 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBodyMetric: Evaluating the Realism of Human Bodies in Text-to-Image Generation
Dec 06, 2024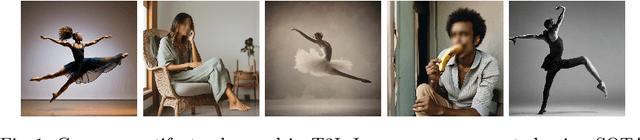


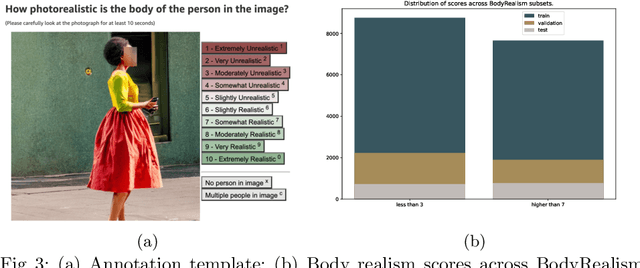
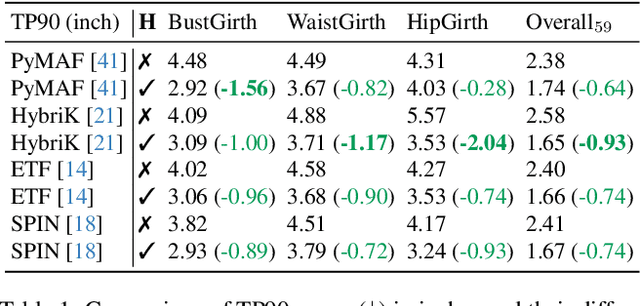
Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
BodyMetric: Evaluating the Realism of HumanBodies in Text-to-Image Generation
Dec 05, 2024Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
A Simple Strategy for Body Estimation from Partial-View Images
Apr 16, 2024
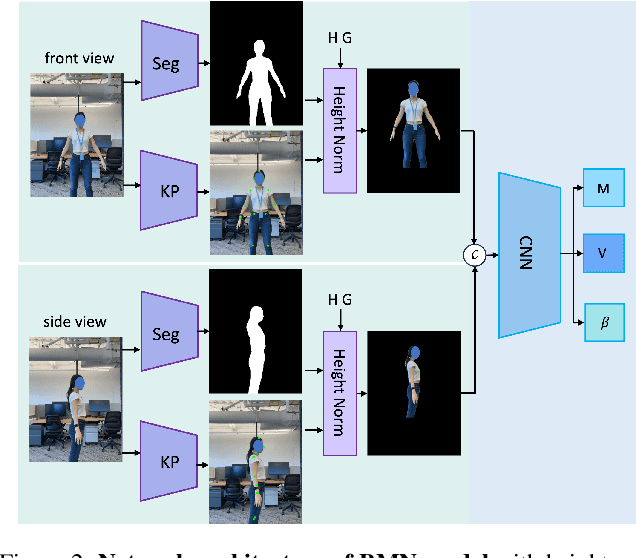
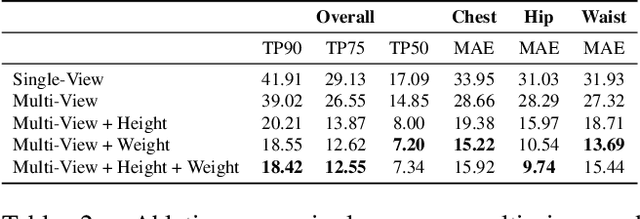
Virtual try-on and product personalization have become increasingly important in modern online shopping, highlighting the need for accurate body measurement estimation. Although previous research has advanced in estimating 3D body shapes from RGB images, the task is inherently ambiguous as the observed scale of human subjects in the images depends on two unknown factors: capture distance and body dimensions. This ambiguity is particularly pronounced in partial-view scenarios. To address this challenge, we propose a modular and simple height normalization solution. This solution relocates the subject skeleton to the desired position, thereby normalizing the scale and disentangling the relationship between the two variables. Our experimental results demonstrate that integrating this technique into state-of-the-art human mesh reconstruction models significantly enhances partial body measurement estimation. Additionally, we illustrate the applicability of this approach to multi-view settings, showcasing its versatility.
MRC-Net: 6-DoF Pose Estimation with MultiScale Residual Correlation
Mar 20, 2024We propose a single-shot approach to determining 6-DoF pose of an object with available 3D computer-aided design (CAD) model from a single RGB image. Our method, dubbed MRC-Net, comprises two stages. The first performs pose classification and renders the 3D object in the classified pose. The second stage performs regression to predict fine-grained residual pose within class. Connecting the two stages is a novel multi-scale residual correlation (MRC) layer that captures high-and-low level correspondences between the input image and rendering from first stage. MRC-Net employs a Siamese network with shared weights between both stages to learn embeddings for input and rendered images. To mitigate ambiguity when predicting discrete pose class labels on symmetric objects, we use soft probabilistic labels to define pose class in the first stage. We demonstrate state-of-the-art accuracy, outperforming all competing RGB-based methods on four challenging BOP benchmark datasets: T-LESS, LM-O, YCB-V, and ITODD. Our method is non-iterative and requires no complex post-processing.
Human Body Measurement Estimation with Adversarial Augmentation
Oct 11, 2022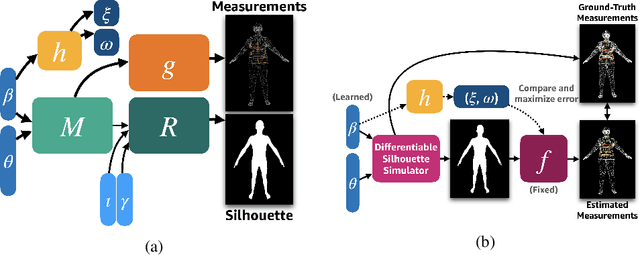
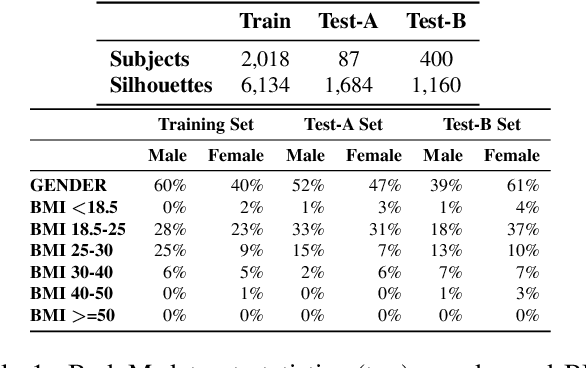
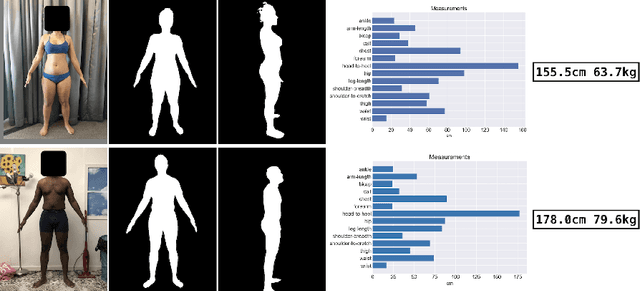
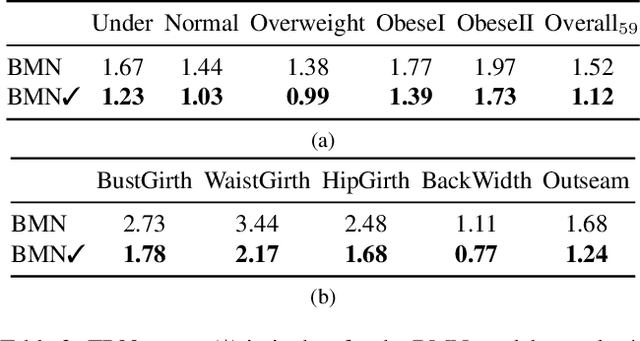
We present a Body Measurement network (BMnet) for estimating 3D anthropomorphic measurements of the human body shape from silhouette images. Training of BMnet is performed on data from real human subjects, and augmented with a novel adversarial body simulator (ABS) that finds and synthesizes challenging body shapes. ABS is based on the skinned multiperson linear (SMPL) body model, and aims to maximize BMnet measurement prediction error with respect to latent SMPL shape parameters. ABS is fully differentiable with respect to these parameters, and trained end-to-end via backpropagation with BMnet in the loop. Experiments show that ABS effectively discovers adversarial examples, such as bodies with extreme body mass indices (BMI), consistent with the rarity of extreme-BMI bodies in BMnet's training set. Thus ABS is able to reveal gaps in training data and potential failures in predicting under-represented body shapes. Results show that training BMnet with ABS improves measurement prediction accuracy on real bodies by up to 10%, when compared to no augmentation or random body shape sampling. Furthermore, our method significantly outperforms SOTA measurement estimation methods by as much as 3x. Finally, we release BodyM, the first challenging, large-scale dataset of photo silhouettes and body measurements of real human subjects, to further promote research in this area. Project website: https://adversarialbodysim.github.io
STRIVE: Scene Text Replacement In Videos
Sep 06, 2021
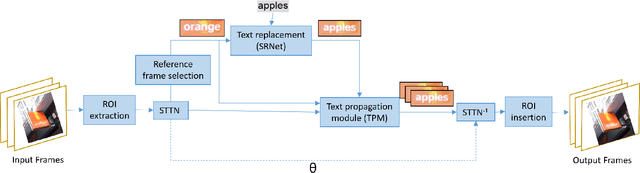
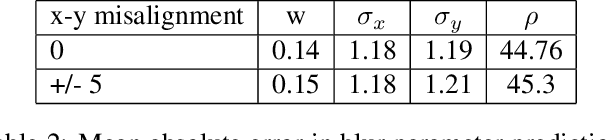
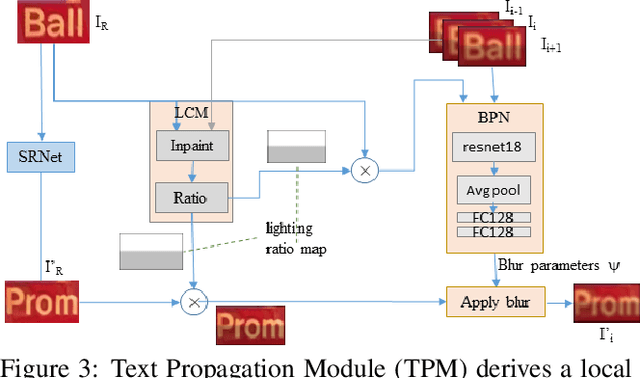
We propose replacing scene text in videos using deep style transfer and learned photometric transformations.Building on recent progress on still image text replacement,we present extensions that alter text while preserving the appearance and motion characteristics of the original video.Compared to the problem of still image text replacement,our method addresses additional challenges introduced by video, namely effects induced by changing lighting, motion blur, diverse variations in camera-object pose over time,and preservation of temporal consistency. We parse the problem into three steps. First, the text in all frames is normalized to a frontal pose using a spatio-temporal trans-former network. Second, the text is replaced in a single reference frame using a state-of-art still-image text replacement method. Finally, the new text is transferred from the reference to remaining frames using a novel learned image transformation network that captures lighting and blur effects in a temporally consistent manner. Results on synthetic and challenging real videos show realistic text trans-fer, competitive quantitative and qualitative performance,and superior inference speed relative to alternatives. We introduce new synthetic and real-world datasets with paired text objects. To the best of our knowledge this is the first attempt at deep video text replacement.
LiDAM: Semi-Supervised Learning with Localized Domain Adaptation and Iterative Matching
Oct 13, 2020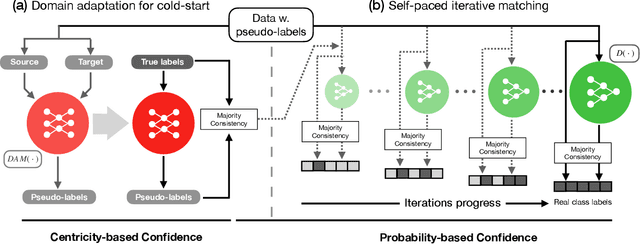
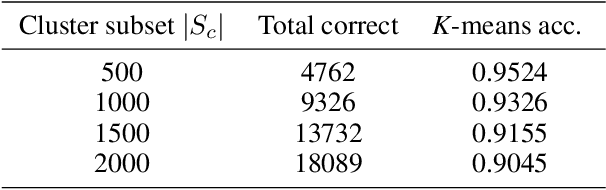
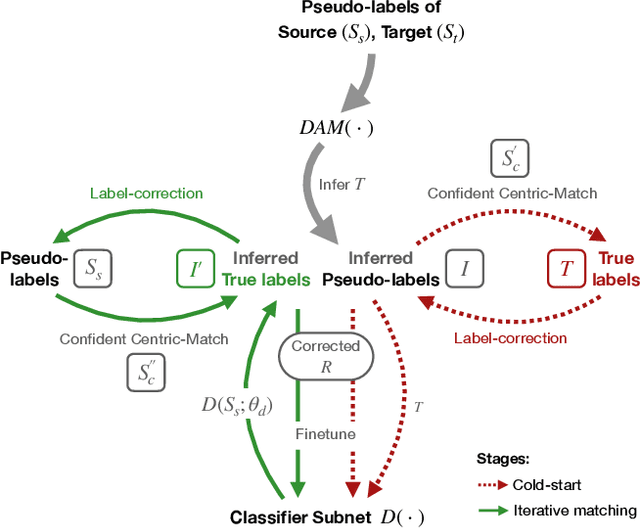
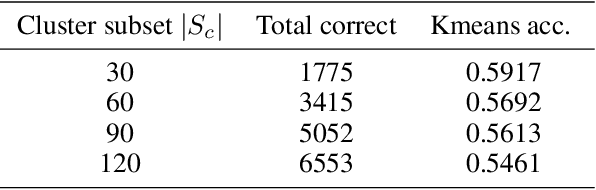
Although data is abundant, data labeling is expensive. Semi-supervised learning methods combine a few labeled samples with a large corpus of unlabeled data to effectively train models. This paper introduces our proposed method LiDAM, a semi-supervised learning approach rooted in both domain adaptation and self-paced learning. LiDAM first performs localized domain shifts to extract better domain-invariant features for the model that results in more accurate clusters and pseudo-labels. These pseudo-labels are then aligned with real class labels in a self-paced fashion using a novel iterative matching technique that is based on majority consistency over high-confidence predictions. Simultaneously, a final classifier is trained to predict ground-truth labels until convergence. LiDAM achieves state-of-the-art performance on the CIFAR-100 dataset, outperforming FixMatch (73.50% vs. 71.82%) when using 2500 labels.
Editing in Style: Uncovering the Local Semantics of GANs
May 21, 2020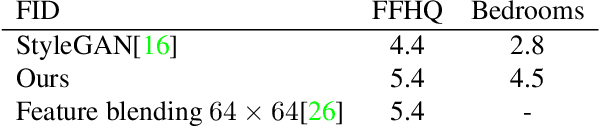



While the quality of GAN image synthesis has improved tremendously in recent years, our ability to control and condition the output is still limited. Focusing on StyleGAN, we introduce a simple and effective method for making local, semantically-aware edits to a target output image. This is accomplished by borrowing elements from a source image, also a GAN output, via a novel manipulation of style vectors. Our method requires neither supervision from an external model, nor involves complex spatial morphing operations. Instead, it relies on the emergent disentanglement of semantic objects that is learned by StyleGAN during its training. Semantic editing is demonstrated on GANs producing human faces, indoor scenes, cats, and cars. We measure the locality and photorealism of the edits produced by our method, and find that it accomplishes both.
Semi-supervised Conditional GANs
Aug 19, 2017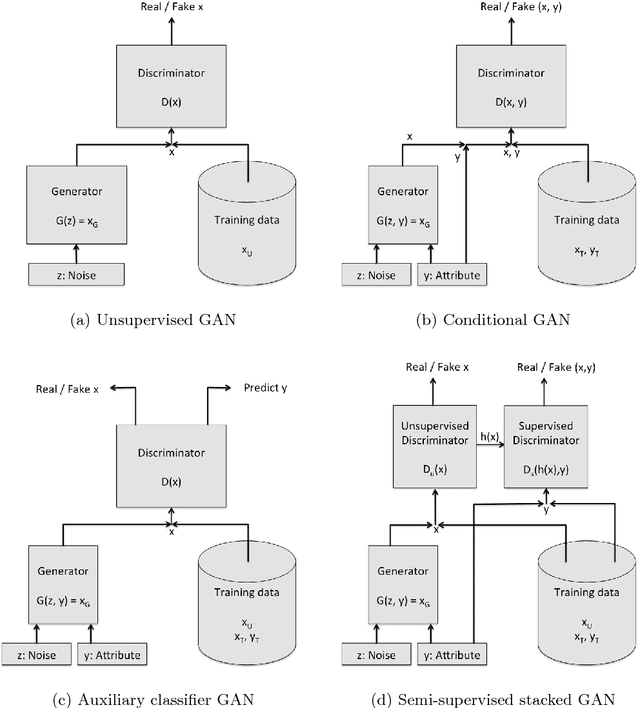
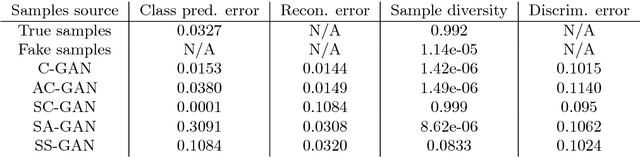
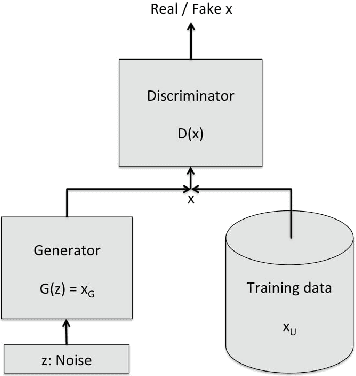
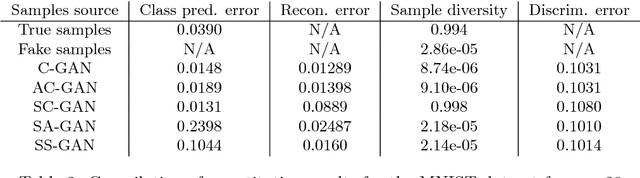
We introduce a new model for building conditional generative models in a semi-supervised setting to conditionally generate data given attributes by adapting the GAN framework. The proposed semi-supervised GAN (SS-GAN) model uses a pair of stacked discriminators to learn the marginal distribution of the data, and the conditional distribution of the attributes given the data respectively. In the semi-supervised setting, the marginal distribution (which is often harder to learn) is learned from the labeled + unlabeled data, and the conditional distribution is learned purely from the labeled data. Our experimental results demonstrate that this model performs significantly better compared to existing semi-supervised conditional GAN models.