 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBodyMetric: Evaluating the Realism of Human Bodies in Text-to-Image Generation
Dec 06, 2024


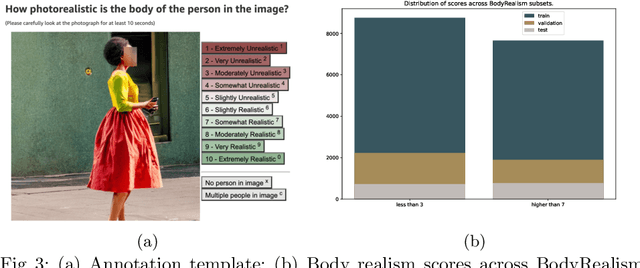
Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
BodyMetric: Evaluating the Realism of HumanBodies in Text-to-Image Generation
Dec 05, 2024Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
Challenges of Zero-Shot Recognition with Vision-Language Models: Granularity and Correctness
Jun 28, 2023



This paper investigates the challenges of applying vision-language models (VLMs) to zero-shot visual recognition tasks in an open-world setting, with a focus on contrastive vision-language models such as CLIP. We first examine the performance of VLMs on concepts of different granularity levels. We propose a way to fairly evaluate the performance discrepancy under two experimental setups and find that VLMs are better at recognizing fine-grained concepts. Furthermore, we find that the similarity scores from VLMs do not strictly reflect the correctness of the textual inputs given visual input. We propose an evaluation protocol to test our hypothesis that the scores can be biased towards more informative descriptions, and the nature of the similarity score between embedding makes it challenging for VLMs to recognize the correctness between similar but wrong descriptions. Our study highlights the challenges of using VLMs in open-world settings and suggests directions for future research to improve their zero-shot capabilities.