 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBodyMetric: Evaluating the Realism of Human Bodies in Text-to-Image Generation
Dec 06, 2024


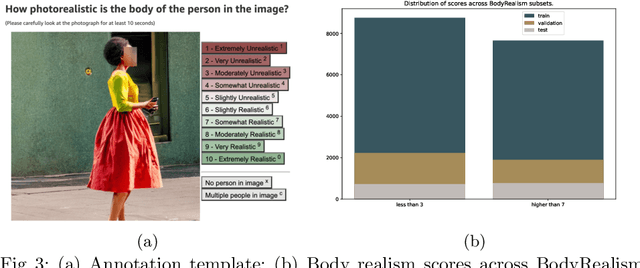
Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
BodyMetric: Evaluating the Realism of HumanBodies in Text-to-Image Generation
Dec 05, 2024Accurately generating images of human bodies from text remains a challenging problem for state of the art text-to-image models. Commonly observed body-related artifacts include extra or missing limbs, unrealistic poses, blurred body parts, etc. Currently, evaluation of such artifacts relies heavily on time-consuming human judgments, limiting the ability to benchmark models at scale. We address this by proposing BodyMetric, a learnable metric that predicts body realism in images. BodyMetric is trained on realism labels and multi-modal signals including 3D body representations inferred from the input image, and textual descriptions. In order to facilitate this approach, we design an annotation pipeline to collect expert ratings on human body realism leading to a new dataset for this task, namely, BodyRealism. Ablation studies support our architectural choices for BodyMetric and the importance of leveraging a 3D human body prior in capturing body-related artifacts in 2D images. In comparison to concurrent metrics which evaluate general user preference in images, BodyMetric specifically reflects body-related artifacts. We demonstrate the utility of BodyMetric through applications that were previously infeasible at scale. In particular, we use BodyMetric to benchmark the generation ability of text-to-image models to produce realistic human bodies. We also demonstrate the effectiveness of BodyMetric in ranking generated images based on the predicted realism scores.
Introspective Cross-Attention Probing for Lightweight Transfer of Pre-trained Models
Mar 07, 2023



We propose InCA, a lightweight method for transfer learning that cross-attends to any activation layer of a pre-trained model. During training, InCA uses a single forward pass to extract multiple activations, which are passed to external cross-attention adapters, trained anew and combined or selected for downstream tasks. We show that, even when selecting a single top-scoring adapter, InCA achieves performance comparable to full fine-tuning, at a cost comparable to fine-tuning just the last layer. For example, with a cross-attention probe 1.3% the size of a pre-trained ViT-L/16 model, we achieve performance within 0.2% of the full fine-tuning paragon at 51% training cost of the baseline, on average across 11 downstream classification tasks. Unlike other forms of efficient adaptation, InCA does not require backpropagating through the pre-trained model, thus leaving its execution unaltered at both training and inference. The versatility of InCA is best illustrated in fine-grained tasks, which may require accessing information absent in the last layer but accessible in intermediate layer activations. Since the backbone is fixed, InCA allows parallel ensembling as well as parallel execution of multiple tasks. InCA achieves state-of-the-art performance in the ImageNet-to-Sketch multi-task benchmark.