model trained with planning-based objectives results in superior planning performance in our framework compared to a task-agnostic retriever. Experimental results demonstrate improved generalization to long-tail events and enhanced trajectory diversity compared to standard learning-based planners -- we observe a 40% reduction in collision rate on the Waymo Open Motion dataset with RAG.
Online Aggregation of Trajectory Predictors
Feb 11, 2025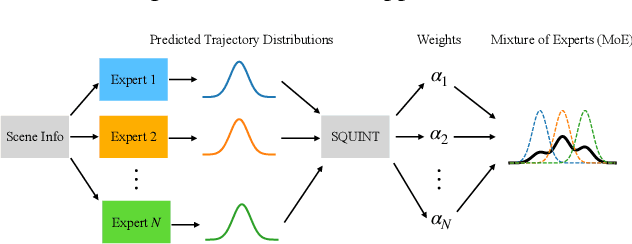
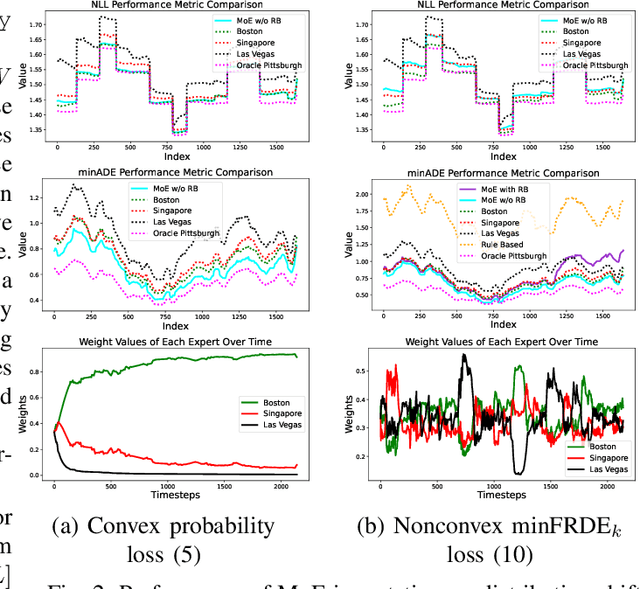
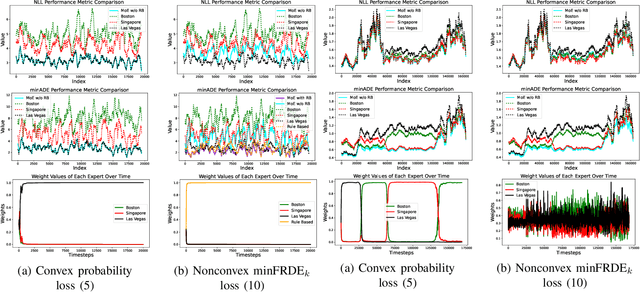
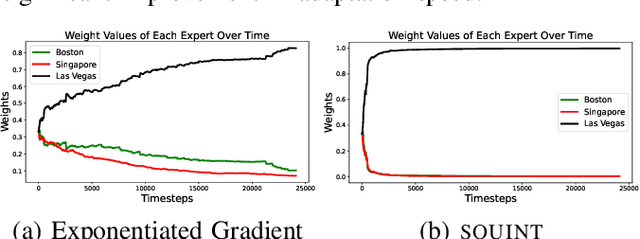
Trajectory prediction, the task of forecasting future agent behavior from past data, is central to safe and efficient autonomous driving. A diverse set of methods (e.g., rule-based or learned with different architectures and datasets) have been proposed, yet it is often the case that the performance of these methods is sensitive to the deployment environment (e.g., how well the design rules model the environment, or how accurately the test data match the training data). Building upon the principled theory of online convex optimization but also going beyond convexity and stationarity, we present a lightweight and model-agnostic method to aggregate different trajectory predictors online. We propose treating each individual trajectory predictor as an "expert" and maintaining a probability vector to mix the outputs of different experts. Then, the key technical approach lies in leveraging online data -the true agent behavior to be revealed at the next timestep- to form a convex-or-nonconvex, stationary-or-dynamic loss function whose gradient steers the probability vector towards choosing the best mixture of experts. We instantiate this method to aggregate trajectory predictors trained on different cities in the NUSCENES dataset and show that it performs just as well, if not better than, any singular model, even when deployed on the out-of-distribution LYFT dataset.
Surprise Potential as a Measure of Interactivity in Driving Scenarios
Feb 08, 2025Validating the safety and performance of an autonomous vehicle (AV) requires benchmarking on real-world driving logs. However, typical driving logs contain mostly uneventful scenarios with minimal interactions between road users. Identifying interactive scenarios in real-world driving logs enables the curation of datasets that amplify critical signals and provide a more accurate assessment of an AV's performance. In this paper, we present a novel metric that identifies interactive scenarios by measuring an AV's surprise potential on others. First, we identify three dimensions of the design space to describe a family of surprise potential measures. Second, we exhaustively evaluate and compare different instantiations of the surprise potential measure within this design space on the nuScenes dataset. To determine how well a surprise potential measure correctly identifies an interactive scenario, we use a reward model learned from human preferences to assess alignment with human intuition. Our proposed surprise potential, arising from this exhaustive comparative study, achieves a correlation of more than 0.82 with the human-aligned reward function, outperforming existing approaches. Lastly, we validate motion planners on curated interactive scenarios to demonstrate downstream applications.
LoRD: Adapting Differentiable Driving Policies to Distribution Shifts
Oct 15, 2024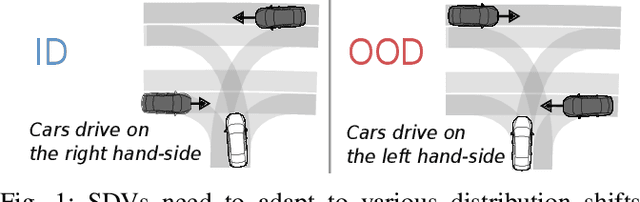
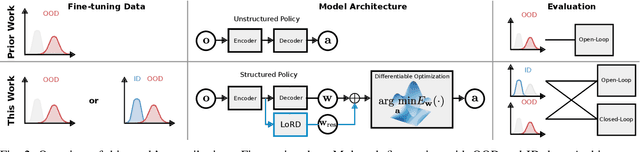

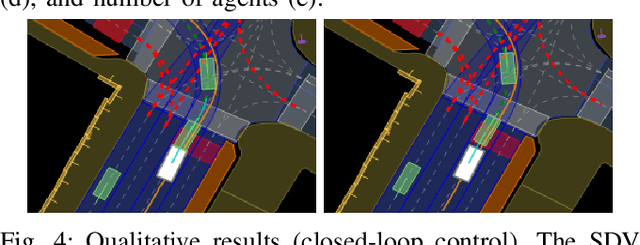
Distribution shifts between operational domains can severely affect the performance of learned models in self-driving vehicles (SDVs). While this is a well-established problem, prior work has mostly explored naive solutions such as fine-tuning, focusing on the motion prediction task. In this work, we explore novel adaptation strategies for differentiable autonomy stacks consisting of prediction, planning, and control, perform evaluation in closed-loop, and investigate the often-overlooked issue of catastrophic forgetting. Specifically, we introduce two simple yet effective techniques: a low-rank residual decoder (LoRD) and multi-task fine-tuning. Through experiments across three models conducted on two real-world autonomous driving datasets (nuPlan, exiD), we demonstrate the effectiveness of our methods and highlight a significant performance gap between open-loop and closed-loop evaluation in prior approaches. Our approach improves forgetting by up to 23.33% and the closed-loop OOD driving score by 8.83% in comparison to standard fine-tuning.
System-Level Safety Monitoring and Recovery for Perception Failures in Autonomous Vehicles
Sep 26, 2024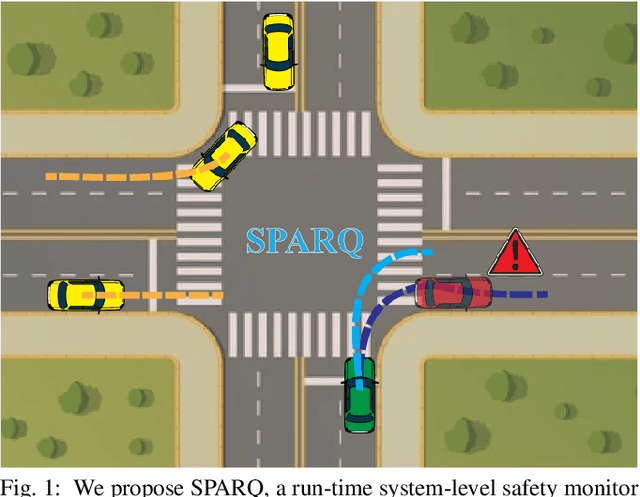
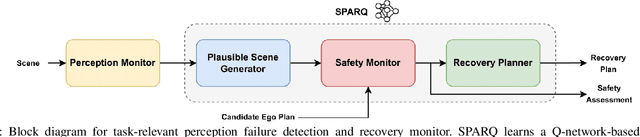
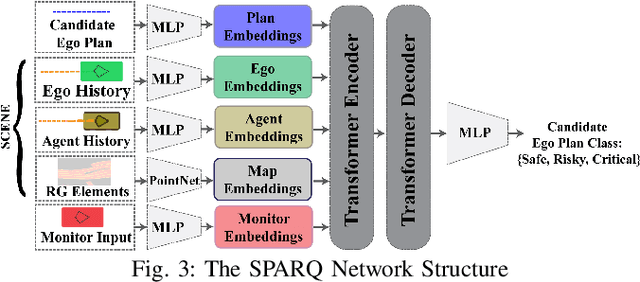
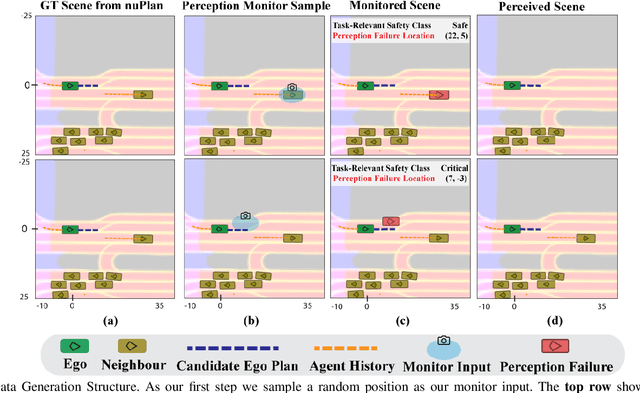
The safety-critical nature of autonomous vehicle (AV) operation necessitates development of task-relevant algorithms that can reason about safety at the system level and not just at the component level. To reason about the impact of a perception failure on the entire system performance, such task-relevant algorithms must contend with various challenges: complexity of AV stacks, high uncertainty in the operating environments, and the need for real-time performance. To overcome these challenges, in this work, we introduce a Q-network called SPARQ (abbreviation for Safety evaluation for Perception And Recovery Q-network) that evaluates the safety of a plan generated by a planning algorithm, accounting for perception failures that the planning process may have overlooked. This Q-network can be queried during system runtime to assess whether a proposed plan is safe for execution or poses potential safety risks. If a violation is detected, the network can then recommend a corrective plan while accounting for the perceptual failure. We validate our algorithm using the NuPlan-Vegas dataset, demonstrating its ability to handle cases where a perception failure compromises a proposed plan while the corrective plan remains safe. We observe an overall accuracy and recall of 90% while sustaining a frequency of 42Hz on the unseen testing dataset. We compare our performance to a popular reachability-based baseline and analyze some interesting properties of our approach in improving the safety properties of an AV pipeline.