 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTraining Domain Draft Models for Speculative Decoding: Best Practices and Insights
Mar 10, 2025



Speculative decoding is an effective method for accelerating inference of large language models (LLMs) by employing a small draft model to predict the output of a target model. However, when adapting speculative decoding to domain-specific target models, the acceptance rate of the generic draft model drops significantly due to domain shift. In this work, we systematically investigate knowledge distillation techniques for training domain draft models to improve their speculation accuracy. We compare white-box and black-box distillation approaches and explore their effectiveness in various data accessibility scenarios, including historical user queries, curated domain data, and synthetically generated alignment data. Our experiments across Function Calling, Biology, and Chinese domains show that offline distillation consistently outperforms online distillation by 11% to 25%, white-box distillation surpasses black-box distillation by 2% to 10%, and data scaling trends hold across domains. Additionally, we find that synthetic data can effectively align draft models and achieve 80% to 93% of the performance of training on historical user queries. These findings provide practical guidelines for training domain-specific draft models to improve speculative decoding efficiency.
Fine Tuning without Catastrophic Forgetting via Selective Low Rank Adaptation
Jan 26, 2025Adapting deep learning models to new domains often requires computationally intensive retraining and risks catastrophic forgetting. While fine-tuning enables domain-specific adaptation, it can reduce robustness to distribution shifts, impacting out-of-distribution (OOD) performance. Pre-trained zero-shot models like CLIP offer strong generalization but may suffer degraded robustness after fine-tuning. Building on Task Adaptive Parameter Sharing (TAPS), we propose a simple yet effective extension as a parameter-efficient fine-tuning (PEFT) method, using an indicator function to selectively activate Low-Rank Adaptation (LoRA) blocks. Our approach minimizes knowledge loss, retains its generalization strengths under domain shifts, and significantly reduces computational costs compared to traditional fine-tuning. We demonstrate that effective fine-tuning can be achieved with as few as 5\% of active blocks, substantially improving efficiency. Evaluations on pre-trained models such as CLIP and DINO-ViT demonstrate our method's broad applicability and effectiveness in maintaining performance and knowledge retention.
CLAP: Unsupervised 3D Representation Learning for Fusion 3D Perception via Curvature Sampling and Prototype Learning
Dec 04, 2024



Unsupervised 3D representation learning via masked-and-reconstruction with differentiable rendering is promising to reduce the labeling burden for fusion 3D perception. However, previous literature conduct pre-training for different modalities separately because of the hight GPU memory consumption. Consequently, the interaction between the two modalities (images and point clouds) is neglected during pre-training. In this paper, we explore joint unsupervised pre-training for fusion 3D perception via differentiable rendering and propose CLAP, short for Curvature sampLing and swApping Prototype assignment prediction. The contributions are three-fold. 1) To overcome the GPU memory consumption problem, we propose Curvature Sampling to sample the more informative points/pixels for pre-training. 2) We propose to use learnable prototypes to represent parts of the scenes in a common feature space and bring the idea of swapping prototype assignment prediction to learn the interaction between the two modalities. 3) To further optimize learnable prototypes, we propose an Expectation-Maximization training scheme to maximize the similarity between embeddings and prototypes, followed by a Gram Matrix Regularization Loss to avoid collapse. Experiment results on NuScenes show that CLAP achieves 300% more performance gain as compared to previous SOTA 3D pre-training method via differentiable rendering. Codes and models will be released.
VLM-KD: Knowledge Distillation from VLM for Long-Tail Visual Recognition
Aug 29, 2024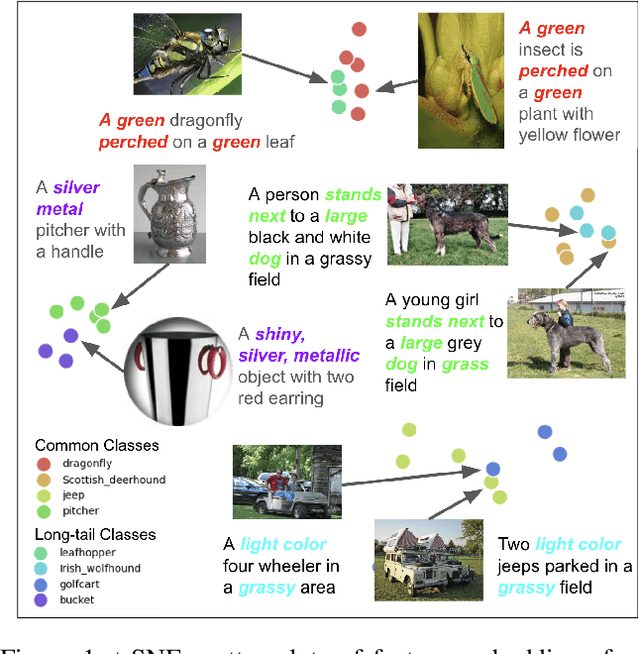
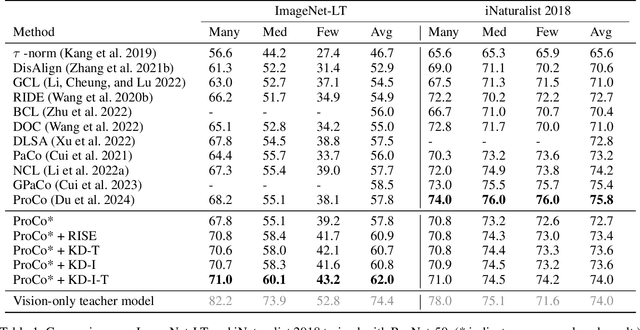
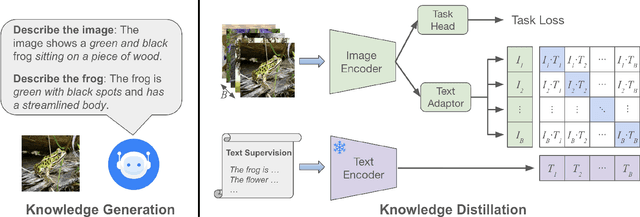
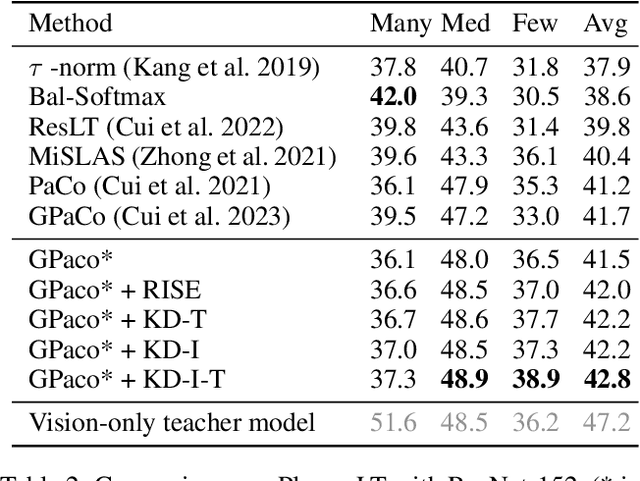
For visual recognition, knowledge distillation typically involves transferring knowledge from a large, well-trained teacher model to a smaller student model. In this paper, we introduce an effective method to distill knowledge from an off-the-shelf vision-language model (VLM), demonstrating that it provides novel supervision in addition to those from a conventional vision-only teacher model. Our key technical contribution is the development of a framework that generates novel text supervision and distills free-form text into a vision encoder. We showcase the effectiveness of our approach, termed VLM-KD, across various benchmark datasets, showing that it surpasses several state-of-the-art long-tail visual classifiers. To our knowledge, this work is the first to utilize knowledge distillation with text supervision generated by an off-the-shelf VLM and apply it to vanilla randomly initialized vision encoders.
InVi: Object Insertion In Videos Using Off-the-Shelf Diffusion Models
Jul 15, 2024

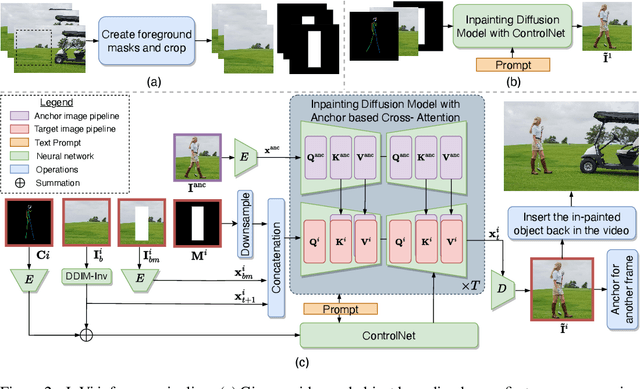

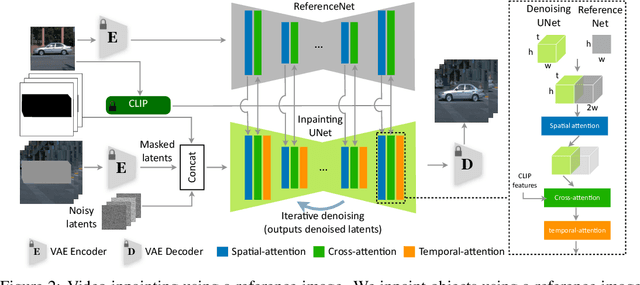
We introduce InVi, an approach for inserting or replacing objects within videos (referred to as inpainting) using off-the-shelf, text-to-image latent diffusion models. InVi targets controlled manipulation of objects and blending them seamlessly into a background video unlike existing video editing methods that focus on comprehensive re-styling or entire scene alterations. To achieve this goal, we tackle two key challenges. Firstly, for high quality control and blending, we employ a two-step process involving inpainting and matching. This process begins with inserting the object into a single frame using a ControlNet-based inpainting diffusion model, and then generating subsequent frames conditioned on features from an inpainted frame as an anchor to minimize the domain gap between the background and the object. Secondly, to ensure temporal coherence, we replace the diffusion model's self-attention layers with extended-attention layers. The anchor frame features serve as the keys and values for these layers, enhancing consistency across frames. Our approach removes the need for video-specific fine-tuning, presenting an efficient and adaptable solution. Experimental results demonstrate that InVi achieves realistic object insertion with consistent blending and coherence across frames, outperforming existing methods.
GenMM: Geometrically and Temporally Consistent Multimodal Data Generation for Video and LiDAR
Jun 15, 2024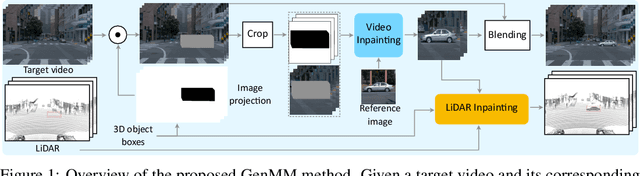
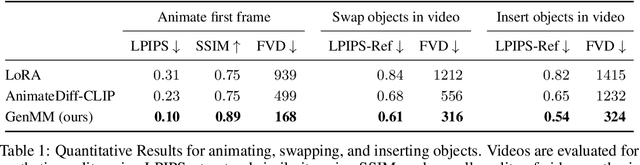

Multimodal synthetic data generation is crucial in domains such as autonomous driving, robotics, augmented/virtual reality, and retail. We propose a novel approach, GenMM, for jointly editing RGB videos and LiDAR scans by inserting temporally and geometrically consistent 3D objects. Our method uses a reference image and 3D bounding boxes to seamlessly insert and blend new objects into target videos. We inpaint the 2D Regions of Interest (consistent with 3D boxes) using a diffusion-based video inpainting model. We then compute semantic boundaries of the object and estimate it's surface depth using state-of-the-art semantic segmentation and monocular depth estimation techniques. Subsequently, we employ a geometry-based optimization algorithm to recover the 3D shape of the object's surface, ensuring it fits precisely within the 3D bounding box. Finally, LiDAR rays intersecting with the new object surface are updated to reflect consistent depths with its geometry. Our experiments demonstrate the effectiveness of GenMM in inserting various 3D objects across video and LiDAR modalities.
Learning Expressive Prompting With Residuals for Vision Transformers
Mar 27, 2023Prompt learning is an efficient approach to adapt transformers by inserting learnable set of parameters into the input and intermediate representations of a pre-trained model. In this work, we present Expressive Prompts with Residuals (EXPRES) which modifies the prompt learning paradigm specifically for effective adaptation of vision transformers (ViT). Out method constructs downstream representations via learnable ``output'' tokens, that are akin to the learned class tokens of the ViT. Further for better steering of the downstream representation processed by the frozen transformer, we introduce residual learnable tokens that are added to the output of various computations. We apply EXPRES for image classification, few shot learning, and semantic segmentation, and show our method is capable of achieving state of the art prompt tuning on 3/3 categories of the VTAB benchmark. In addition to strong performance, we observe that our approach is an order of magnitude more prompt efficient than existing visual prompting baselines. We analytically show the computational benefits of our approach over weight space adaptation techniques like finetuning. Lastly we systematically corroborate the architectural design of our method via a series of ablation experiments.
WinCLIP: Zero-/Few-Shot Anomaly Classification and Segmentation
Mar 26, 2023Visual anomaly classification and segmentation are vital for automating industrial quality inspection. The focus of prior research in the field has been on training custom models for each quality inspection task, which requires task-specific images and annotation. In this paper we move away from this regime, addressing zero-shot and few-normal-shot anomaly classification and segmentation. Recently CLIP, a vision-language model, has shown revolutionary generality with competitive zero-/few-shot performance in comparison to full-supervision. But CLIP falls short on anomaly classification and segmentation tasks. Hence, we propose window-based CLIP (WinCLIP) with (1) a compositional ensemble on state words and prompt templates and (2) efficient extraction and aggregation of window/patch/image-level features aligned with text. We also propose its few-normal-shot extension WinCLIP+, which uses complementary information from normal images. In MVTec-AD (and VisA), without further tuning, WinCLIP achieves 91.8%/85.1% (78.1%/79.6%) AUROC in zero-shot anomaly classification and segmentation while WinCLIP+ does 93.1%/95.2% (83.8%/96.4%) in 1-normal-shot, surpassing state-of-the-art by large margins.
Introspective Cross-Attention Probing for Lightweight Transfer of Pre-trained Models
Mar 07, 2023



We propose InCA, a lightweight method for transfer learning that cross-attends to any activation layer of a pre-trained model. During training, InCA uses a single forward pass to extract multiple activations, which are passed to external cross-attention adapters, trained anew and combined or selected for downstream tasks. We show that, even when selecting a single top-scoring adapter, InCA achieves performance comparable to full fine-tuning, at a cost comparable to fine-tuning just the last layer. For example, with a cross-attention probe 1.3% the size of a pre-trained ViT-L/16 model, we achieve performance within 0.2% of the full fine-tuning paragon at 51% training cost of the baseline, on average across 11 downstream classification tasks. Unlike other forms of efficient adaptation, InCA does not require backpropagating through the pre-trained model, thus leaving its execution unaltered at both training and inference. The versatility of InCA is best illustrated in fine-grained tasks, which may require accessing information absent in the last layer but accessible in intermediate layer activations. Since the backbone is fixed, InCA allows parallel ensembling as well as parallel execution of multiple tasks. InCA achieves state-of-the-art performance in the ImageNet-to-Sketch multi-task benchmark.
A Meta-Learning Approach to Predicting Performance and Data Requirements
Mar 02, 2023We propose an approach to estimate the number of samples required for a model to reach a target performance. We find that the power law, the de facto principle to estimate model performance, leads to large error when using a small dataset (e.g., 5 samples per class) for extrapolation. This is because the log-performance error against the log-dataset size follows a nonlinear progression in the few-shot regime followed by a linear progression in the high-shot regime. We introduce a novel piecewise power law (PPL) that handles the two data regimes differently. To estimate the parameters of the PPL, we introduce a random forest regressor trained via meta learning that generalizes across classification/detection tasks, ResNet/ViT based architectures, and random/pre-trained initializations. The PPL improves the performance estimation on average by 37% across 16 classification and 33% across 10 detection datasets, compared to the power law. We further extend the PPL to provide a confidence bound and use it to limit the prediction horizon that reduces over-estimation of data by 76% on classification and 91% on detection datasets.