 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimum Class Confusion based Transfer for Land Cover Segmentation in Rural and Urban Regions
Dec 05, 2022Transfer Learning methods are widely used in satellite image segmentation problems and improve performance upon classical supervised learning methods. In this study, we present a semantic segmentation method that allows us to make land cover maps by using transfer learning methods. We compare models trained in low-resolution images with insufficient data for the targeted region or zoom level. In order to boost performance on target data we experiment with models trained with unsupervised, semi-supervised and supervised transfer learning approaches, including satellite images from public datasets and other unlabeled sources. According to experimental results, transfer learning improves segmentation performance 3.4% MIoU (Mean Intersection over Union) in rural regions and 12.9% MIoU in urban regions. We observed that transfer learning is more effective when two datasets share a comparable zoom level and are labeled with identical rules; otherwise, semi-supervised learning is more effective by using the data as unlabeled. In addition, experiments showed that HRNet outperformed building segmentation approaches in multi-class segmentation.
Score-level Multi Cue Fusion for Sign Language Recognition
Sep 29, 2020

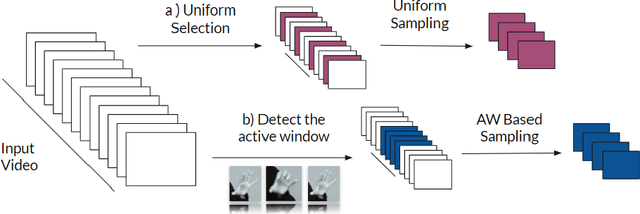
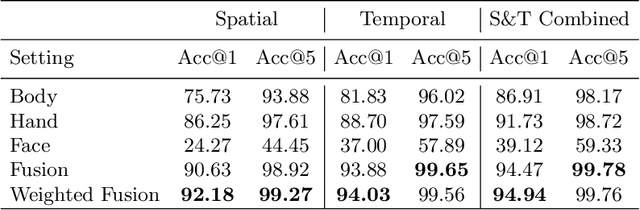
Sign Languages are expressed through hand and upper body gestures as well as facial expressions. Therefore, Sign Language Recognition (SLR) needs to focus on all such cues. Previous work uses hand-crafted mechanisms or network aggregation to extract the different cue features, to increase SLR performance. This is slow and involves complicated architectures. We propose a more straightforward approach that focuses on training separate cue models specializing on the dominant hand, hands, face, and upper body regions. We compare the performance of 3D Convolutional Neural Network (CNN) models specializing in these regions, combine them through score-level fusion, and use the weighted alternative. Our experimental results have shown the effectiveness of mixed convolutional models. Their fusion yields up to 19% accuracy improvement over the baseline using the full upper body. Furthermore, we include a discussion for fusion settings, which can help future work on Sign Language Translation (SLT).
BosphorusSign22k Sign Language Recognition Dataset
Apr 09, 2020

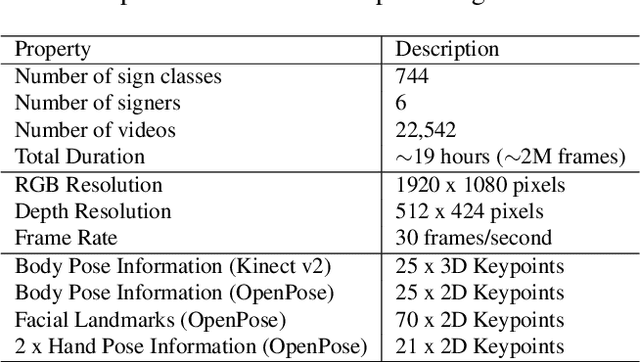

Sign Language Recognition is a challenging research domain. It has recently seen several advancements with the increased availability of data. In this paper, we introduce the BosphorusSign22k, a publicly available large scale sign language dataset aimed at computer vision, video recognition and deep learning research communities. The primary objective of this dataset is to serve as a new benchmark in Turkish Sign Language Recognition for its vast lexicon, the high number of repetitions by native signers, high recording quality, and the unique syntactic properties of the signs it encompasses. We also provide state-of-the-art human pose estimates to encourage other tasks such as Sign Language Production. We survey other publicly available datasets and expand on how BosphorusSign22k can contribute to future research that is being made possible through the widespread availability of similar Sign Language resources. We have conducted extensive experiments and present baseline results to underpin future research on our dataset.
Temporal Accumulative Features for Sign Language Recognition
Apr 02, 2020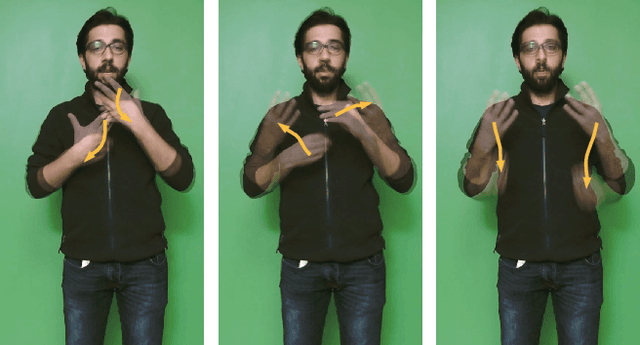
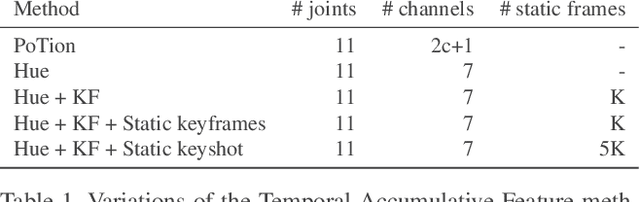
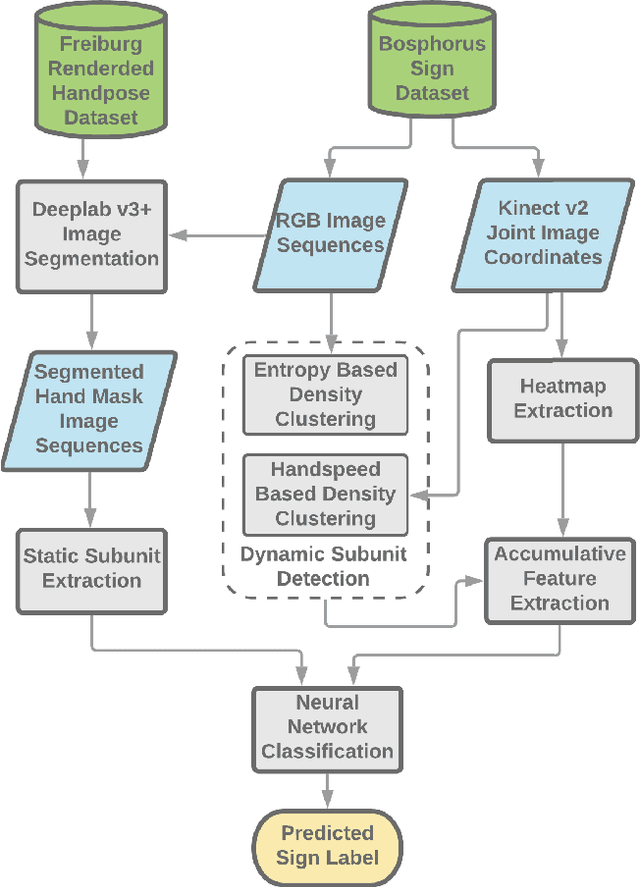
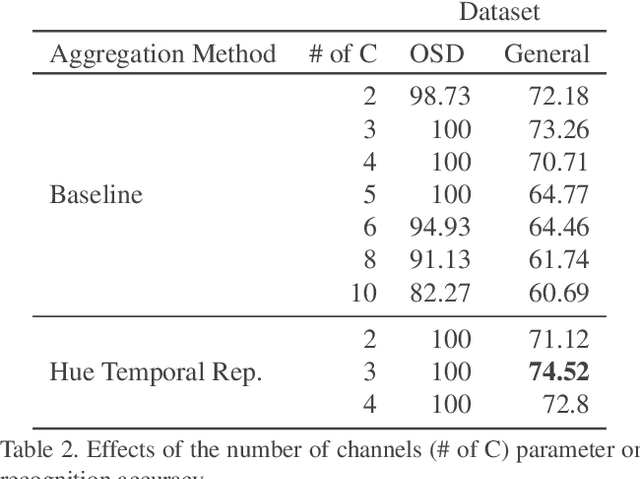
In this paper, we propose a set of features called temporal accumulative features (TAF) for representing and recognizing isolated sign language gestures. By incorporating sign language specific constructs to better represent the unique linguistic characteristic of sign language videos, we have devised an efficient and fast SLR method for recognizing isolated sign language gestures. The proposed method is an HSV based accumulative video representation where keyframes based on the linguistic movement-hold model are represented by different colors. We also incorporate hand shape information and using a small scale convolutional neural network, demonstrate that sequential modeling of accumulative features for linguistic subunits improves upon baseline classification results.