 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExact Posterior Score Estimation for Solving Linear Inverse Problems
Jun 15, 2026Diffusion and flow-based models learn powerful data priors by training a denoiser to reverse Gaussian corruption. To use this prior to solve a linear inverse problem, one needs to sample from the posterior, but the score that the prior provides is the unconditional score, not the posterior score. Existing methods either steer a fixed pretrained denoiser with approximate measurement-matching corrections, or train a conditional restoration model that abandons the denoising structure of the prior. We derive the exact posterior score in closed form for linear Gaussian inverse problems under general Gaussian interpolants, and show that posterior sampling reduces to a denoising problem at an operator-dependent shifted pivot under an anisotropic noise covariance. We turn this identity into Exact Posterior Score (EPS), a denoising training objective that preserves the input/output structure of standard pretraining and can therefore be trained from scratch or fine-tuned from a pretrained denoiser. At inference, EPS uses the same sampler as the underlying backbone, with no likelihood gradients or projections. We evaluate EPS on five linear inverse problems across FFHQ and ImageNet, where it outperforms training-free and training-based baselines on fidelity, perceptual, and distributional metrics, while using roughly an order of magnitude fewer denoiser evaluations than gradient-based posterior samplers.
ST-DiffEye: Diffusion-based Continuous Gaze Generation via Joint Scanpath-Trajectory Modeling
Jun 13, 2026We study the problem of human gaze modeling, which aims to generate the gaze patterns a viewer produces while observing a visual stimulus. Gaze is primarily captured through two modalities: continuous eye-tracking trajectories, which describe fine-grained motion dynamics, and discrete scanpaths, which describe high-level fixation structure. Because gaze varies substantially across viewers and trials, we treat this variability as a defining property rather than noise and model gaze as a stochastic generative process. Existing generative gaze models supervise on only one of these two representations in isolation. We hypothesize that trajectories and scanpaths describe gaze at complementary scales and are jointly informative during training, and test this hypothesis through ST-DiffEye, a joint trajectory-scanpath diffusion framework that couples both modalities by concatenating them as an additional raw input channel, requiring no architectural overhead beyond an input and output channel expansion. We further introduce a principled evaluation framework based on the Continuous Ranked Probability Score (CRPS), which generalizes any existing sequence similarity metric into a proper scoring rule that jointly assesses the accuracy and diversity of generated gaze. Experiments on task-driven visual search, covering both target-present and target-absent scenarios, and on free-viewing benchmarks demonstrate state-of-the-art performance. These results, along with detailed ablations, confirm the benefit of joint modeling and the value of distribution-aware evaluation in capturing the intrinsic variability of human gaze. Project webpage: https://st-diffeye.github.io/
Narrative-Driven Paper-to-Slide Generation via ArcDeck
Apr 13, 2026We introduce ArcDeck, a multi-agent framework that formulates paper-to-slide generation as a structured narrative reconstruction task. Unlike existing methods that directly summarize raw text into slides, ArcDeck explicitly models the source paper's logical flow. It first parses the input to construct a discourse tree and establish a global commitment document, ensuring the high-level intent is preserved. These structural priors then guide an iterative multi-agent refinement process, where specialized agents iteratively critique and revise the presentation outline before rendering the final visual layouts and designs. To evaluate our approach, we also introduce ArcBench, a newly curated benchmark of academic paper-slide pairs. Experimental results demonstrate that explicit discourse modeling, combined with role-specific agent coordination, significantly improves the narrative flow and logical coherence of the generated presentations.
Immune2V: Image Immunization Against Dual-Stream Image-to-Video Generation
Apr 12, 2026Image-to-video (I2V) generation has the potential for societal harm because it enables the unauthorized animation of static images to create realistic deepfakes. While existing defenses effectively protect against static image manipulation, extending these to I2V generation remains underexplored and non-trivial. In this paper, we systematically analyze why modern I2V models are highly robust against naive image-level adversarial attacks (i.e., immunization). We observe that the video encoding process rapidly dilutes the adversarial noise across future frames, and the continuous text-conditioned guidance actively overrides the intended disruptive effect of the immunization. Building on these findings, we propose the Immune2V framework which enforces temporally balanced latent divergence at the encoder level to prevent signal dilution, and aligns intermediate generative representations with a precomputed collapse-inducing trajectory to counteract the text-guidance override. Extensive experiments demonstrate that Immune2V produces substantially stronger and more persistent degradation than adapted image-level baselines under the same imperceptibility budget.
ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models
May 12, 2025Current diffusion-based text-to-video methods are limited to producing short video clips of a single shot and lack the capability to generate multi-shot videos with discrete transitions where the same character performs distinct activities across the same or different backgrounds. To address this limitation we propose a framework that includes a dataset collection pipeline and architectural extensions to video diffusion models to enable text-to-multi-shot video generation. Our approach enables generation of multi-shot videos as a single video with full attention across all frames of all shots, ensuring character and background consistency, and allows users to control the number, duration, and content of shots through shot-specific conditioning. This is achieved by incorporating a transition token into the text-to-video model to control at which frames a new shot begins and a local attention masking strategy which controls the transition token's effect and allows shot-specific prompting. To obtain training data we propose a novel data collection pipeline to construct a multi-shot video dataset from existing single-shot video datasets. Extensive experiments demonstrate that fine-tuning a pre-trained text-to-video model for a few thousand iterations is enough for the model to subsequently be able to generate multi-shot videos with shot-specific control, outperforming the baselines. You can find more details in https://shotadapter.github.io/
Optimization-Free Image Immunization Against Diffusion-Based Editing
Nov 27, 2024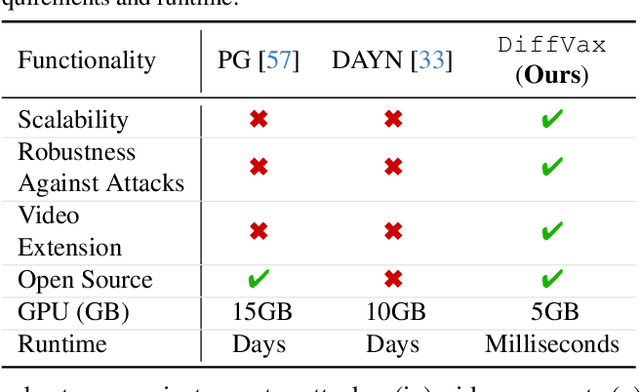
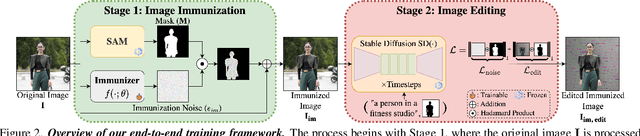


Current image immunization defense techniques against diffusion-based editing embed imperceptible noise in target images to disrupt editing models. However, these methods face scalability challenges, as they require time-consuming re-optimization for each image-taking hours for small batches. To address these challenges, we introduce DiffVax, a scalable, lightweight, and optimization-free framework for image immunization, specifically designed to prevent diffusion-based editing. Our approach enables effective generalization to unseen content, reducing computational costs and cutting immunization time from days to milliseconds-achieving a 250,000x speedup. This is achieved through a loss term that ensures the failure of editing attempts and the imperceptibility of the perturbations. Extensive qualitative and quantitative results demonstrate that our model is scalable, optimization-free, adaptable to various diffusion-based editing tools, robust against counter-attacks, and, for the first time, effectively protects video content from editing. Our code is provided in our project webpage.
Leveraging Object Priors for Point Tracking
Sep 09, 2024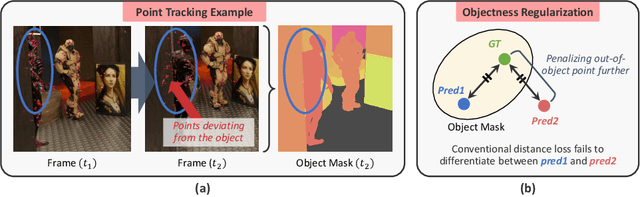
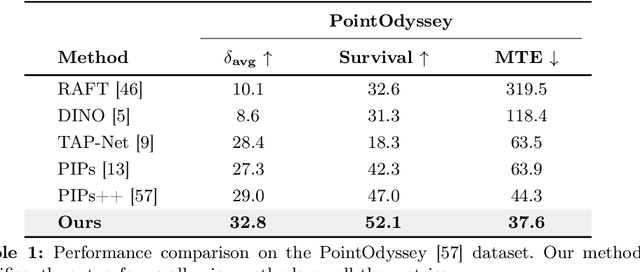
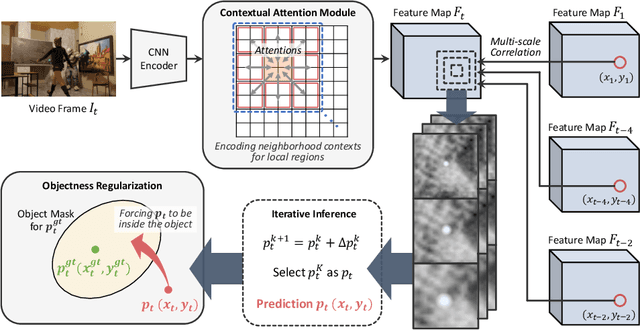

Point tracking is a fundamental problem in computer vision with numerous applications in AR and robotics. A common failure mode in long-term point tracking occurs when the predicted point leaves the object it belongs to and lands on the background or another object. We identify this as the failure to correctly capture objectness properties in learning to track. To address this limitation of prior work, we propose a novel objectness regularization approach that guides points to be aware of object priors by forcing them to stay inside the the boundaries of object instances. By capturing objectness cues at training time, we avoid the need to compute object masks during testing. In addition, we leverage contextual attention to enhance the feature representation for capturing objectness at the feature level more effectively. As a result, our approach achieves state-of-the-art performance on three point tracking benchmarks, and we further validate the effectiveness of our components via ablation studies. The source code is available at: https://github.com/RehgLab/tracking_objectness
Transfer Learning for Cross-dataset Isolated Sign Language Recognition in Under-Resourced Datasets
Mar 21, 2024



Sign language recognition (SLR) has recently achieved a breakthrough in performance thanks to deep neural networks trained on large annotated sign datasets. Of the many different sign languages, these annotated datasets are only available for a select few. Since acquiring gloss-level labels on sign language videos is difficult, learning by transferring knowledge from existing annotated sources is useful for recognition in under-resourced sign languages. This study provides a publicly available cross-dataset transfer learning benchmark from two existing public Turkish SLR datasets. We use a temporal graph convolution-based sign language recognition approach to evaluate five supervised transfer learning approaches and experiment with closed-set and partial-set cross-dataset transfer learning. Experiments demonstrate that improvement over finetuning based transfer learning is possible with specialized supervised transfer learning methods.
RAVE: Randomized Noise Shuffling for Fast and Consistent Video Editing with Diffusion Models
Dec 07, 2023

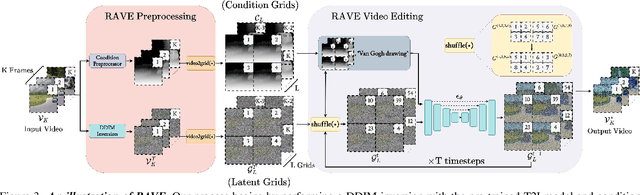

Recent advancements in diffusion-based models have demonstrated significant success in generating images from text. However, video editing models have not yet reached the same level of visual quality and user control. To address this, we introduce RAVE, a zero-shot video editing method that leverages pre-trained text-to-image diffusion models without additional training. RAVE takes an input video and a text prompt to produce high-quality videos while preserving the original motion and semantic structure. It employs a novel noise shuffling strategy, leveraging spatio-temporal interactions between frames, to produce temporally consistent videos faster than existing methods. It is also efficient in terms of memory requirements, allowing it to handle longer videos. RAVE is capable of a wide range of edits, from local attribute modifications to shape transformations. In order to demonstrate the versatility of RAVE, we create a comprehensive video evaluation dataset ranging from object-focused scenes to complex human activities like dancing and typing, and dynamic scenes featuring swimming fish and boats. Our qualitative and quantitative experiments highlight the effectiveness of RAVE in diverse video editing scenarios compared to existing methods. Our code, dataset and videos can be found in https://rave-video.github.io.
ISNAS-DIP: Image-Specific Neural Architecture Search for Deep Image Prior
Nov 27, 2021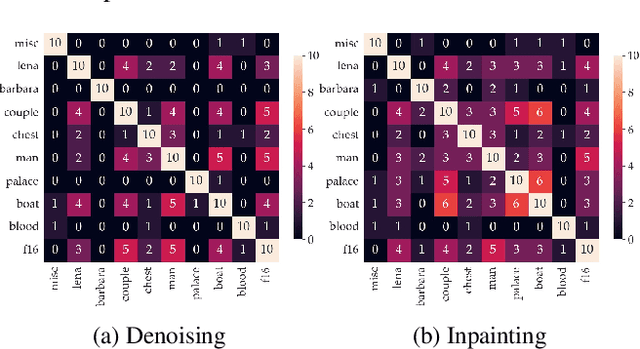
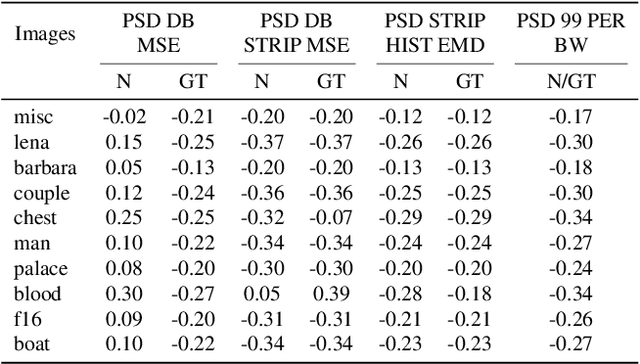
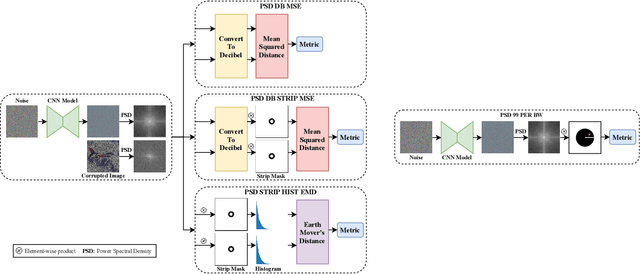
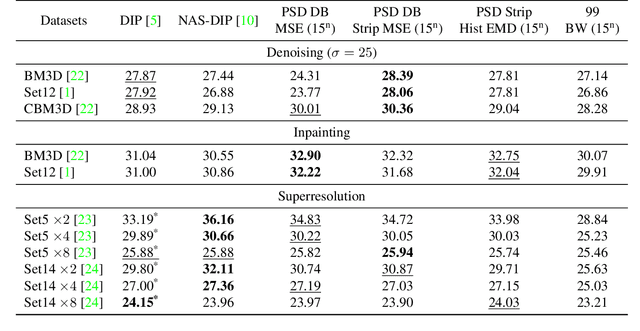
Recent works show that convolutional neural network (CNN) architectures have a spectral bias towards lower frequencies, which has been leveraged for various image restoration tasks in the Deep Image Prior (DIP) framework. The benefit of the inductive bias the network imposes in the DIP framework depends on the architecture. Therefore, researchers have studied how to automate the search to determine the best-performing model. However, common neural architecture search (NAS) techniques are resource and time-intensive. Moreover, best-performing models are determined for a whole dataset of images instead of for each image independently, which would be prohibitively expensive. In this work, we first show that optimal neural architectures in the DIP framework are image-dependent. Leveraging this insight, we then propose an image-specific NAS strategy for the DIP framework that requires substantially less training than typical NAS approaches, effectively enabling image-specific NAS. For a given image, noise is fed to a large set of untrained CNNs, and their outputs' power spectral densities (PSD) are compared to that of the corrupted image using various metrics. Based on this, a small cohort of image-specific architectures is chosen and trained to reconstruct the corrupted image. Among this cohort, the model whose reconstruction is closest to the average of the reconstructed images is chosen as the final model. We justify the proposed strategy's effectiveness by (1) demonstrating its performance on a NAS Dataset for DIP that includes 500+ models from a particular search space (2) conducting extensive experiments on image denoising, inpainting, and super-resolution tasks. Our experiments show that image-specific metrics can reduce the search space to a small cohort of models, of which the best model outperforms current NAS approaches for image restoration.