 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Privacy-Aware Sign Language Translation at Scale
Feb 14, 2024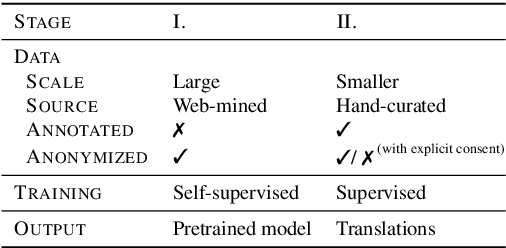

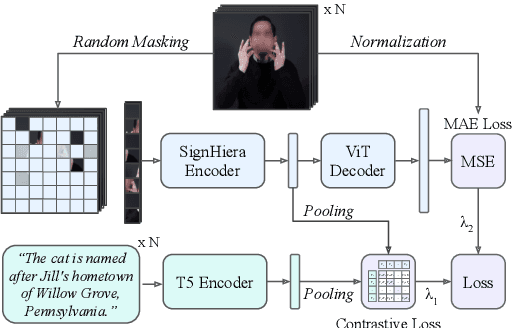
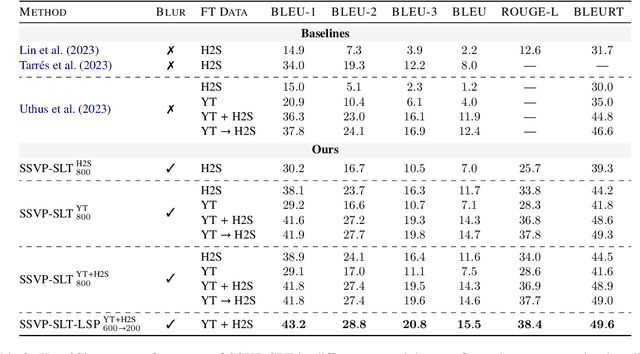
A major impediment to the advancement of sign language translation (SLT) is data scarcity. Much of the sign language data currently available on the web cannot be used for training supervised models due to the lack of aligned captions. Furthermore, scaling SLT using large-scale web-scraped datasets bears privacy risks due to the presence of biometric information, which the responsible development of SLT technologies should account for. In this work, we propose a two-stage framework for privacy-aware SLT at scale that addresses both of these issues. We introduce SSVP-SLT, which leverages self-supervised video pretraining on anonymized and unannotated videos, followed by supervised SLT finetuning on a curated parallel dataset. SSVP-SLT achieves state-of-the-art finetuned and zero-shot gloss-free SLT performance on the How2Sign dataset, outperforming the strongest respective baselines by over 3 BLEU-4. Based on controlled experiments, we further discuss the advantages and limitations of self-supervised pretraining and anonymization via facial obfuscation for SLT.
Hierarchical I3D for Sign Spotting
Oct 03, 2022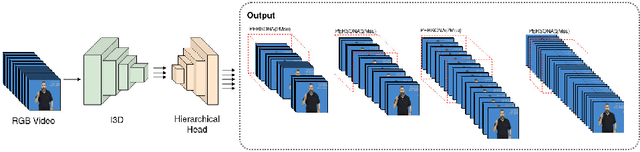

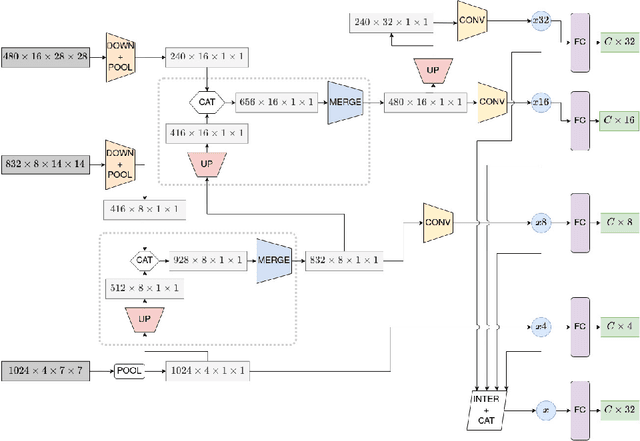
Most of the vision-based sign language research to date has focused on Isolated Sign Language Recognition (ISLR), where the objective is to predict a single sign class given a short video clip. Although there has been significant progress in ISLR, its real-life applications are limited. In this paper, we focus on the challenging task of Sign Spotting instead, where the goal is to simultaneously identify and localise signs in continuous co-articulated sign videos. To address the limitations of current ISLR-based models, we propose a hierarchical sign spotting approach which learns coarse-to-fine spatio-temporal sign features to take advantage of representations at various temporal levels and provide more precise sign localisation. Specifically, we develop Hierarchical Sign I3D model (HS-I3D) which consists of a hierarchical network head that is attached to the existing spatio-temporal I3D model to exploit features at different layers of the network. We evaluate HS-I3D on the ChaLearn 2022 Sign Spotting Challenge - MSSL track and achieve a state-of-the-art 0.607 F1 score, which was the top-1 winning solution of the competition.
Evaluating the Immediate Applicability of Pose Estimation for Sign Language Recognition
Apr 20, 2021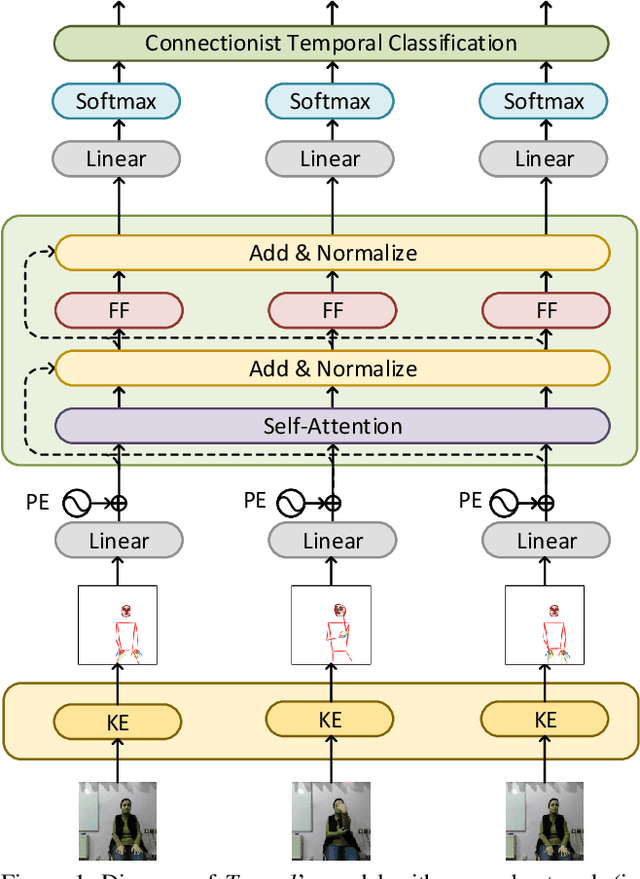
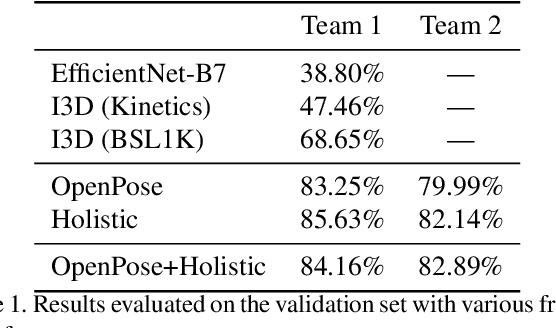
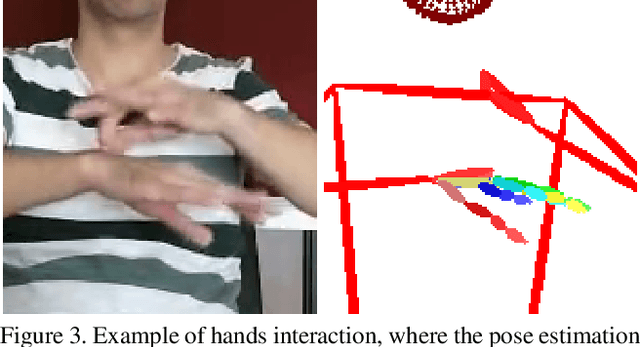
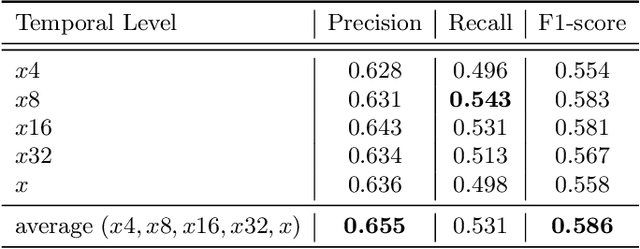
Signed languages are visual languages produced by the movement of the hands, face, and body. In this paper, we evaluate representations based on skeleton poses, as these are explainable, person-independent, privacy-preserving, low-dimensional representations. Basically, skeletal representations generalize over an individual's appearance and background, allowing us to focus on the recognition of motion. But how much information is lost by the skeletal representation? We perform two independent studies using two state-of-the-art pose estimation systems. We analyze the applicability of the pose estimation systems to sign language recognition by evaluating the failure cases of the recognition models. Importantly, this allows us to characterize the current limitations of skeletal pose estimation approaches in sign language recognition.
BosphorusSign22k Sign Language Recognition Dataset
Apr 09, 2020

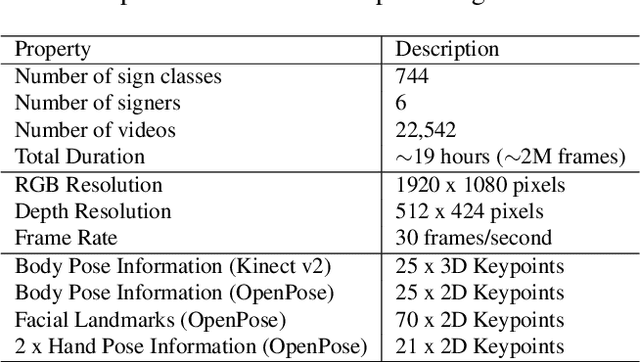

Sign Language Recognition is a challenging research domain. It has recently seen several advancements with the increased availability of data. In this paper, we introduce the BosphorusSign22k, a publicly available large scale sign language dataset aimed at computer vision, video recognition and deep learning research communities. The primary objective of this dataset is to serve as a new benchmark in Turkish Sign Language Recognition for its vast lexicon, the high number of repetitions by native signers, high recording quality, and the unique syntactic properties of the signs it encompasses. We also provide state-of-the-art human pose estimates to encourage other tasks such as Sign Language Production. We survey other publicly available datasets and expand on how BosphorusSign22k can contribute to future research that is being made possible through the widespread availability of similar Sign Language resources. We have conducted extensive experiments and present baseline results to underpin future research on our dataset.