 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBodyMetric: Evaluating the Realism of Human Bodies in Text-to-Image Generation
Dec 06, 2024


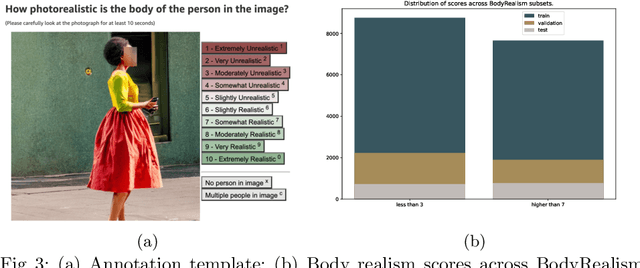
Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
BodyMetric: Evaluating the Realism of HumanBodies in Text-to-Image Generation
Dec 05, 2024Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
Neural Space-filling Curves
Apr 18, 2022



We present Neural Space-filling Curves (SFCs), a data-driven approach to infer a context-based scan order for a set of images. Linear ordering of pixels forms the basis for many applications such as video scrambling, compression, and auto-regressive models that are used in generative modeling for images. Existing algorithms resort to a fixed scanning algorithm such as Raster scan or Hilbert scan. Instead, our work learns a spatially coherent linear ordering of pixels from the dataset of images using a graph-based neural network. The resulting Neural SFC is optimized for an objective suitable for the downstream task when the image is traversed along with the scan line order. We show the advantage of using Neural SFCs in downstream applications such as image compression. Code and additional results will be made available at https://hywang66.github.io/publication/neuralsfc.
Leveraging Bitstream Metadata for Fast and Accurate Video Compression Correction
Jan 31, 2022Video compression is a central feature of the modern internet powering technologies from social media to video conferencing. While video compression continues to mature, for many, and particularly for extreme, compression settings, quality loss is still noticeable. These extreme settings nevertheless have important applications to the efficient transmission of videos over bandwidth constrained or otherwise unstable connections. In this work, we develop a deep learning architecture capable of restoring detail to compressed videos which leverages the underlying structure and motion information embedded in the video bitstream. We show that this improves restoration accuracy compared to prior compression correction methods and is competitive when compared with recent deep-learning-based video compression methods on rate-distortion while achieving higher throughput.
Learning Realistic Human Reposing using Cyclic Self-Supervision with 3D Shape, Pose, and Appearance Consistency
Oct 11, 2021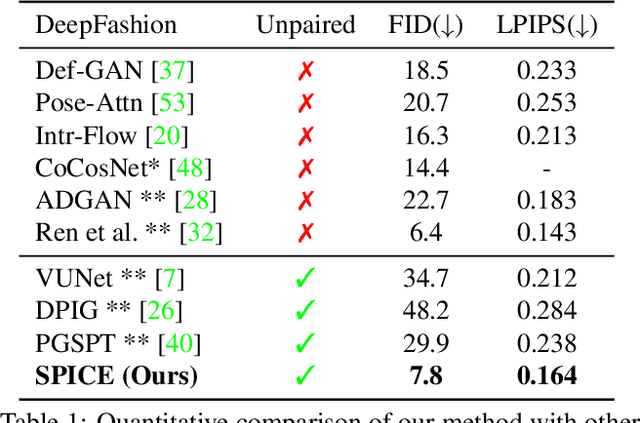
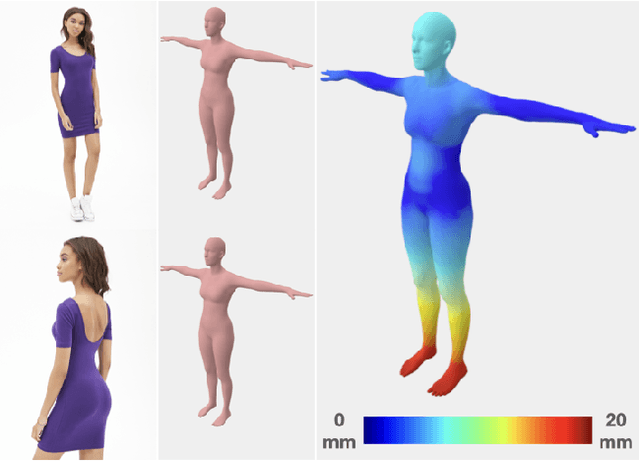

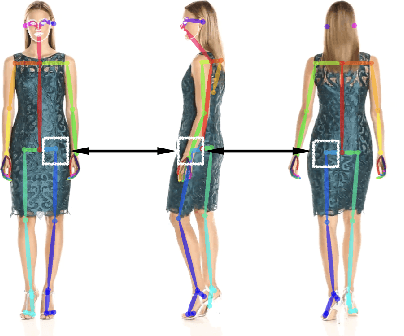
Synthesizing images of a person in novel poses from a single image is a highly ambiguous task. Most existing approaches require paired training images; i.e. images of the same person with the same clothing in different poses. However, obtaining sufficiently large datasets with paired data is challenging and costly. Previous methods that forego paired supervision lack realism. We propose a self-supervised framework named SPICE (Self-supervised Person Image CrEation) that closes the image quality gap with supervised methods. The key insight enabling self-supervision is to exploit 3D information about the human body in several ways. First, the 3D body shape must remain unchanged when reposing. Second, representing body pose in 3D enables reasoning about self occlusions. Third, 3D body parts that are visible before and after reposing, should have similar appearance features. Once trained, SPICE takes an image of a person and generates a new image of that person in a new target pose. SPICE achieves state-of-the-art performance on the DeepFashion dataset, improving the FID score from 29.9 to 7.8 compared with previous unsupervised methods, and with performance similar to the state-of-the-art supervised method (6.4). SPICE also generates temporally coherent videos given an input image and a sequence of poses, despite being trained on static images only.
More Than Just Attention: Learning Cross-Modal Attentions with Contrastive Constraints
May 20, 2021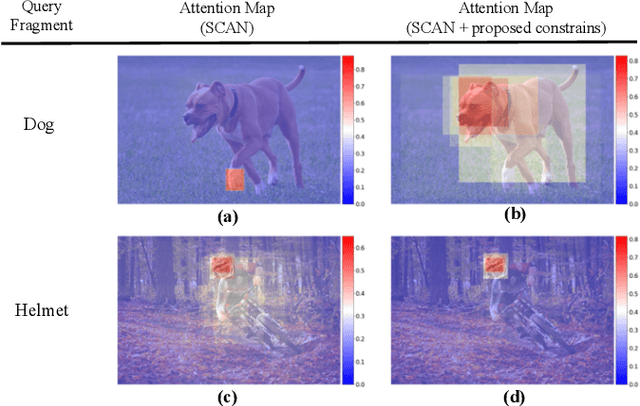
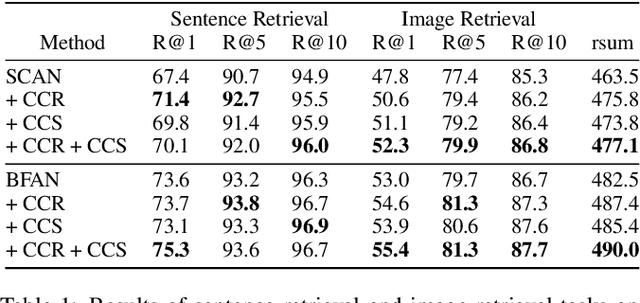
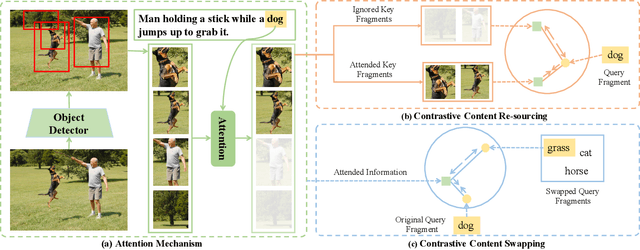
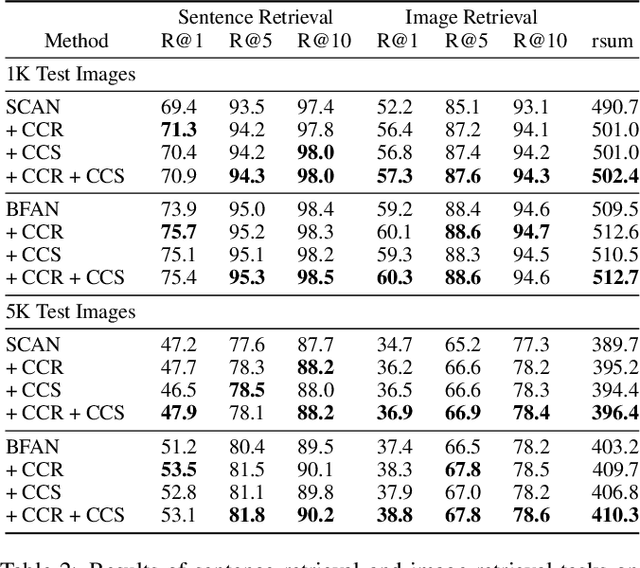
Attention mechanisms have been widely applied to cross-modal tasks such as image captioning and information retrieval, and have achieved remarkable improvements due to its capability to learn fine-grained relevance across different modalities. However, existing attention models could be sub-optimal and lack preciseness because there is no direct supervision involved during training. In this work, we propose Contrastive Content Re-sourcing (CCR) and Contrastive Content Swapping (CCS) constraints to address such limitation. These constraints supervise the training of attention models in a contrastive learning manner without requiring explicit attention annotations. Additionally, we introduce three metrics, namely Attention Precision, Recall and F1-Score, to quantitatively evaluate the attention quality. We evaluate the proposed constraints with cross-modal retrieval (image-text matching) task. The experiments on both Flickr30k and MS-COCO datasets demonstrate that integrating these attention constraints into two state-of-the-art attention-based models improves the model performance in terms of both retrieval accuracy and attention metrics.
Unsupervised Super-Resolution of Satellite Imagery for High Fidelity Material Label Transfer
May 16, 2021


Urban material recognition in remote sensing imagery is a highly relevant, yet extremely challenging problem due to the difficulty of obtaining human annotations, especially on low resolution satellite images. To this end, we propose an unsupervised domain adaptation based approach using adversarial learning. We aim to harvest information from smaller quantities of high resolution data (source domain) and utilize the same to super-resolve low resolution imagery (target domain). This can potentially aid in semantic as well as material label transfer from a richly annotated source to a target domain.
* Published in the proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium
VideoLT: Large-scale Long-tailed Video Recognition
May 06, 2021



Label distributions in real-world are oftentimes long-tailed and imbalanced, resulting in biased models towards dominant labels. While long-tailed recognition has been extensively studied for image classification tasks, limited effort has been made for video domain. In this paper, we introduce VideoLT, a large-scale long-tailed video recognition dataset, as a step toward real-world video recognition. Our VideoLT contains 256,218 untrimmed videos, annotated into 1,004 classes with a long-tailed distribution. Through extensive studies, we demonstrate that state-of-the-art methods used for long-tailed image recognition do not perform well in the video domain due to the additional temporal dimension in video data. This motivates us to propose FrameStack, a simple yet effective method for long-tailed video recognition task. In particular, FrameStack performs sampling at the frame-level in order to balance class distributions, and the sampling ratio is dynamically determined using knowledge derived from the network during training. Experimental results demonstrate that FrameStack can improve classification performance without sacrificing overall accuracy.
M3DeTR: Multi-representation, Multi-scale, Mutual-relation 3D Object Detection with Transformers
Apr 30, 2021



We present a novel architecture for 3D object detection, M3DeTR, which combines different point cloud representations (raw, voxels, bird-eye view) with different feature scales based on multi-scale feature pyramids. M3DeTR is the first approach that unifies multiple point cloud representations, feature scales, as well as models mutual relationships between point clouds simultaneously using transformers. We perform extensive ablation experiments that highlight the benefits of fusing representation and scale, and modeling the relationships. Our method achieves state-of-the-art performance on the KITTI 3D object detection dataset and Waymo Open Dataset. Results show that M3DeTR improves the baseline significantly by 1.48% mAP for all classes on Waymo Open Dataset. In particular, our approach ranks 1st on the well-known KITTI 3D Detection Benchmark for both car and cyclist classes, and ranks 1st on Waymo Open Dataset with single frame point cloud input.
Beyond Short Clips: End-to-End Video-Level Learning with Collaborative Memories
Apr 02, 2021



The standard way of training video models entails sampling at each iteration a single clip from a video and optimizing the clip prediction with respect to the video-level label. We argue that a single clip may not have enough temporal coverage to exhibit the label to recognize, since video datasets are often weakly labeled with categorical information but without dense temporal annotations. Furthermore, optimizing the model over brief clips impedes its ability to learn long-term temporal dependencies. To overcome these limitations, we introduce a collaborative memory mechanism that encodes information across multiple sampled clips of a video at each training iteration. This enables the learning of long-range dependencies beyond a single clip. We explore different design choices for the collaborative memory to ease the optimization difficulties. Our proposed framework is end-to-end trainable and significantly improves the accuracy of video classification at a negligible computational overhead. Through extensive experiments, we demonstrate that our framework generalizes to different video architectures and tasks, outperforming the state of the art on both action recognition (e.g., Kinetics-400 & 700, Charades, Something-Something-V1) and action detection (e.g., AVA v2.1 & v2.2).