 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysical Object Understanding with a Physically Controllable World Model
May 30, 2026A central challenge in visual intelligence is learning the physical structure of scenes from raw videos: how regions form objects and the laws that govern their interactions. Solving these tasks requires world models capable of inferring distributional states of the world from partial observations - capabilities that current architectures do not provide. We introduce a new class of probabilistic world models that support estimation of the probability of any visual variable, such as appearance and dynamics, conditioned on any other variables. Here, we identify that these models can be trained efficiently with autoregressive sequence modeling, yielding world models from which rich object understanding emerges. First, we demonstrate that our model captures the physical laws governing how objects move by generating multiple plausible future states of the world through sequential inference. Then, by analyzing motion correlations across these futures, we extract objects and articulated object subparts. Having discovered these objects, we show that our world model can manipulate them in 3D. Finally, we demonstrate how physical relationships between objects can be computed from the world model, enabling applications such as Visual Jenga.
$Δ$ynamics: Language-Based Representation for Inferring Rigid-Body Dynamics From Videos
May 20, 2026Inferring rigid-body physical states and properties from monocular videos is a fundamental step toward physics-based perception and simulation. Existing approaches assume specific underlying physical systems, object types, and camera poses, making them unable to generalize to complex real-world settings. We introduce $Δ$YNAMICS, a vision-language framework that uses language as a unified representation of rigid-body dynamics. Instead of directly predicting parameters, $Δ$YNAMICS generates scene configurations in a structured text format for physics simulation. We enhance the model's generalization by integrating natural language motion reasoning and leveraging optical flow as a semantic-agnostic input. On the CLEVRER dataset, $Δ$YNAMICS achieves a segmentation IoU of 0.30, a 7x improvement over leading VLMs (InternVL3-8B, Qwen2.5-VL-7B and Claude-4-Sonnet). Additionally, test-time sampling and evolutionary search further boost performance by 27% and 120% in segmentation IoU, respectively. Finally, we demonstrate strong transfer to a new dataset of 235 real-world rigid-body videos, highlighting the potential of language-driven physics inference for bridging perception and simulation.
Autoregressive Flow Matching for Motion Prediction
Dec 27, 2025Motion prediction has been studied in different contexts with models trained on narrow distributions and applied to downstream tasks in human motion prediction and robotics. Simultaneously, recent efforts in scaling video prediction have demonstrated impressive visual realism, yet they struggle to accurately model complex motions despite massive scale. Inspired by the scaling of video generation, we develop autoregressive flow matching (ARFM), a new method for probabilistic modeling of sequential continuous data and train it on diverse video datasets to generate future point track locations over long horizons. To evaluate our model, we develop benchmarks for evaluating the ability of motion prediction models to predict human and robot motion. Our model is able to predict complex motions, and we demonstrate that conditioning robot action prediction and human motion prediction on predicted future tracks can significantly improve downstream task performance. Code and models publicly available at: https://github.com/Johnathan-Xie/arfm-motion-prediction.
Weakly-Supervised Learning of Dense Functional Correspondences
Sep 04, 2025Establishing dense correspondences across image pairs is essential for tasks such as shape reconstruction and robot manipulation. In the challenging setting of matching across different categories, the function of an object, i.e., the effect that an object can cause on other objects, can guide how correspondences should be established. This is because object parts that enable specific functions often share similarities in shape and appearance. We derive the definition of dense functional correspondence based on this observation and propose a weakly-supervised learning paradigm to tackle the prediction task. The main insight behind our approach is that we can leverage vision-language models to pseudo-label multi-view images to obtain functional parts. We then integrate this with dense contrastive learning from pixel correspondences to distill both functional and spatial knowledge into a new model that can establish dense functional correspondence. Further, we curate synthetic and real evaluation datasets as task benchmarks. Our results demonstrate the advantages of our approach over baseline solutions consisting of off-the-shelf self-supervised image representations and grounded vision language models.
MEBench: A Novel Benchmark for Understanding Mutual Exclusivity Bias in Vision-Language Models
May 26, 2025


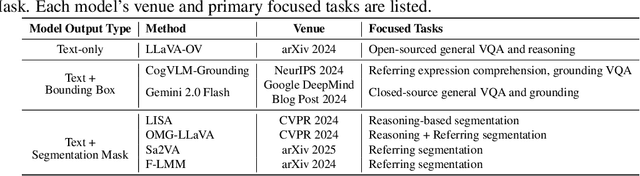
This paper introduces MEBench, a novel benchmark for evaluating mutual exclusivity (ME) bias, a cognitive phenomenon observed in children during word learning. Unlike traditional ME tasks, MEBench further incorporates spatial reasoning to create more challenging and realistic evaluation settings. We assess the performance of state-of-the-art vision-language models (VLMs) on this benchmark using novel evaluation metrics that capture key aspects of ME-based reasoning. To facilitate controlled experimentation, we also present a flexible and scalable data generation pipeline that supports the construction of diverse annotated scenes.
Self-Supervised Learning of Motion Concepts by Optimizing Counterfactuals
Mar 25, 2025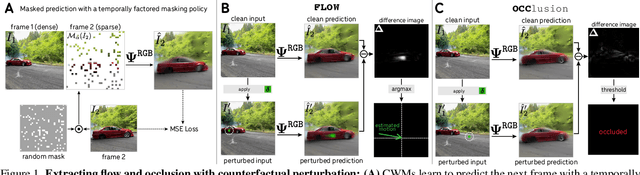
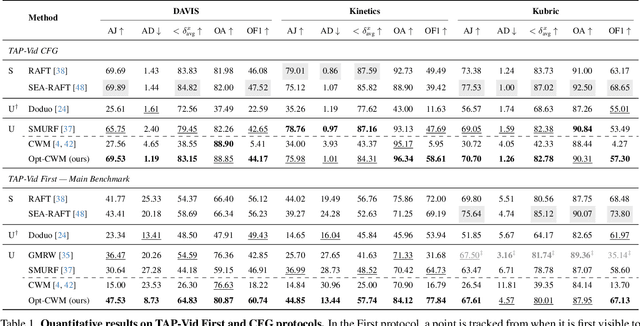
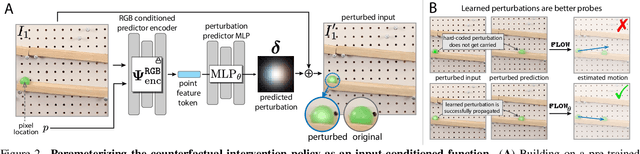
Estimating motion in videos is an essential computer vision problem with many downstream applications, including controllable video generation and robotics. Current solutions are primarily trained using synthetic data or require tuning of situation-specific heuristics, which inherently limits these models' capabilities in real-world contexts. Despite recent developments in large-scale self-supervised learning from videos, leveraging such representations for motion estimation remains relatively underexplored. In this work, we develop Opt-CWM, a self-supervised technique for flow and occlusion estimation from a pre-trained next-frame prediction model. Opt-CWM works by learning to optimize counterfactual probes that extract motion information from a base video model, avoiding the need for fixed heuristics while training on unrestricted video inputs. We achieve state-of-the-art performance for motion estimation on real-world videos while requiring no labeled data.
Leveraging Object Priors for Point Tracking
Sep 09, 2024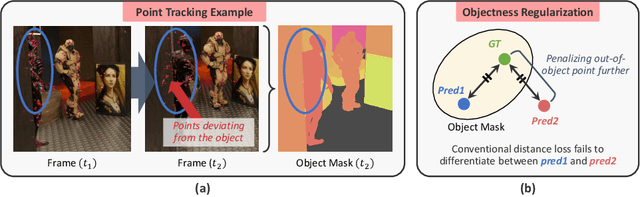
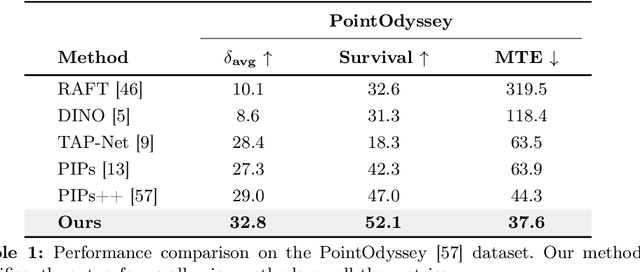
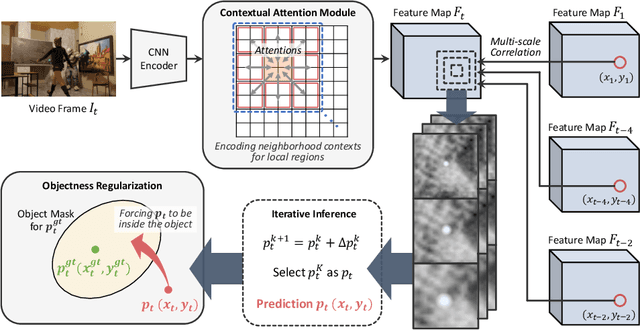

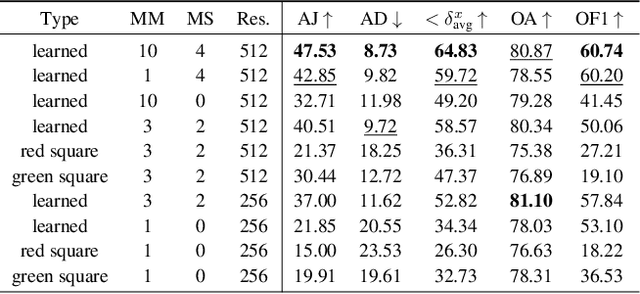
Point tracking is a fundamental problem in computer vision with numerous applications in AR and robotics. A common failure mode in long-term point tracking occurs when the predicted point leaves the object it belongs to and lands on the background or another object. We identify this as the failure to correctly capture objectness properties in learning to track. To address this limitation of prior work, we propose a novel objectness regularization approach that guides points to be aware of object priors by forcing them to stay inside the the boundaries of object instances. By capturing objectness cues at training time, we avoid the need to compute object masks during testing. In addition, we leverage contextual attention to enhance the feature representation for capturing objectness at the feature level more effectively. As a result, our approach achieves state-of-the-art performance on three point tracking benchmarks, and we further validate the effectiveness of our components via ablation studies. The source code is available at: https://github.com/RehgLab/tracking_objectness
3x2: 3D Object Part Segmentation by 2D Semantic Correspondences
Jul 12, 2024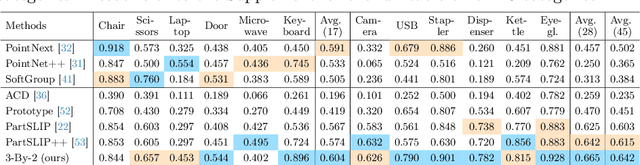

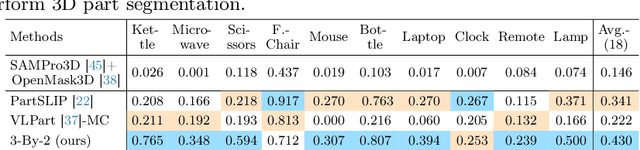
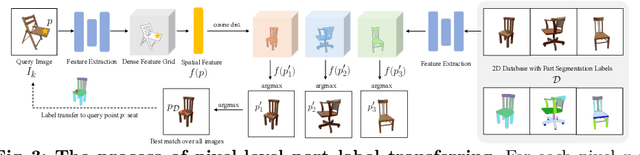
3D object part segmentation is essential in computer vision applications. While substantial progress has been made in 2D object part segmentation, the 3D counterpart has received less attention, in part due to the scarcity of annotated 3D datasets, which are expensive to collect. In this work, we propose to leverage a few annotated 3D shapes or richly annotated 2D datasets to perform 3D object part segmentation. We present our novel approach, termed 3-By-2 that achieves SOTA performance on different benchmarks with various granularity levels. By using features from pretrained foundation models and exploiting semantic and geometric correspondences, we are able to overcome the challenges of limited 3D annotations. Our approach leverages available 2D labels, enabling effective 3D object part segmentation. Our method 3-By-2 can accommodate various part taxonomies and granularities, demonstrating interesting part label transfer ability across different object categories. Project website: \url{https://ngailapdi.github.io/projects/3by2/}.
The BabyView dataset: High-resolution egocentric videos of infants' and young children's everyday experiences
Jun 14, 2024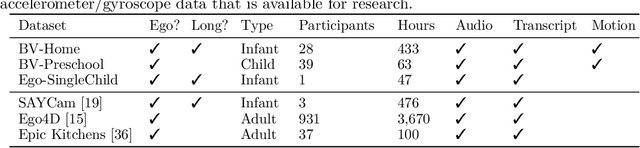
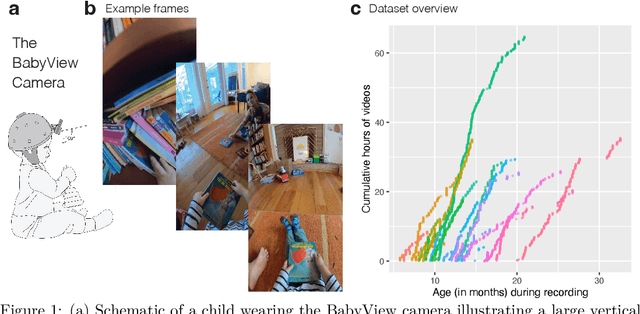
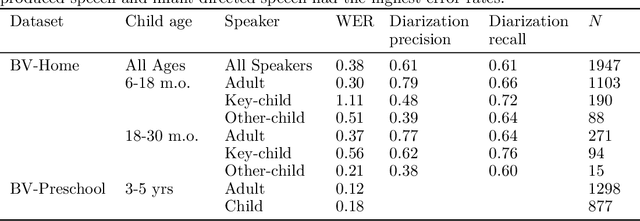
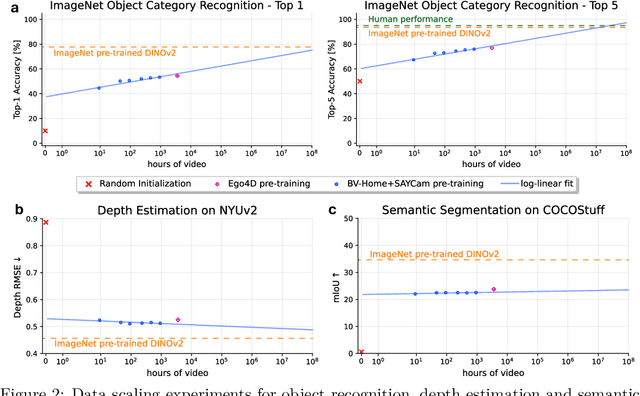
Human children far exceed modern machine learning algorithms in their sample efficiency, achieving high performance in key domains with much less data than current models. This ''data gap'' is a key challenge both for building intelligent artificial systems and for understanding human development. Egocentric video capturing children's experience -- their ''training data'' -- is a key ingredient for comparison of humans and models and for the development of algorithmic innovations to bridge this gap. Yet there are few such datasets available, and extant data are low-resolution, have limited metadata, and importantly, represent only a small set of children's experiences. Here, we provide the first release of the largest developmental egocentric video dataset to date -- the BabyView dataset -- recorded using a high-resolution camera with a large vertical field-of-view and gyroscope/accelerometer data. This 493 hour dataset includes egocentric videos from children spanning 6 months - 5 years of age in both longitudinal, at-home contexts and in a preschool environment. We provide gold-standard annotations for the evaluation of speech transcription, speaker diarization, and human pose estimation, and evaluate models in each of these domains. We train self-supervised language and vision models and evaluate their transfer to out-of-distribution tasks including syntactic structure learning, object recognition, depth estimation, and image segmentation. Although performance in each scales with dataset size, overall performance is relatively lower than when models are trained on curated datasets, especially in the visual domain. Our dataset stands as an open challenge for robust, humanlike AI systems: how can such systems achieve human-levels of success on the same scale and distribution of training data as humans?
ZeroShape: Regression-based Zero-shot Shape Reconstruction
Jan 16, 2024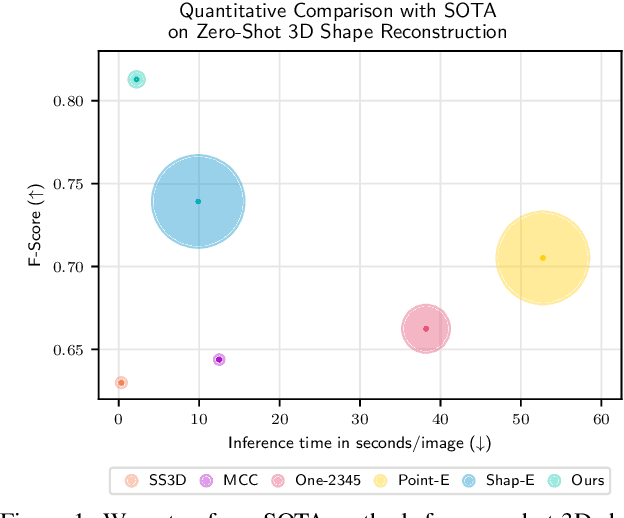
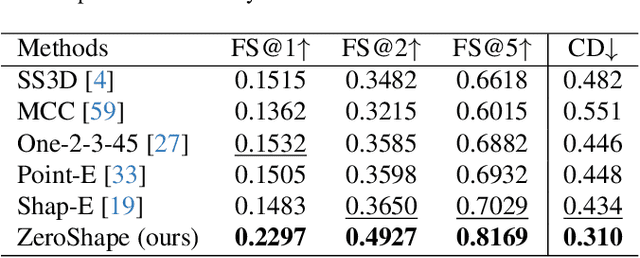

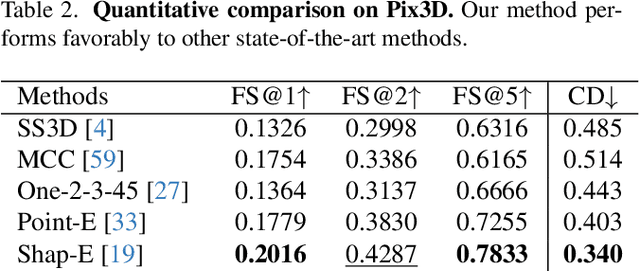
We study the problem of single-image zero-shot 3D shape reconstruction. Recent works learn zero-shot shape reconstruction through generative modeling of 3D assets, but these models are computationally expensive at train and inference time. In contrast, the traditional approach to this problem is regression-based, where deterministic models are trained to directly regress the object shape. Such regression methods possess much higher computational efficiency than generative methods. This raises a natural question: is generative modeling necessary for high performance, or conversely, are regression-based approaches still competitive? To answer this, we design a strong regression-based model, called ZeroShape, based on the converging findings in this field and a novel insight. We also curate a large real-world evaluation benchmark, with objects from three different real-world 3D datasets. This evaluation benchmark is more diverse and an order of magnitude larger than what prior works use to quantitatively evaluate their models, aiming at reducing the evaluation variance in our field. We show that ZeroShape not only achieves superior performance over state-of-the-art methods, but also demonstrates significantly higher computational and data efficiency.