 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenMM: Geometrically and Temporally Consistent Multimodal Data Generation for Video and LiDAR
Jun 15, 2024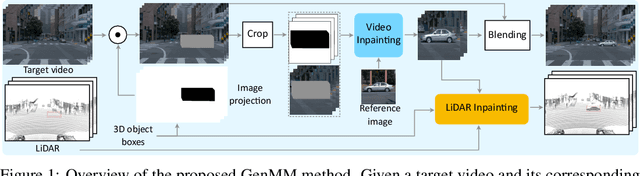
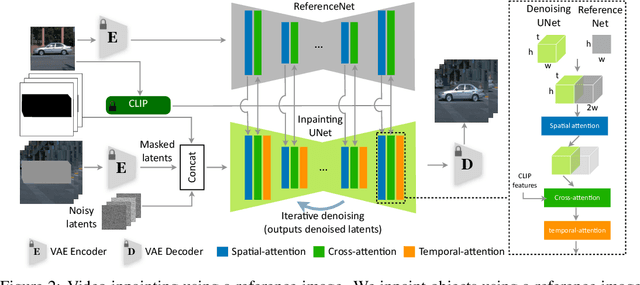

Multimodal synthetic data generation is crucial in domains such as autonomous driving, robotics, augmented/virtual reality, and retail. We propose a novel approach, GenMM, for jointly editing RGB videos and LiDAR scans by inserting temporally and geometrically consistent 3D objects. Our method uses a reference image and 3D bounding boxes to seamlessly insert and blend new objects into target videos. We inpaint the 2D Regions of Interest (consistent with 3D boxes) using a diffusion-based video inpainting model. We then compute semantic boundaries of the object and estimate it's surface depth using state-of-the-art semantic segmentation and monocular depth estimation techniques. Subsequently, we employ a geometry-based optimization algorithm to recover the 3D shape of the object's surface, ensuring it fits precisely within the 3D bounding box. Finally, LiDAR rays intersecting with the new object surface are updated to reflect consistent depths with its geometry. Our experiments demonstrate the effectiveness of GenMM in inserting various 3D objects across video and LiDAR modalities.
Multi-Hypothesis Pose Networks: Rethinking Top-Down Pose Estimation
Jan 27, 2021
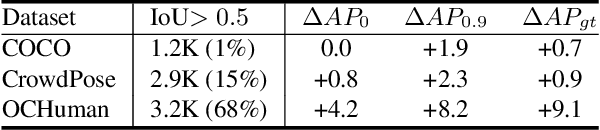
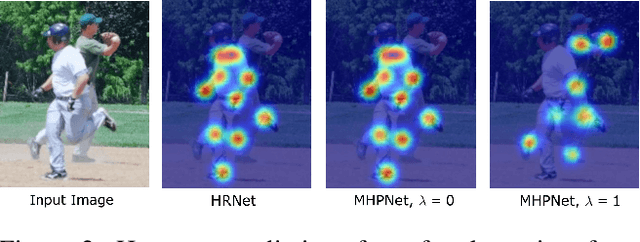
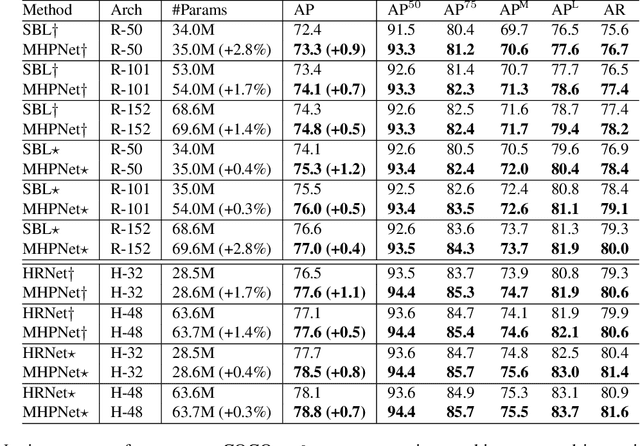
A key assumption of top-down human pose estimation approaches is their expectation of having a single person present in the input bounding box. This often leads to failures in crowded scenes with occlusions. We propose a novel solution to overcome the limitations of this fundamental assumption. Our Multi-Hypothesis Pose Network (MHPNet) allows for predicting multiple 2D poses within a given bounding box. We introduce a Multi-Hypothesis Attention Block (MHAB) that can adaptively modulate channel-wise feature responses for each hypothesis and is parameter efficient. We demonstrate the efficacy of our approach by evaluating on COCO, CrowdPose, and OCHuman datasets. Specifically, we achieve 70.0 AP on CrowdPose and 42.5 AP on OCHuman test sets, a significant improvement of 2.4 AP and 6.5 AP over the prior art, respectively. When using ground truth bounding boxes for inference, MHPNet achieves an improvement of 0.7 AP on COCO, 0.9 AP on CrowdPose, and 9.1 AP on OCHuman validation sets compared to HRNet. Interestingly, when fewer, high confidence bounding boxes are used, HRNet's performance degrades (by 5 AP) on OCHuman, whereas MHPNet maintains a relatively stable performance (a drop of 1 AP) for the same inputs.
PoseNet3D: Unsupervised 3D Human Shape and Pose Estimation
Mar 07, 2020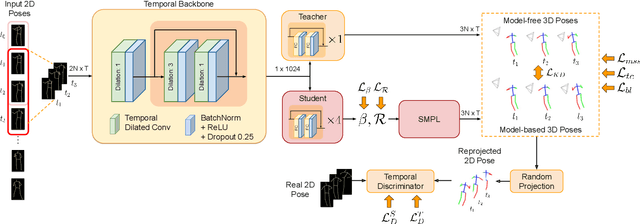
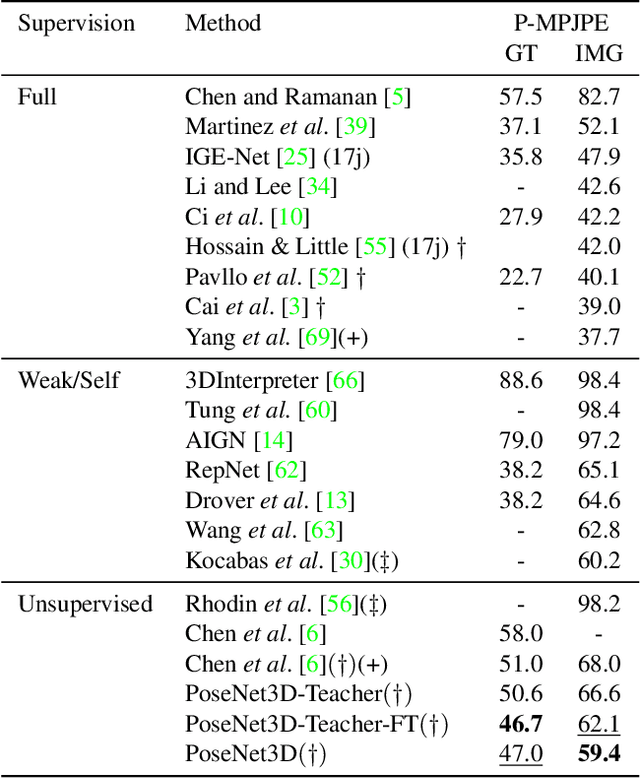
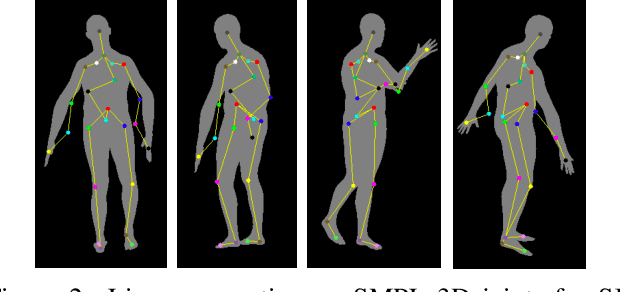
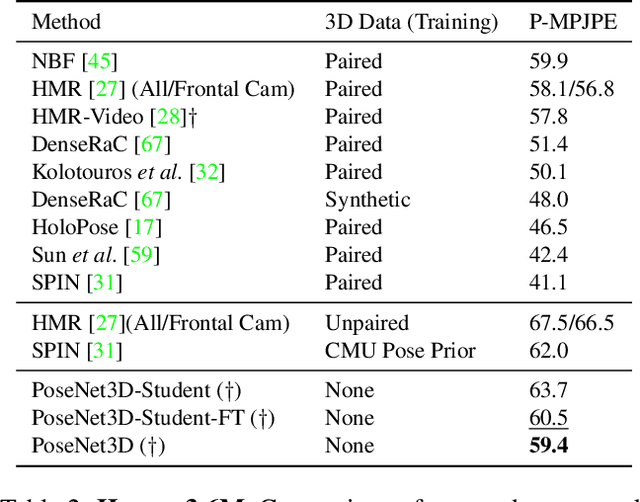
Recovering 3D human pose from 2D joints is a highly unconstrained problem. We propose a novel neural network framework, PoseNet3D, that takes 2D joints as input and outputs 3D skeletons and SMPL body model parameters. By casting our learning approach in a student-teacher framework, we avoid using any 3D data such as paired/unpaired 3D data, motion capture sequences, depth images or multi-view images during training. We first train a teacher network that outputs 3D skeletons, using only 2D poses for training. The teacher network distills its knowledge to a student network that predicts 3D pose in SMPL representation. Finally, both the teacher and the student networks are jointly fine-tuned in an end-to-end manner using temporal, self-consistency and adversarial losses, improving the accuracy of each individual network. Results on Human3.6M dataset for 3D human pose estimation demonstrate that our approach reduces the 3D joint prediction error by 18\% compared to previous unsupervised methods. Qualitative results on in-the-wild datasets show that the recovered 3D poses and meshes are natural, realistic, and flow smoothly over consecutive frames.
Learning to Generate Synthetic Data via Compositing
Apr 10, 2019

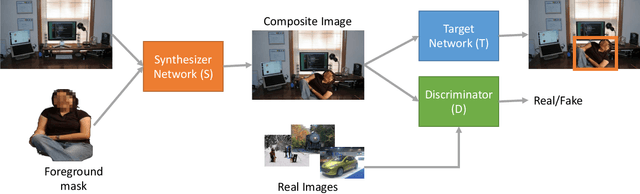
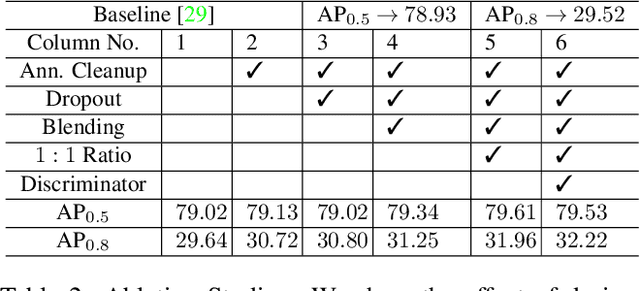
We present a task-aware approach to synthetic data generation. Our framework employs a trainable synthesizer network that is optimized to produce meaningful training samples by assessing the strengths and weaknesses of a `target' network. The synthesizer and target networks are trained in an adversarial manner wherein each network is updated with a goal to outdo the other. Additionally, we ensure the synthesizer generates realistic data by pairing it with a discriminator trained on real-world images. Further, to make the target classifier invariant to blending artefacts, we introduce these artefacts to background regions of the training images so the target does not over-fit to them. We demonstrate the efficacy of our approach by applying it to different target networks including a classification network on AffNIST, and two object detection networks (SSD, Faster-RCNN) on different datasets. On the AffNIST benchmark, our approach is able to surpass the baseline results with just half the training examples. On the VOC person detection benchmark, we show improvements of up to 2.7% as a result of our data augmentation. Similarly on the GMU detection benchmark, we report a performance boost of 3.5% in mAP over the baseline method, outperforming the previous state of the art approaches by up to 7.5% on specific categories.
Unsupervised 3D Pose Estimation with Geometric Self-Supervision
Apr 09, 2019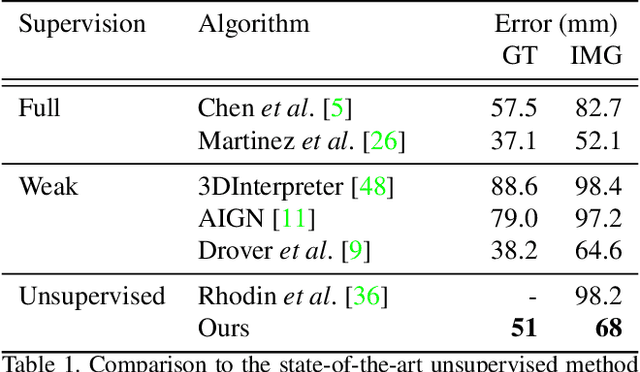
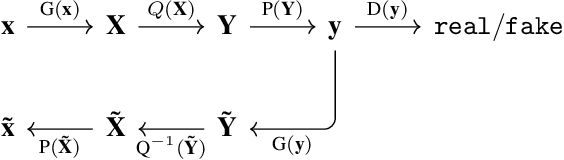
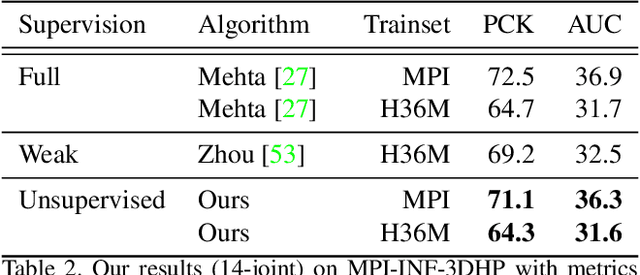
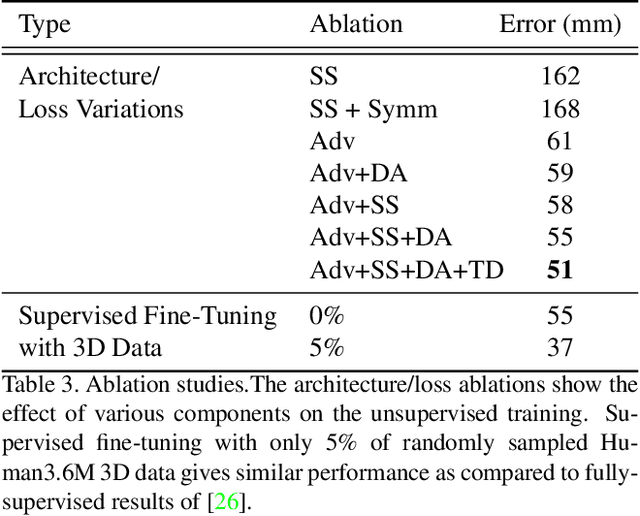
We present an unsupervised learning approach to recover 3D human pose from 2D skeletal joints extracted from a single image. Our method does not require any multi-view image data, 3D skeletons, correspondences between 2D-3D points, or use previously learned 3D priors during training. A lifting network accepts 2D landmarks as inputs and generates a corresponding 3D skeleton estimate. During training, the recovered 3D skeleton is reprojected on random camera viewpoints to generate new "synthetic" 2D poses. By lifting the synthetic 2D poses back to 3D and re-projecting them in the original camera view, we can define self-consistency loss both in 3D and in 2D. The training can thus be self supervised by exploiting the geometric self-consistency of the lift-reproject-lift process. We show that self-consistency alone is not sufficient to generate realistic skeletons, however adding a 2D pose discriminator enables the lifter to output valid 3D poses. Additionally, to learn from 2D poses "in the wild", we train an unsupervised 2D domain adapter network to allow for an expansion of 2D data. This improves results and demonstrates the usefulness of 2D pose data for unsupervised 3D lifting. Results on Human3.6M dataset for 3D human pose estimation demonstrate that our approach improves upon the previous unsupervised methods by 30% and outperforms many weakly supervised approaches that explicitly use 3D data.
CRAFT: Complementary Recommendations Using Adversarial Feature Transformer
Sep 10, 2018
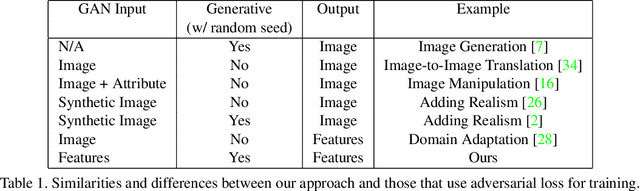
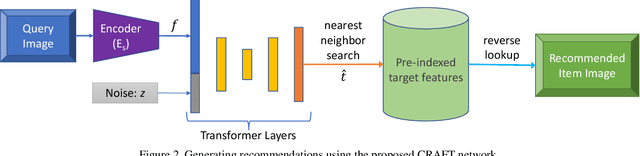
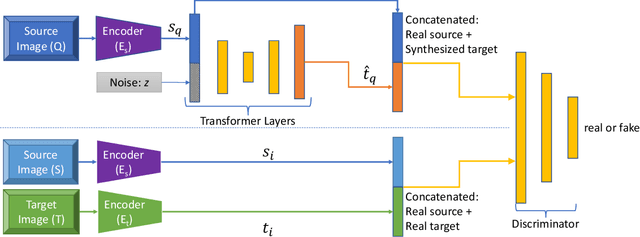
Traditional approaches for complementary product recommendations rely on behavioral and non-visual data such as customer co-views or co-buys. However, certain domains such as fashion are primarily visual. We propose a framework that harnesses visual cues in an unsupervised manner to learn the distribution of co-occurring complementary items in real world images. Our model learns a non-linear transformation between the two manifolds of source and target complementary item categories (e.g., tops and bottoms in outfits). Given a large dataset of images containing instances of co-occurring object categories, we train a generative transformer network directly on the feature representation space by casting it as an adversarial optimization problem. Such a conditional generative model can produce multiple novel samples of complementary items (in the feature space) for a given query item. The final recommendations are selected from the closest real world examples to the synthesized complementary features. We apply our framework to the task of recommending complementary tops for a given bottom clothing item. The recommendations made by our system are diverse, and are favored by human experts over the baseline approaches.
Can 3D Pose be Learned from 2D Projections Alone?
Aug 22, 2018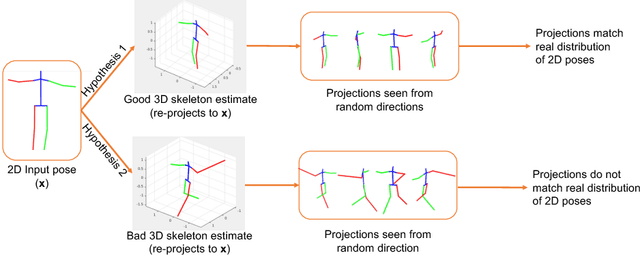
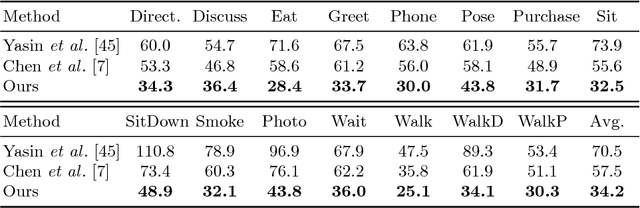
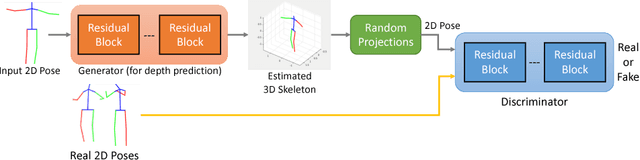
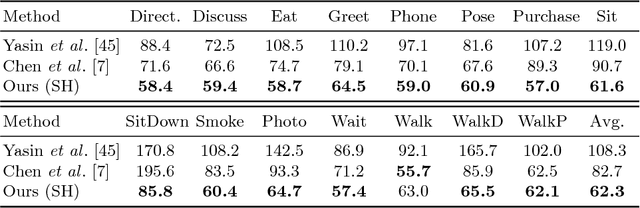
3D pose estimation from a single image is a challenging task in computer vision. We present a weakly supervised approach to estimate 3D pose points, given only 2D pose landmarks. Our method does not require correspondences between 2D and 3D points to build explicit 3D priors. We utilize an adversarial framework to impose a prior on the 3D structure, learned solely from their random 2D projections. Given a set of 2D pose landmarks, the generator network hypothesizes their depths to obtain a 3D skeleton. We propose a novel Random Projection layer, which randomly projects the generated 3D skeleton and sends the resulting 2D pose to the discriminator. The discriminator improves by discriminating between the generated poses and pose samples from a real distribution of 2D poses. Training does not require correspondence between the 2D inputs to either the generator or the discriminator. We apply our approach to the task of 3D human pose estimation. Results on Human3.6M dataset demonstrates that our approach outperforms many previous supervised and weakly supervised approaches.
Context Encoding for Semantic Segmentation
Mar 23, 2018
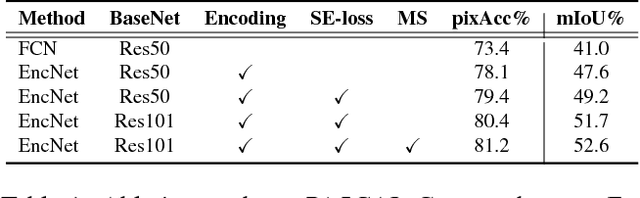
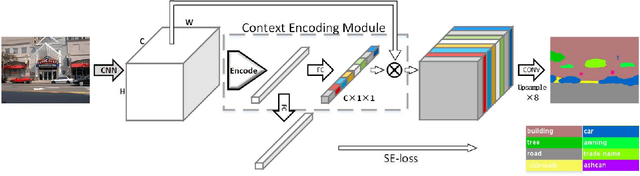
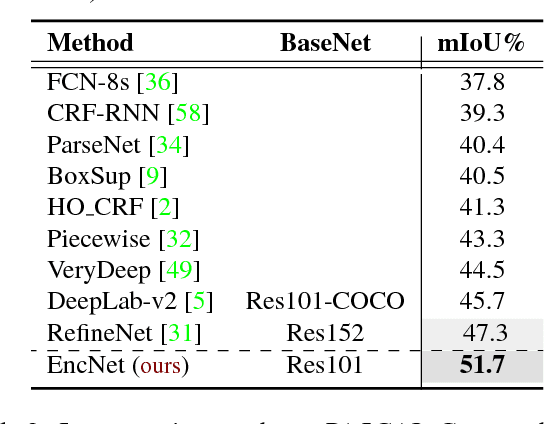
Recent work has made significant progress in improving spatial resolution for pixelwise labeling with Fully Convolutional Network (FCN) framework by employing Dilated/Atrous convolution, utilizing multi-scale features and refining boundaries. In this paper, we explore the impact of global contextual information in semantic segmentation by introducing the Context Encoding Module, which captures the semantic context of scenes and selectively highlights class-dependent featuremaps. The proposed Context Encoding Module significantly improves semantic segmentation results with only marginal extra computation cost over FCN. Our approach has achieved new state-of-the-art results 51.7% mIoU on PASCAL-Context, 85.9% mIoU on PASCAL VOC 2012. Our single model achieves a final score of 0.5567 on ADE20K test set, which surpass the winning entry of COCO-Place Challenge in 2017. In addition, we also explore how the Context Encoding Module can improve the feature representation of relatively shallow networks for the image classification on CIFAR-10 dataset. Our 14 layer network has achieved an error rate of 3.45%, which is comparable with state-of-the-art approaches with over 10 times more layers. The source code for the complete system are publicly available.
DSSD : Deconvolutional Single Shot Detector
Jan 23, 2017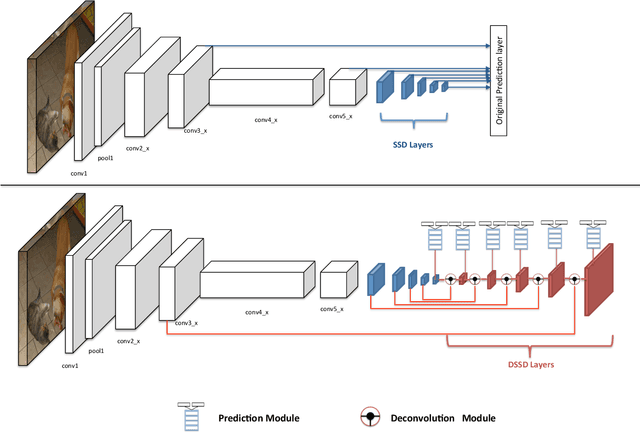
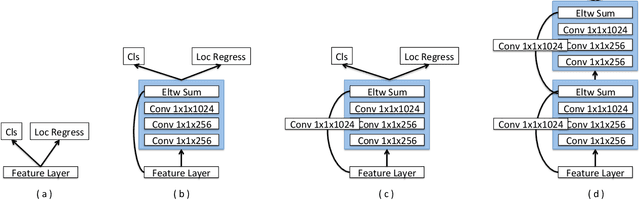
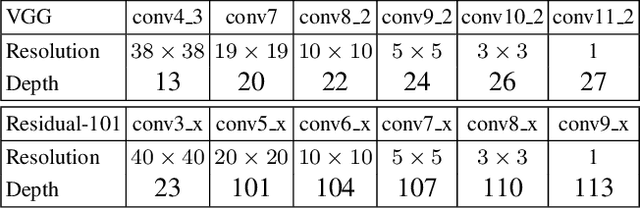
The main contribution of this paper is an approach for introducing additional context into state-of-the-art general object detection. To achieve this we first combine a state-of-the-art classifier (Residual-101[14]) with a fast detection framework (SSD[18]). We then augment SSD+Residual-101 with deconvolution layers to introduce additional large-scale context in object detection and improve accuracy, especially for small objects, calling our resulting system DSSD for deconvolutional single shot detector. While these two contributions are easily described at a high-level, a naive implementation does not succeed. Instead we show that carefully adding additional stages of learned transformations, specifically a module for feed-forward connections in deconvolution and a new output module, enables this new approach and forms a potential way forward for further detection research. Results are shown on both PASCAL VOC and COCO detection. Our DSSD with $513 \times 513$ input achieves 81.5% mAP on VOC2007 test, 80.0% mAP on VOC2012 test, and 33.2% mAP on COCO, outperforming a state-of-the-art method R-FCN[3] on each dataset.