 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Disability Representations in Text-to-Image Models
Feb 04, 2026Text-to-image generative models have made remarkable progress in producing high-quality visual content from textual descriptions, yet concerns remain about how they represent social groups. While characteristics like gender and race have received increasing attention, disability representations remain underexplored. This study investigates how people with disabilities are represented in AI-generated images by analyzing outputs from Stable Diffusion XL and DALL-E 3 using a structured prompt design. We analyze disability representations by comparing image similarities between generic disability prompts and prompts referring to specific disability categories. Moreover, we evaluate how mitigation strategies influence disability portrayals, with a focus on assessing affective framing through sentiment polarity analysis, combining both automatic and human evaluation. Our findings reveal persistent representational imbalances and highlight the need for continuous evaluation and refinement of generative models to foster more diverse and inclusive portrayals of disability.
Segment, Embed, and Align: A Universal Recipe for Aligning Subtitles to Signing
Dec 08, 2025The goal of this work is to develop a universal approach for aligning subtitles (i.e., spoken language text with corresponding timestamps) to continuous sign language videos. Prior approaches typically rely on end-to-end training tied to a specific language or dataset, which limits their generality. In contrast, our method Segment, Embed, and Align (SEA) provides a single framework that works across multiple languages and domains. SEA leverages two pretrained models: the first to segment a video frame sequence into individual signs and the second to embed the video clip of each sign into a shared latent space with text. Alignment is subsequently performed with a lightweight dynamic programming procedure that runs efficiently on CPUs within a minute, even for hour-long episodes. SEA is flexible and can adapt to a wide range of scenarios, utilizing resources from small lexicons to large continuous corpora. Experiments on four sign language datasets demonstrate state-of-the-art alignment performance, highlighting the potential of SEA to generate high-quality parallel data for advancing sign language processing. SEA's code and models are openly available.
Beyond Appearance: Transformer-based Person Identification from Conversational Dynamics
Oct 06, 2025



This paper investigates the performance of transformer-based architectures for person identification in natural, face-to-face conversation scenario. We implement and evaluate a two-stream framework that separately models spatial configurations and temporal motion patterns of 133 COCO WholeBody keypoints, extracted from a subset of the CANDOR conversational corpus. Our experiments compare pre-trained and from-scratch training, investigate the use of velocity features, and introduce a multi-scale temporal transformer for hierarchical motion modeling. Results demonstrate that domain-specific training significantly outperforms transfer learning, and that spatial configurations carry more discriminative information than temporal dynamics. The spatial transformer achieves 95.74% accuracy, while the multi-scale temporal transformer achieves 93.90%. Feature-level fusion pushes performance to 98.03%, confirming that postural and dynamic information are complementary. These findings highlight the potential of transformer architectures for person identification in natural interactions and provide insights for future multimodal and cross-cultural studies.
Evaluating the Effectiveness of Direct Preference Optimization for Personalizing German Automatic Text Simplifications for Persons with Intellectual Disabilities
Jul 02, 2025Automatic text simplification (ATS) aims to enhance language accessibility for various target groups, particularly persons with intellectual disabilities. Recent advancements in generative AI, especially large language models (LLMs), have substantially improved the quality of machine-generated text simplifications, thereby mitigating information barriers for the target group. However, existing LLM-based ATS systems do not incorporate preference feedback on text simplifications during training, resulting in a lack of personalization tailored to the specific needs of target group representatives. In this work, we extend the standard supervised fine-tuning (SFT) approach for adapting LLM-based ATS models by leveraging a computationally efficient LLM alignment technique -- direct preference optimization (DPO). Specifically, we post-train LLM-based ATS models using human feedback collected from persons with intellectual disabilities, reflecting their preferences on paired text simplifications generated by mainstream LLMs. Furthermore, we propose a pipeline for developing personalized LLM-based ATS systems, encompassing data collection, model selection, SFT and DPO post-training, and evaluation. Our findings underscore the necessity of active participation of target group persons in designing personalized AI accessibility solutions aligned with human expectations. This work represents a step towards personalizing inclusive AI systems at the target-group level, incorporating insights not only from text simplification experts but also from target group persons themselves.
Digitally Supported Analysis of Spontaneous Speech (DigiSpon): Benchmarking NLP-Supported Language Sample Analysis of Swiss Children's Speech
Apr 01, 2025
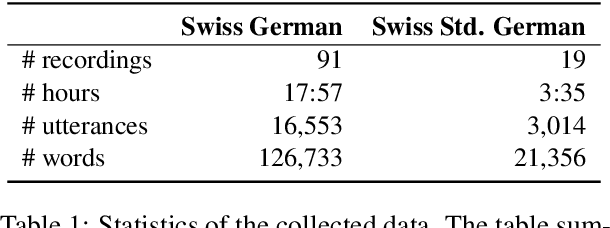

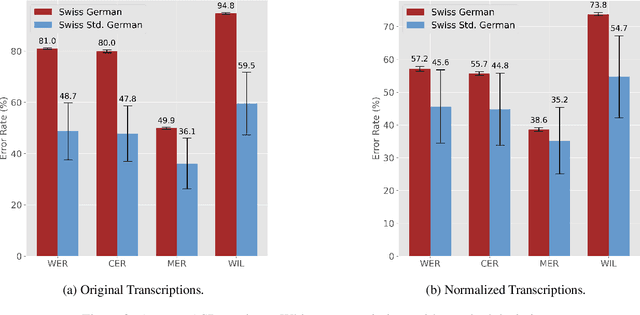
Language sample analysis (LSA) is a process that complements standardized psychometric tests for diagnosing, for example, developmental language disorder (DLD) in children. However, its labor-intensive nature has limited its use in speech-language pathology practice. We introduce an approach that leverages natural language processing (NLP) methods not based on commercial large language models (LLMs) applied to transcribed speech data from 119 children in the German speaking part of Switzerland with typical and atypical language development. The study aims to identify optimal practices that support speech-language pathologists in diagnosing DLD more efficiently within a human-in-the-loop framework, without relying on potentially unethical implementations that leverage commercial LLMs. Preliminary findings underscore the potential of integrating locally deployed NLP methods into the process of semi-automatic LSA.
Multimodal Emotion Recognition and Sentiment Analysis in Multi-Party Conversation Contexts
Mar 09, 2025Emotion recognition and sentiment analysis are pivotal tasks in speech and language processing, particularly in real-world scenarios involving multi-party, conversational data. This paper presents a multimodal approach to tackle these challenges on a well-known dataset. We propose a system that integrates four key modalities/channels using pre-trained models: RoBERTa for text, Wav2Vec2 for speech, a proposed FacialNet for facial expressions, and a CNN+Transformer architecture trained from scratch for video analysis. Feature embeddings from each modality are concatenated to form a multimodal vector, which is then used to predict emotion and sentiment labels. The multimodal system demonstrates superior performance compared to unimodal approaches, achieving an accuracy of 66.36% for emotion recognition and 72.15% for sentiment analysis.
Two-Stream Spatial-Temporal Transformer Framework for Person Identification via Natural Conversational Keypoints
Feb 28, 2025



In the age of AI-driven generative technologies, traditional biometric recognition systems face unprecedented challenges, particularly from sophisticated deepfake and face reenactment techniques. In this study, we propose a Two-Stream Spatial-Temporal Transformer Framework for person identification using upper body keypoints visible during online conversations, which we term conversational keypoints. Our framework processes both spatial relationships between keypoints and their temporal evolution through two specialized branches: a Spatial Transformer (STR) that learns distinctive structural patterns in keypoint configurations, and a Temporal Transformer (TTR) that captures sequential motion patterns. Using the state-of-the-art Sapiens pose estimator, we extract 133 keypoints (based on COCO-WholeBody format) representing facial features, head pose, and hand positions. The framework was evaluated on a dataset of 114 individuals engaged in natural conversations, achieving recognition accuracies of 80.12% for the spatial stream, 63.61% for the temporal stream. We then explored two fusion strategies: a shared loss function approach achieving 82.22% accuracy, and a feature-level fusion method that concatenates feature maps from both streams, significantly improving performance to 94.86%. By jointly modeling both static anatomical relationships and dynamic movement patterns, our approach learns comprehensive identity signatures that are more robust to spoofing than traditional appearance-based methods.
SwissADT: An Audio Description Translation System for Swiss Languages
Nov 22, 2024Audio description (AD) is a crucial accessibility service provided to blind persons and persons with visual impairment, designed to convey visual information in acoustic form. Despite recent advancements in multilingual machine translation research, the lack of well-crafted and time-synchronized AD data impedes the development of audio description translation (ADT) systems that address the needs of multilingual countries such as Switzerland. Furthermore, since the majority of ADT systems rely solely on text, uncertainty exists as to whether incorporating visual information from the corresponding video clips can enhance the quality of ADT outputs. In this work, we present SwissADT, the first ADT system implemented for three main Swiss languages and English. By collecting well-crafted AD data augmented with video clips in German, French, Italian, and English, and leveraging the power of Large Language Models (LLMs), we aim to enhance information accessibility for diverse language populations in Switzerland by automatically translating AD scripts to the desired Swiss language. Our extensive experimental ADT results, composed of both automatic and human evaluations of ADT quality, demonstrate the promising capability of SwissADT for the ADT task. We believe that combining human expertise with the generation power of LLMs can further enhance the performance of ADT systems, ultimately benefiting a larger multilingual target population.
Audio Description Generation in the Era of LLMs and VLMs: A Review of Transferable Generative AI Technologies
Oct 11, 2024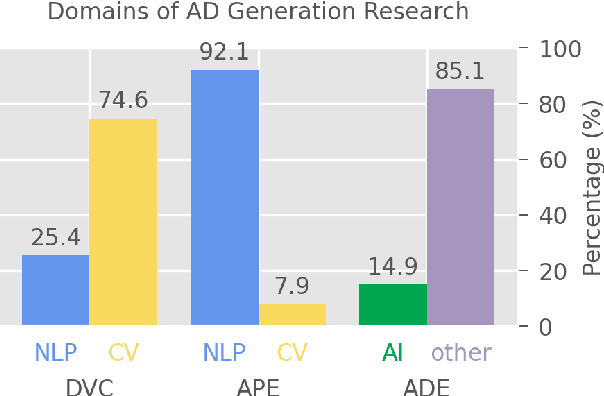



Audio descriptions (ADs) function as acoustic commentaries designed to assist blind persons and persons with visual impairments in accessing digital media content on television and in movies, among other settings. As an accessibility service typically provided by trained AD professionals, the generation of ADs demands significant human effort, making the process both time-consuming and costly. Recent advancements in natural language processing (NLP) and computer vision (CV), particularly in large language models (LLMs) and vision-language models (VLMs), have allowed for getting a step closer to automatic AD generation. This paper reviews the technologies pertinent to AD generation in the era of LLMs and VLMs: we discuss how state-of-the-art NLP and CV technologies can be applied to generate ADs and identify essential research directions for the future.
Modelling the Distribution of Human Motion for Sign Language Assessment
Aug 19, 2024



Sign Language Assessment (SLA) tools are useful to aid in language learning and are underdeveloped. Previous work has focused on isolated signs or comparison against a single reference video to assess Sign Languages (SL). This paper introduces a novel SLA tool designed to evaluate the comprehensibility of SL by modelling the natural distribution of human motion. We train our pipeline on data from native signers and evaluate it using SL learners. We compare our results to ratings from a human raters study and find strong correlation between human ratings and our tool. We visually demonstrate our tools ability to detect anomalous results spatio-temporally, providing actionable feedback to aid in SL learning and assessment.