 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Hypothesis Pose Networks: Rethinking Top-Down Pose Estimation
Paper and Code

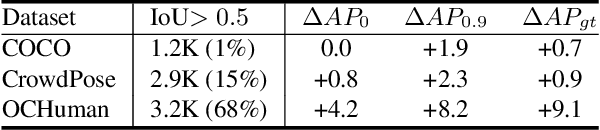
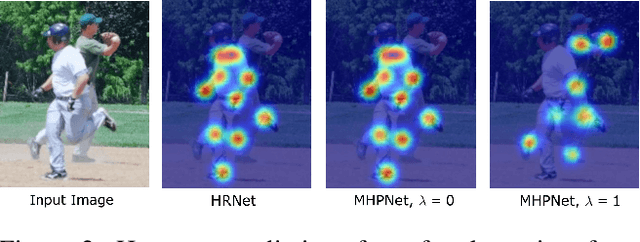
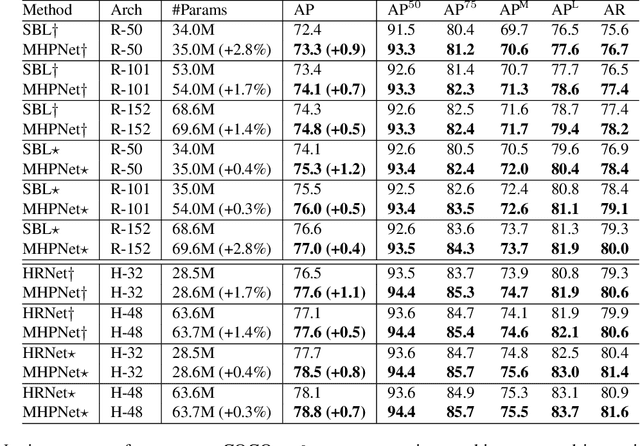
A key assumption of top-down human pose estimation approaches is their expectation of having a single person present in the input bounding box. This often leads to failures in crowded scenes with occlusions. We propose a novel solution to overcome the limitations of this fundamental assumption. Our Multi-Hypothesis Pose Network (MHPNet) allows for predicting multiple 2D poses within a given bounding box. We introduce a Multi-Hypothesis Attention Block (MHAB) that can adaptively modulate channel-wise feature responses for each hypothesis and is parameter efficient. We demonstrate the efficacy of our approach by evaluating on COCO, CrowdPose, and OCHuman datasets. Specifically, we achieve 70.0 AP on CrowdPose and 42.5 AP on OCHuman test sets, a significant improvement of 2.4 AP and 6.5 AP over the prior art, respectively. When using ground truth bounding boxes for inference, MHPNet achieves an improvement of 0.7 AP on COCO, 0.9 AP on CrowdPose, and 9.1 AP on OCHuman validation sets compared to HRNet. Interestingly, when fewer, high confidence bounding boxes are used, HRNet's performance degrades (by 5 AP) on OCHuman, whereas MHPNet maintains a relatively stable performance (a drop of 1 AP) for the same inputs.