 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEagle 2.5: Boosting Long-Context Post-Training for Frontier Vision-Language Models
Apr 21, 2025We introduce Eagle 2.5, a family of frontier vision-language models (VLMs) for long-context multimodal learning. Our work addresses the challenges in long video comprehension and high-resolution image understanding, introducing a generalist framework for both tasks. The proposed training framework incorporates Automatic Degrade Sampling and Image Area Preservation, two techniques that preserve contextual integrity and visual details. The framework also includes numerous efficiency optimizations in the pipeline for long-context data training. Finally, we propose Eagle-Video-110K, a novel dataset that integrates both story-level and clip-level annotations, facilitating long-video understanding. Eagle 2.5 demonstrates substantial improvements on long-context multimodal benchmarks, providing a robust solution to the limitations of existing VLMs. Notably, our best model Eagle 2.5-8B achieves 72.4% on Video-MME with 512 input frames, matching the results of top-tier commercial model such as GPT-4o and large-scale open-source models like Qwen2.5-VL-72B and InternVL2.5-78B.
Latent-INR: A Flexible Framework for Implicit Representations of Videos with Discriminative Semantics
Aug 05, 2024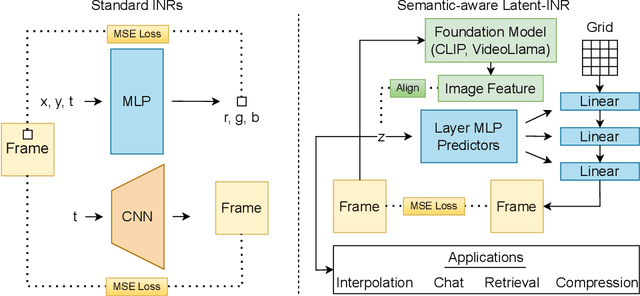
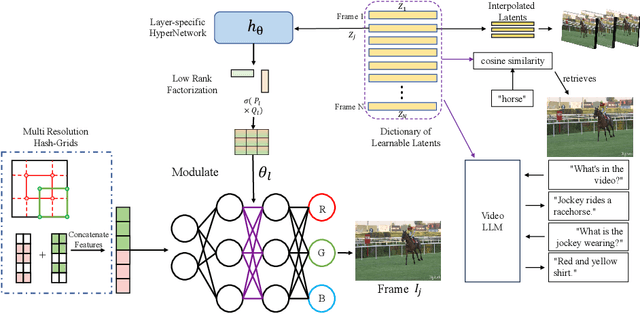
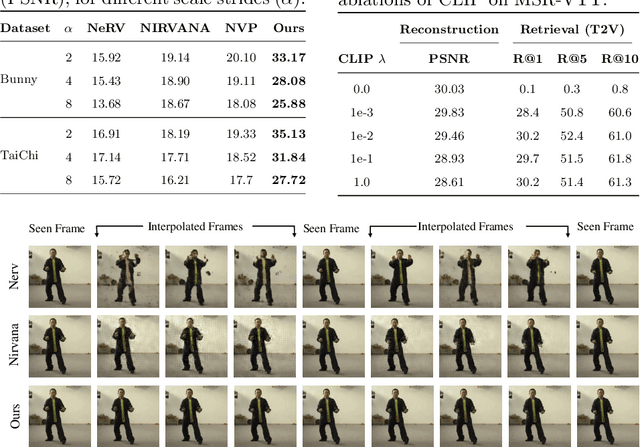
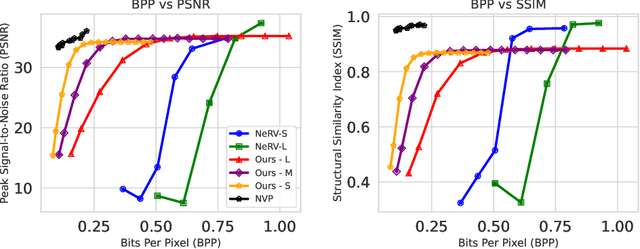
Implicit Neural Networks (INRs) have emerged as powerful representations to encode all forms of data, including images, videos, audios, and scenes. With video, many INRs for video have been proposed for the compression task, and recent methods feature significant improvements with respect to encoding time, storage, and reconstruction quality. However, these encoded representations lack semantic meaning, so they cannot be used for any downstream tasks that require such properties, such as retrieval. This can act as a barrier for adoption of video INRs over traditional codecs as they do not offer any significant edge apart from compression. To alleviate this, we propose a flexible framework that decouples the spatial and temporal aspects of the video INR. We accomplish this with a dictionary of per-frame latents that are learned jointly with a set of video specific hypernetworks, such that given a latent, these hypernetworks can predict the INR weights to reconstruct the given frame. This framework not only retains the compression efficiency, but the learned latents can be aligned with features from large vision models, which grants them discriminative properties. We align these latents with CLIP and show good performance for both compression and video retrieval tasks. By aligning with VideoLlama, we are able to perform open-ended chat with our learned latents as the visual inputs. Additionally, the learned latents serve as a proxy for the underlying weights, allowing us perform tasks like video interpolation. These semantic properties and applications, existing simultaneously with ability to perform compression, interpolation, and superresolution properties, are a first in this field of work.
Wolf: Captioning Everything with a World Summarization Framework
Jul 26, 2024



We propose Wolf, a WOrLd summarization Framework for accurate video captioning. Wolf is an automated captioning framework that adopts a mixture-of-experts approach, leveraging complementary strengths of Vision Language Models (VLMs). By utilizing both image and video models, our framework captures different levels of information and summarizes them efficiently. Our approach can be applied to enhance video understanding, auto-labeling, and captioning. To evaluate caption quality, we introduce CapScore, an LLM-based metric to assess the similarity and quality of generated captions compared to the ground truth captions. We further build four human-annotated datasets in three domains: autonomous driving, general scenes, and robotics, to facilitate comprehensive comparisons. We show that Wolf achieves superior captioning performance compared to state-of-the-art approaches from the research community (VILA1.5, CogAgent) and commercial solutions (Gemini-Pro-1.5, GPT-4V). For instance, in comparison with GPT-4V, Wolf improves CapScore both quality-wise by 55.6% and similarity-wise by 77.4% on challenging driving videos. Finally, we establish a benchmark for video captioning and introduce a leaderboard, aiming to accelerate advancements in video understanding, captioning, and data alignment. Leaderboard: https://wolfv0.github.io/leaderboard.html.
Explaining the Implicit Neural Canvas: Connecting Pixels to Neurons by Tracing their Contributions
Jan 18, 2024The many variations of Implicit Neural Representations (INRs), where a neural network is trained as a continuous representation of a signal, have tremendous practical utility for downstream tasks including novel view synthesis, video compression, and image superresolution. Unfortunately, the inner workings of these networks are seriously under-studied. Our work, eXplaining the Implicit Neural Canvas (XINC), is a unified framework for explaining properties of INRs by examining the strength of each neuron's contribution to each output pixel. We call the aggregate of these contribution maps the Implicit Neural Canvas and we use this concept to demonstrate that the INRs which we study learn to ''see'' the frames they represent in surprising ways. For example, INRs tend to have highly distributed representations. While lacking high-level object semantics, they have a significant bias for color and edges, and are almost entirely space-agnostic. We arrive at our conclusions by examining how objects are represented across time in video INRs, using clustering to visualize similar neurons across layers and architectures, and show that this is dominated by motion. These insights demonstrate the general usefulness of our analysis framework. Our project page is available at https://namithap10.github.io/xinc.
NIRVANA: Neural Implicit Representations of Videos with Adaptive Networks and Autoregressive Patch-wise Modeling
Dec 30, 2022Implicit Neural Representations (INR) have recently shown to be powerful tool for high-quality video compression. However, existing works are limiting as they do not explicitly exploit the temporal redundancy in videos, leading to a long encoding time. Additionally, these methods have fixed architectures which do not scale to longer videos or higher resolutions. To address these issues, we propose NIRVANA, which treats videos as groups of frames and fits separate networks to each group performing patch-wise prediction. This design shares computation within each group, in the spatial and temporal dimensions, resulting in reduced encoding time of the video. The video representation is modeled autoregressively, with networks fit on a current group initialized using weights from the previous group's model. To further enhance efficiency, we perform quantization of the network parameters during training, requiring no post-hoc pruning or quantization. When compared with previous works on the benchmark UVG dataset, NIRVANA improves encoding quality from 37.36 to 37.70 (in terms of PSNR) and the encoding speed by 12X, while maintaining the same compression rate. In contrast to prior video INR works which struggle with larger resolution and longer videos, we show that our algorithm is highly flexible and scales naturally due to its patch-wise and autoregressive designs. Moreover, our method achieves variable bitrate compression by adapting to videos with varying inter-frame motion. NIRVANA achieves 6X decoding speed and scales well with more GPUs, making it practical for various deployment scenarios.
The First Principles of Deep Learning and Compression
Apr 04, 2022The deep learning revolution incited by the 2012 Alexnet paper has been transformative for the field of computer vision. Many problems which were severely limited using classical solutions are now seeing unprecedented success. The rapid proliferation of deep learning methods has led to a sharp increase in their use in consumer and embedded applications. One consequence of consumer and embedded applications is lossy multimedia compression which is required to engineer the efficient storage and transmission of data in these real-world scenarios. As such, there has been increased interest in a deep learning solution for multimedia compression which would allow for higher compression ratios and increased visual quality. The deep learning approach to multimedia compression, so called Learned Multimedia Compression, involves computing a compressed representation of an image or video using a deep network for the encoder and the decoder. While these techniques have enjoyed impressive academic success, their industry adoption has been essentially non-existent. Classical compression techniques like JPEG and MPEG are too entrenched in modern computing to be easily replaced. This dissertation takes an orthogonal approach and leverages deep learning to improve the compression fidelity of these classical algorithms. This allows the incredible advances in deep learning to be used for multimedia compression without threatening the ubiquity of the classical methods. The key insight of this work is that methods which are motivated by first principles, i.e., the underlying engineering decisions that were made when the compression algorithms were developed, are more effective than general methods. By encoding prior knowledge into the design of the algorithm, the flexibility, performance, and/or accuracy are improved at the cost of generality...
Leveraging Bitstream Metadata for Fast and Accurate Video Compression Correction
Jan 31, 2022Video compression is a central feature of the modern internet powering technologies from social media to video conferencing. While video compression continues to mature, for many, and particularly for extreme, compression settings, quality loss is still noticeable. These extreme settings nevertheless have important applications to the efficient transmission of videos over bandwidth constrained or otherwise unstable connections. In this work, we develop a deep learning architecture capable of restoring detail to compressed videos which leverages the underlying structure and motion information embedded in the video bitstream. We show that this improves restoration accuracy compared to prior compression correction methods and is competitive when compared with recent deep-learning-based video compression methods on rate-distortion while achieving higher throughput.
A Frequency Perspective of Adversarial Robustness
Oct 26, 2021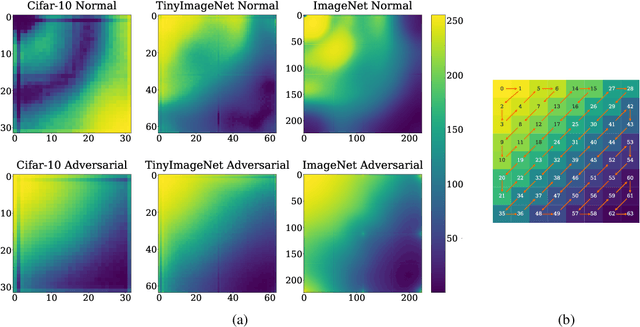
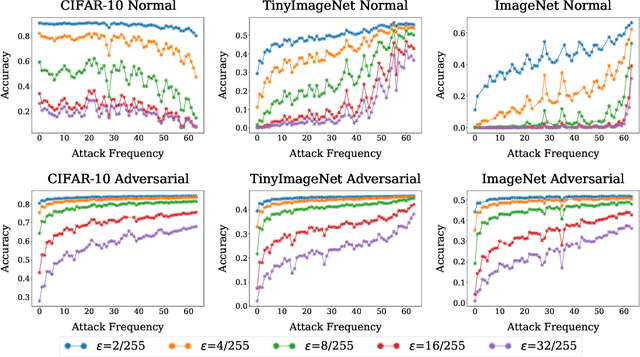

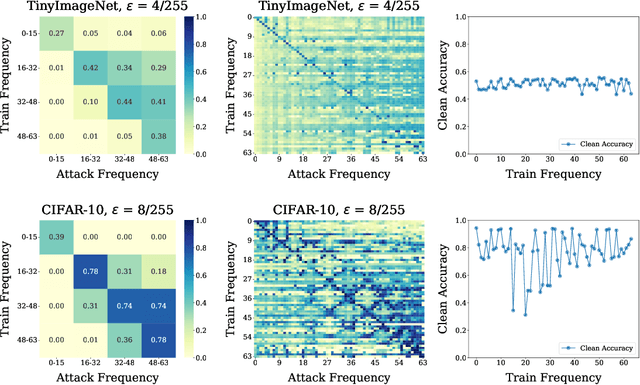
Adversarial examples pose a unique challenge for deep learning systems. Despite recent advances in both attacks and defenses, there is still a lack of clarity and consensus in the community about the true nature and underlying properties of adversarial examples. A deep understanding of these examples can provide new insights towards the development of more effective attacks and defenses. Driven by the common misconception that adversarial examples are high-frequency noise, we present a frequency-based understanding of adversarial examples, supported by theoretical and empirical findings. Our analysis shows that adversarial examples are neither in high-frequency nor in low-frequency components, but are simply dataset dependent. Particularly, we highlight the glaring disparities between models trained on CIFAR-10 and ImageNet-derived datasets. Utilizing this framework, we analyze many intriguing properties of training robust models with frequency constraints, and propose a frequency-based explanation for the commonly observed accuracy vs. robustness trade-off.
Interpretable Automated Diagnosis of Retinal Disease using Deep OCT Analysis
Sep 03, 2021
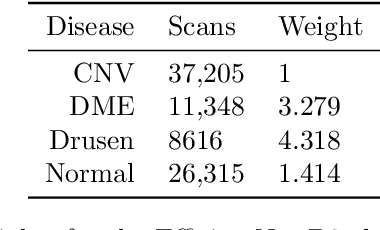


30 million Optical Coherence Tomography (OCT) imaging tests are issued every year to diagnose various retinal diseases, but accurate diagnosis of OCT scans requires trained ophthalmologists who are still prone to making misclassifications. With better systems for diagnosis, many cases of vision loss caused by retinal disease could be entirely avoided. In this work, we developed a CNN-based model for accurate classification of CNV, DME, Drusen, and Normal OCT scans. Furthermore, we placed an emphasis on producing both qualitative and quantitative explanations of the model's decisions. Our class-weighted EfficientNet B2 classification model performed at 99.79% accuracy. We then produced and analyzed heatmaps of where in the OCT scan the model focused. After producing the heatmaps, we created breakdowns of the specific retinal layers the model focused on. While highly accurate models have been previously developed, our work is the first to produce detailed explanations of the model's decisions. The combination of accuracy and interpretability in our work can be clinically applied for better patient care. Future work can use a similar model for classification on larger and more diverse data sets.
Unsupervised Super-Resolution of Satellite Imagery for High Fidelity Material Label Transfer
May 16, 2021


Urban material recognition in remote sensing imagery is a highly relevant, yet extremely challenging problem due to the difficulty of obtaining human annotations, especially on low resolution satellite images. To this end, we propose an unsupervised domain adaptation based approach using adversarial learning. We aim to harvest information from smaller quantities of high resolution data (source domain) and utilize the same to super-resolve low resolution imagery (target domain). This can potentially aid in semantic as well as material label transfer from a richly annotated source to a target domain.
* Published in the proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium