 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Audio-Language Models Fail to Leverage Multimodal Context for Dysarthric Speech Recognition
May 04, 2026Automatic speech recognition (ASR) systems remain brittle on dysarthric and other atypical speech. Recent audio-language models raise the possibility of improving performance by conditioning on additional clinical context at inference time, but it is unclear whether these models can make use of such information. We introduce a benchmark built on the Speech Accessibility Project (SAP) dataset that tests whether diagnosis labels, clinician-derived speech ratings, and progressively richer clinical descriptions improve transcription accuracy for dysarthric speech. Across matched comparisons on nine models, we find that current models do not meaningfully use this context: diagnosis-informed and clinically detailed prompts yield negligible improvements and often degrade word error rate. We complement the prompting analysis with context-dependent fine-tuning, showing that LoRA adaptation with a mixture of clinical prompt formats achieves a WER of 0.066, a 52% relative reduction over the frozen baseline, while preserving performance when context is unavailable. Subgroup analyses reveal significant gains for Down syndrome and mild-severity speakers. These results clarify where current models fall short and provide a testbed for measuring progress toward more inclusive ASR.
Taming CATS: Controllable Automatic Text Simplification through Instruction Fine-Tuning with Control Tokens
Apr 02, 2026Controllable Automatic Text Simplification (CATS) produces user-tailored outputs, yet controllability is often treated as a decoding problem and evaluated with metrics that are not reflective to the measure of control. We observe that controllability in ATS is significantly constrained by data and evaluation. To this end, we introduce a domain-agnostic CATS framework based on instruction fine-tuning with discrete control tokens, steering open-source models to target readability levels and compression rates. Across three model families with different model sizes (Llama, Mistral, Qwen; 1-14B) and four domains (medicine, public administration, news, encyclopedic text), we find that smaller models (1-3B) can be competitive, but reliable controllability strongly depends on whether the training data encodes sufficient variation in the target attribute. Readability control (FKGL, ARI, Dale-Chall) is learned consistently, whereas compression control underperforms due to limited signal variability in the existing corpora. We further show that standard simplification and similarity metrics are insufficient for measuring control, motivating error-based measures for target-output alignment. Finally, our sampling and stratification experiments demonstrate that naive splits can introduce distributional mismatch that undermines both training and evaluation.
Generating and Evaluating Sustainable Procurement Criteria for the Swiss Public Sector using In-Context Prompting with Large Language Models
Mar 23, 2026Public procurement refers to the process by which public sector institutions, such as governments, municipalities, and publicly funded bodies, acquire goods and services. Swiss law requires the integration of ecological, social, and economic sustainability requirements into tender evaluations in the format of criteria that have to be fulfilled by a bidder. However, translating high-level sustainability regulations into concrete, verifiable, and sector-specific procurement criteria (such as selection criteria, award criteria, and technical specifications) remains a labor-intensive and error-prone manual task, requiring substantial domain expertise in several groups of goods and services and considerable manual effort. This paper presents a configurable, LLM-assisted pipeline that is presented as a software supporting the systematic generation and evaluation of sustainability-oriented procurement criteria catalogs for Switzerland. The system integrates in-context prompting, interchangeable LLM backends, and automated output validation to enable auditable criteria generation across different procurement sectors. As a proof of concept, we instantiate the pipeline using official sustainability guidelines published by the Swiss government and the European Commission, which are ingested as structured reference documents. We evaluate the system through a combination of automated quality checks, including an LLM-based evaluation component, and expert comparison against a manually curated gold standard. Our results demonstrate that the proposed pipeline can substantially reduce manual drafting effort while producing criteria catalogs that are consistent with official guidelines. We further discuss system limitations, failure modes, and design trade-offs observed during deployment, highlighting key considerations for integrating generative AI into public sector software workflows.
Demonstration of Adapt4Me: An Uncertainty-Aware Authoring Environment for Personalizing Automatic Speech Recognition to Non-normative Speech
Mar 20, 2026Personalizing Automatic Speech Recognition (ASR) for non-normative speech remains challenging because data collection is labor-intensive and model training is technically complex. To address these limitations, we propose Adapt4Me, a web-based decentralized environment that operationalizes Bayesian active learning to enable end-to-end personalization without expert supervision. The app exposes data selection, adaptation, and validation to lay users through a three-stage human-in-the-loop workflow: (1) rapid profiling via greedy phoneme sampling to capture speaker-specific acoustics; (2) backend personalization using Variational Inference Low-Rank Adaptation (VI-LoRA) to enable fast, incremental updates; and (3) continuous improvement, where users guide model refinement by resolving visualized model uncertainty via low-friction top-k corrections. By making epistemic uncertainty explicit, Adapt4Me reframes data efficiency as an interactive design feature rather than a purely algorithmic concern. We show how this enables users to personalize robust ASR models, transforming them from passive data sources into active authors of their own assistive technology.
Evaluating the Effectiveness of Direct Preference Optimization for Personalizing German Automatic Text Simplifications for Persons with Intellectual Disabilities
Jul 02, 2025Automatic text simplification (ATS) aims to enhance language accessibility for various target groups, particularly persons with intellectual disabilities. Recent advancements in generative AI, especially large language models (LLMs), have substantially improved the quality of machine-generated text simplifications, thereby mitigating information barriers for the target group. However, existing LLM-based ATS systems do not incorporate preference feedback on text simplifications during training, resulting in a lack of personalization tailored to the specific needs of target group representatives. In this work, we extend the standard supervised fine-tuning (SFT) approach for adapting LLM-based ATS models by leveraging a computationally efficient LLM alignment technique -- direct preference optimization (DPO). Specifically, we post-train LLM-based ATS models using human feedback collected from persons with intellectual disabilities, reflecting their preferences on paired text simplifications generated by mainstream LLMs. Furthermore, we propose a pipeline for developing personalized LLM-based ATS systems, encompassing data collection, model selection, SFT and DPO post-training, and evaluation. Our findings underscore the necessity of active participation of target group persons in designing personalized AI accessibility solutions aligned with human expectations. This work represents a step towards personalizing inclusive AI systems at the target-group level, incorporating insights not only from text simplification experts but also from target group persons themselves.
Digitally Supported Analysis of Spontaneous Speech (DigiSpon): Benchmarking NLP-Supported Language Sample Analysis of Swiss Children's Speech
Apr 01, 2025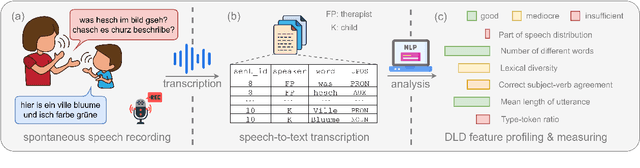

Language sample analysis (LSA) is a process that complements standardized psychometric tests for diagnosing, for example, developmental language disorder (DLD) in children. However, its labor-intensive nature has limited its use in speech-language pathology practice. We introduce an approach that leverages natural language processing (NLP) methods not based on commercial large language models (LLMs) applied to transcribed speech data from 119 children in the German speaking part of Switzerland with typical and atypical language development. The study aims to identify optimal practices that support speech-language pathologists in diagnosing DLD more efficiently within a human-in-the-loop framework, without relying on potentially unethical implementations that leverage commercial LLMs. Preliminary findings underscore the potential of integrating locally deployed NLP methods into the process of semi-automatic LSA.
SwiLTra-Bench: The Swiss Legal Translation Benchmark
Mar 03, 2025In Switzerland legal translation is uniquely important due to the country's four official languages and requirements for multilingual legal documentation. However, this process traditionally relies on professionals who must be both legal experts and skilled translators -- creating bottlenecks and impacting effective access to justice. To address this challenge, we introduce SwiLTra-Bench, a comprehensive multilingual benchmark of over 180K aligned Swiss legal translation pairs comprising laws, headnotes, and press releases across all Swiss languages along with English, designed to evaluate LLM-based translation systems. Our systematic evaluation reveals that frontier models achieve superior translation performance across all document types, while specialized translation systems excel specifically in laws but under-perform in headnotes. Through rigorous testing and human expert validation, we demonstrate that while fine-tuning open SLMs significantly improves their translation quality, they still lag behind the best zero-shot prompted frontier models such as Claude-3.5-Sonnet. Additionally, we present SwiLTra-Judge, a specialized LLM evaluation system that aligns best with human expert assessments.
SwissADT: An Audio Description Translation System for Swiss Languages
Nov 22, 2024Audio description (AD) is a crucial accessibility service provided to blind persons and persons with visual impairment, designed to convey visual information in acoustic form. Despite recent advancements in multilingual machine translation research, the lack of well-crafted and time-synchronized AD data impedes the development of audio description translation (ADT) systems that address the needs of multilingual countries such as Switzerland. Furthermore, since the majority of ADT systems rely solely on text, uncertainty exists as to whether incorporating visual information from the corresponding video clips can enhance the quality of ADT outputs. In this work, we present SwissADT, the first ADT system implemented for three main Swiss languages and English. By collecting well-crafted AD data augmented with video clips in German, French, Italian, and English, and leveraging the power of Large Language Models (LLMs), we aim to enhance information accessibility for diverse language populations in Switzerland by automatically translating AD scripts to the desired Swiss language. Our extensive experimental ADT results, composed of both automatic and human evaluations of ADT quality, demonstrate the promising capability of SwissADT for the ADT task. We believe that combining human expertise with the generation power of LLMs can further enhance the performance of ADT systems, ultimately benefiting a larger multilingual target population.
Audio Description Generation in the Era of LLMs and VLMs: A Review of Transferable Generative AI Technologies
Oct 11, 2024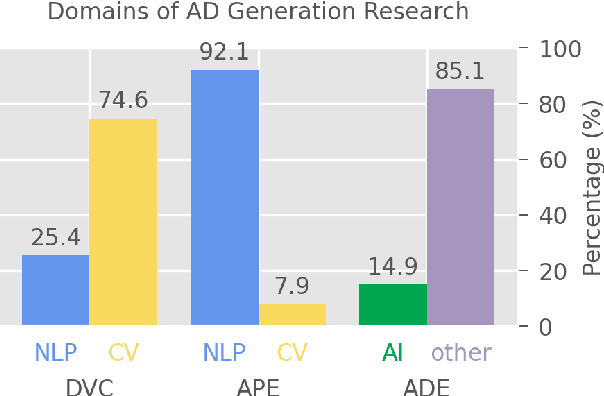



Audio descriptions (ADs) function as acoustic commentaries designed to assist blind persons and persons with visual impairments in accessing digital media content on television and in movies, among other settings. As an accessibility service typically provided by trained AD professionals, the generation of ADs demands significant human effort, making the process both time-consuming and costly. Recent advancements in natural language processing (NLP) and computer vision (CV), particularly in large language models (LLMs) and vision-language models (VLMs), have allowed for getting a step closer to automatic AD generation. This paper reviews the technologies pertinent to AD generation in the era of LLMs and VLMs: we discuss how state-of-the-art NLP and CV technologies can be applied to generate ADs and identify essential research directions for the future.
MODOC: A Modular Interface for Flexible Interlinking of Text Retrieval and Text Generation Functions
Aug 26, 2024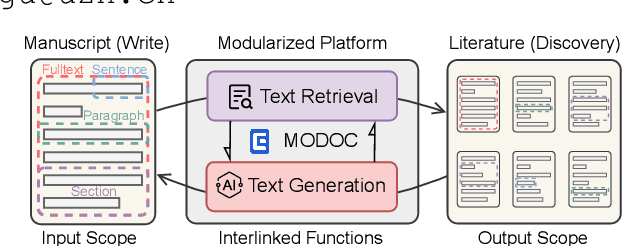
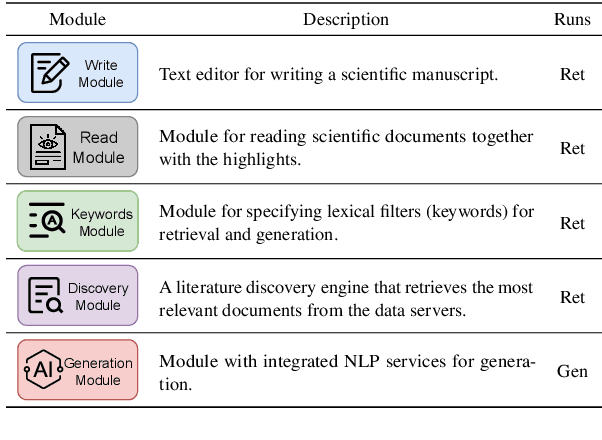
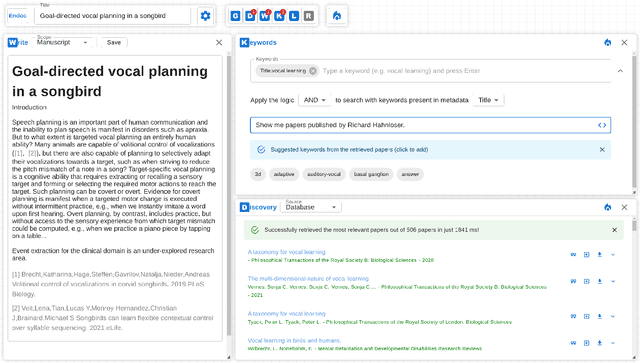
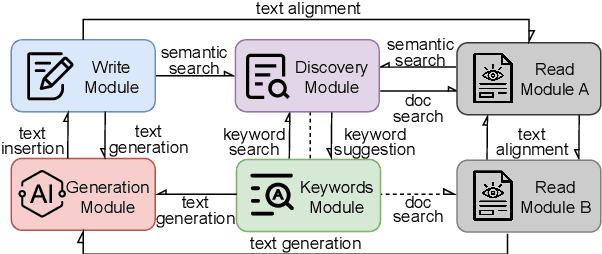
Large Language Models (LLMs) produce eloquent texts but often the content they generate needs to be verified. Traditional information retrieval systems can assist with this task, but most systems have not been designed with LLM-generated queries in mind. As such, there is a compelling need for integrated systems that provide both retrieval and generation functionality within a single user interface. We present MODOC, a modular user interface that leverages the capabilities of LLMs and provides assistance with detecting their confabulations, promoting integrity in scientific writing. MODOC represents a significant step forward in scientific writing assistance. Its modular architecture supports flexible functions for retrieving information and for writing and generating text in a single, user-friendly interface.