 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer Learning for Cross-dataset Isolated Sign Language Recognition in Under-Resourced Datasets
Mar 21, 2024



Sign language recognition (SLR) has recently achieved a breakthrough in performance thanks to deep neural networks trained on large annotated sign datasets. Of the many different sign languages, these annotated datasets are only available for a select few. Since acquiring gloss-level labels on sign language videos is difficult, learning by transferring knowledge from existing annotated sources is useful for recognition in under-resourced sign languages. This study provides a publicly available cross-dataset transfer learning benchmark from two existing public Turkish SLR datasets. We use a temporal graph convolution-based sign language recognition approach to evaluate five supervised transfer learning approaches and experiment with closed-set and partial-set cross-dataset transfer learning. Experiments demonstrate that improvement over finetuning based transfer learning is possible with specialized supervised transfer learning methods.
Conditional Information Gain Trellis
Feb 13, 2024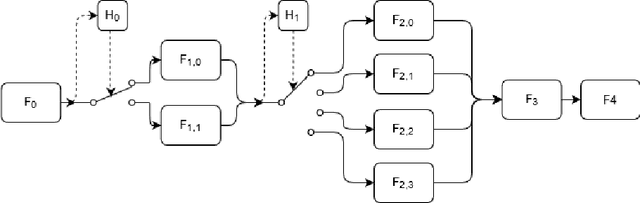

Conditional computing processes an input using only part of the neural network's computational units. Learning to execute parts of a deep convolutional network by routing individual samples has several advantages: Reducing the computational burden is an obvious advantage. Furthermore, if similar classes are routed to the same path, that part of the network learns to discriminate between finer differences and better classification accuracies can be attained with fewer parameters. Recently, several papers have exploited this idea to take a particular child of a node in a tree-shaped network or to skip parts of a network. In this work, we follow a Trellis-based approach for generating specific execution paths in a deep convolutional neural network. We have designed routing mechanisms that use differentiable information gain-based cost functions to determine which subset of features in a convolutional layer will be executed. We call our method Conditional Information Gain Trellis (CIGT). We show that our conditional execution mechanism achieves comparable or better model performance compared to unconditional baselines, using only a fraction of the computational resources.
The Multiscenario Multienvironment BioSecure Multimodal Database (BMDB)
Nov 17, 2021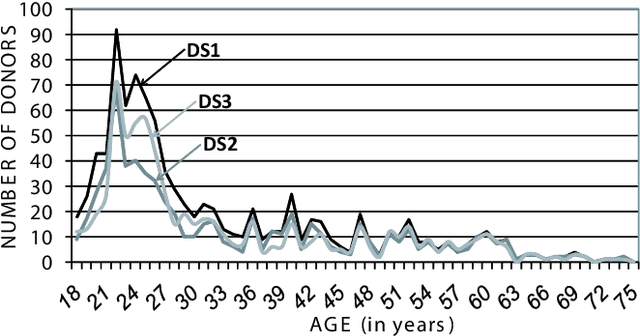


A new multimodal biometric database designed and acquired within the framework of the European BioSecure Network of Excellence is presented. It is comprised of more than 600 individuals acquired simultaneously in three scenarios: 1) over the Internet, 2) in an office environment with desktop PC, and 3) in indoor/outdoor environments with mobile portable hardware. The three scenarios include a common part of audio/video data. Also, signature and fingerprint data have been acquired both with desktop PC and mobile portable hardware. Additionally, hand and iris data were acquired in the second scenario using desktop PC. Acquisition has been conducted by 11 European institutions. Additional features of the BioSecure Multimodal Database (BMDB) are: two acquisition sessions, several sensors in certain modalities, balanced gender and age distributions, multimodal realistic scenarios with simple and quick tasks per modality, cross-European diversity, availability of demographic data, and compatibility with other multimodal databases. The novel acquisition conditions of the BMDB allow us to perform new challenging research and evaluation of either monomodal or multimodal biometric systems, as in the recent BioSecure Multimodal Evaluation campaign. A description of this campaign including baseline results of individual modalities from the new database is also given. The database is expected to be available for research purposes through the BioSecure Association during 2008
Score-level Multi Cue Fusion for Sign Language Recognition
Sep 29, 2020

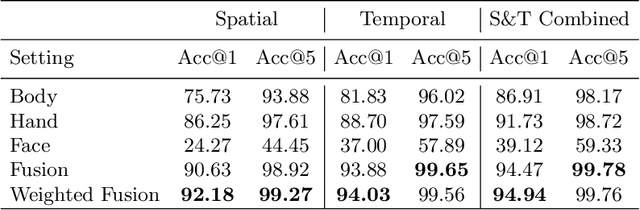
Sign Languages are expressed through hand and upper body gestures as well as facial expressions. Therefore, Sign Language Recognition (SLR) needs to focus on all such cues. Previous work uses hand-crafted mechanisms or network aggregation to extract the different cue features, to increase SLR performance. This is slow and involves complicated architectures. We propose a more straightforward approach that focuses on training separate cue models specializing on the dominant hand, hands, face, and upper body regions. We compare the performance of 3D Convolutional Neural Network (CNN) models specializing in these regions, combine them through score-level fusion, and use the weighted alternative. Our experimental results have shown the effectiveness of mixed convolutional models. Their fusion yields up to 19% accuracy improvement over the baseline using the full upper body. Furthermore, we include a discussion for fusion settings, which can help future work on Sign Language Translation (SLT).
BosphorusSign22k Sign Language Recognition Dataset
Apr 09, 2020

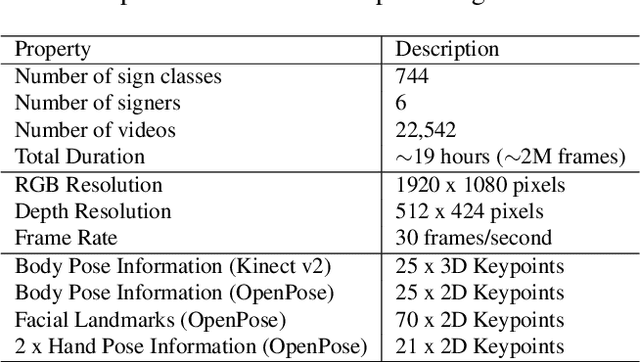

Sign Language Recognition is a challenging research domain. It has recently seen several advancements with the increased availability of data. In this paper, we introduce the BosphorusSign22k, a publicly available large scale sign language dataset aimed at computer vision, video recognition and deep learning research communities. The primary objective of this dataset is to serve as a new benchmark in Turkish Sign Language Recognition for its vast lexicon, the high number of repetitions by native signers, high recording quality, and the unique syntactic properties of the signs it encompasses. We also provide state-of-the-art human pose estimates to encourage other tasks such as Sign Language Production. We survey other publicly available datasets and expand on how BosphorusSign22k can contribute to future research that is being made possible through the widespread availability of similar Sign Language resources. We have conducted extensive experiments and present baseline results to underpin future research on our dataset.
Temporal Accumulative Features for Sign Language Recognition
Apr 02, 2020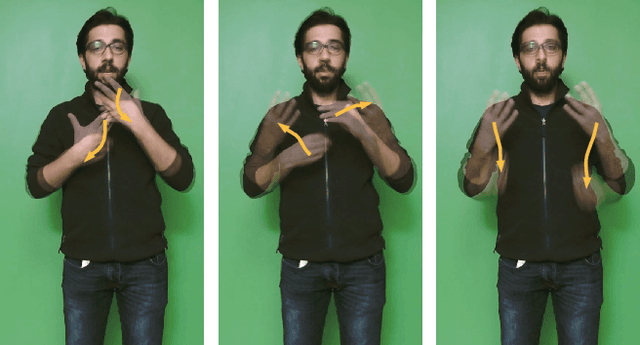
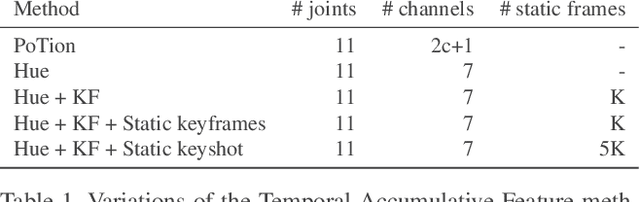
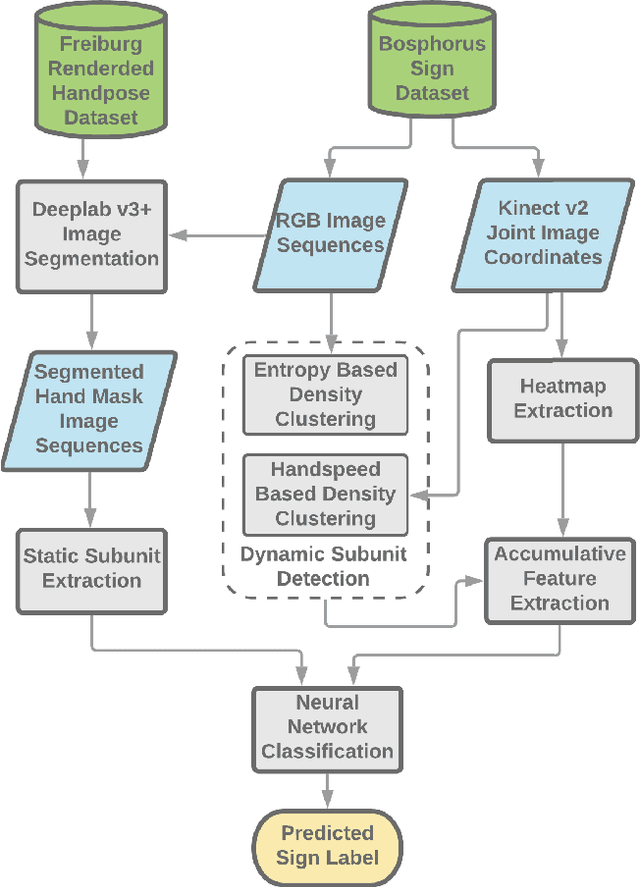
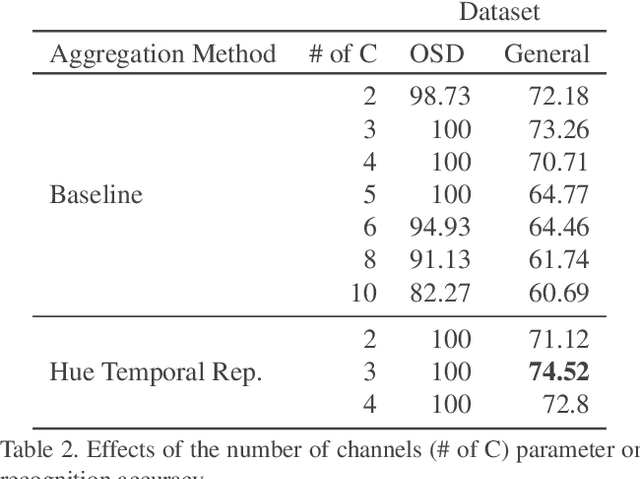
In this paper, we propose a set of features called temporal accumulative features (TAF) for representing and recognizing isolated sign language gestures. By incorporating sign language specific constructs to better represent the unique linguistic characteristic of sign language videos, we have devised an efficient and fast SLR method for recognizing isolated sign language gestures. The proposed method is an HSV based accumulative video representation where keyframes based on the linguistic movement-hold model are represented by different colors. We also incorporate hand shape information and using a small scale convolutional neural network, demonstrate that sequential modeling of accumulative features for linguistic subunits improves upon baseline classification results.
Neural Sign Language Translation by Learning Tokenization
Mar 04, 2020


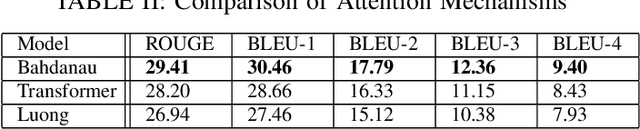
Sign Language Translation has attained considerable success recently, raising hopes for improved communication with the Deaf. A pre-processing step called tokenization improves the success of translations. Tokens can be learned from sign videos if supervised data is available. However, data annotation at the gloss level is costly, and annotated data is scarce. The paper utilizes Adversarial, Multitask, Transfer Learning to search for semi-supervised tokenization approaches without burden of additional labeling. It provides extensive experiments to compare all the methods in different settings to conduct a deeper analysis. In the case of no additional target annotation besides sentences, the proposed methodology attains 13.25 BLUE-4 and 36.28 ROUGE scores which improves the current state-of-the-art by 4 points in BLUE-4 and 5 points in ROUGE.
Conditional Information Gain Networks
Jul 25, 2018



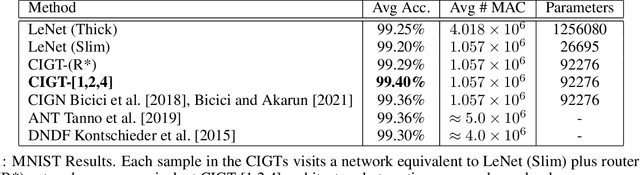
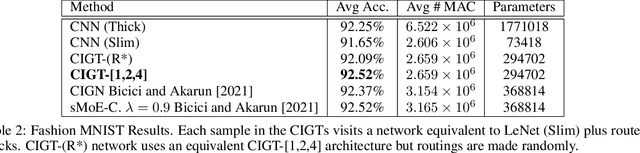
Deep neural network models owe their representational power to the high number of learnable parameters. It is often infeasible to run these largely parametrized deep models in limited resource environments, like mobile phones. Network models employing conditional computing are able to reduce computational requirements while achieving high representational power, with their ability to model hierarchies. We propose Conditional Information Gain Networks, which allow the feed forward deep neural networks to execute conditionally, skipping parts of the model based on the sample and the decision mechanisms inserted in the architecture. These decision mechanisms are trained using cost functions based on differentiable Information Gain, inspired by the training procedures of decision trees. These information gain based decision mechanisms are differentiable and can be trained end-to-end using a unified framework with a general cost function, covering both classification and decision losses. We test the effectiveness of the proposed method on MNIST and recently introduced Fashion MNIST datasets and show that our information gain based conditional execution approach can achieve better or comparable classification results using significantly fewer parameters, compared to standard convolutional neural network baselines.
Sign Language Tutoring Tool
Feb 18, 2008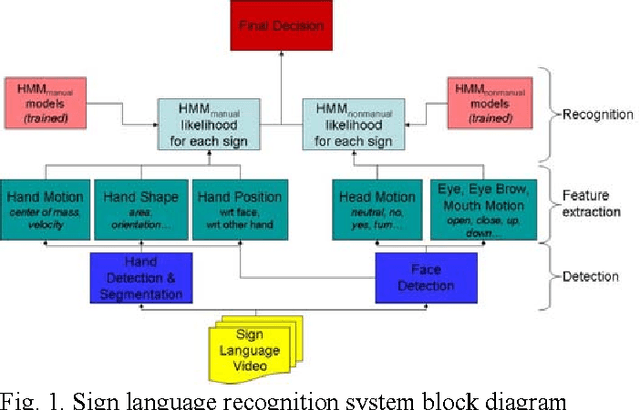
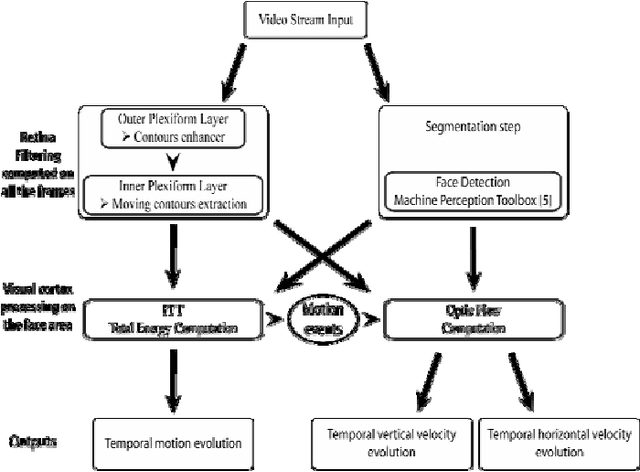
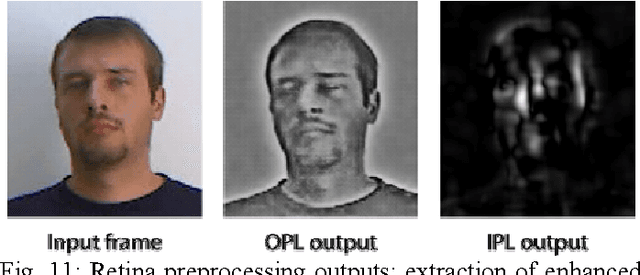
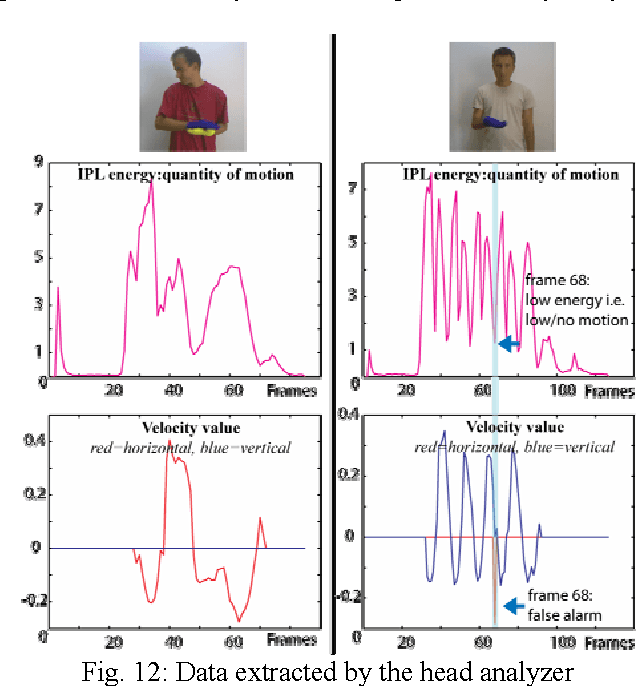
In this project, we have developed a sign language tutor that lets users learn isolated signs by watching recorded videos and by trying the same signs. The system records the user's video and analyses it. If the sign is recognized, both verbal and animated feedback is given to the user. The system is able to recognize complex signs that involve both hand gestures and head movements and expressions. Our performance tests yield a 99% recognition rate on signs involving only manual gestures and 85% recognition rate on signs that involve both manual and non manual components, such as head movement and facial expressions.