 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwissADT: An Audio Description Translation System for Swiss Languages
Nov 22, 2024Audio description (AD) is a crucial accessibility service provided to blind persons and persons with visual impairment, designed to convey visual information in acoustic form. Despite recent advancements in multilingual machine translation research, the lack of well-crafted and time-synchronized AD data impedes the development of audio description translation (ADT) systems that address the needs of multilingual countries such as Switzerland. Furthermore, since the majority of ADT systems rely solely on text, uncertainty exists as to whether incorporating visual information from the corresponding video clips can enhance the quality of ADT outputs. In this work, we present SwissADT, the first ADT system implemented for three main Swiss languages and English. By collecting well-crafted AD data augmented with video clips in German, French, Italian, and English, and leveraging the power of Large Language Models (LLMs), we aim to enhance information accessibility for diverse language populations in Switzerland by automatically translating AD scripts to the desired Swiss language. Our extensive experimental ADT results, composed of both automatic and human evaluations of ADT quality, demonstrate the promising capability of SwissADT for the ADT task. We believe that combining human expertise with the generation power of LLMs can further enhance the performance of ADT systems, ultimately benefiting a larger multilingual target population.
Audio Description Generation in the Era of LLMs and VLMs: A Review of Transferable Generative AI Technologies
Oct 11, 2024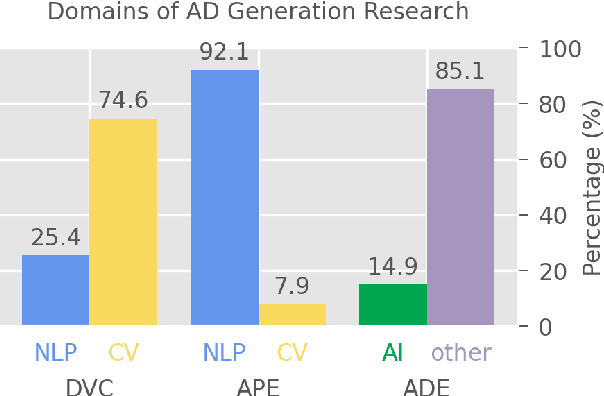



Audio descriptions (ADs) function as acoustic commentaries designed to assist blind persons and persons with visual impairments in accessing digital media content on television and in movies, among other settings. As an accessibility service typically provided by trained AD professionals, the generation of ADs demands significant human effort, making the process both time-consuming and costly. Recent advancements in natural language processing (NLP) and computer vision (CV), particularly in large language models (LLMs) and vision-language models (VLMs), have allowed for getting a step closer to automatic AD generation. This paper reviews the technologies pertinent to AD generation in the era of LLMs and VLMs: we discuss how state-of-the-art NLP and CV technologies can be applied to generate ADs and identify essential research directions for the future.
Kernel Affine Hull Machines for Differentially Private Learning
Apr 03, 2023

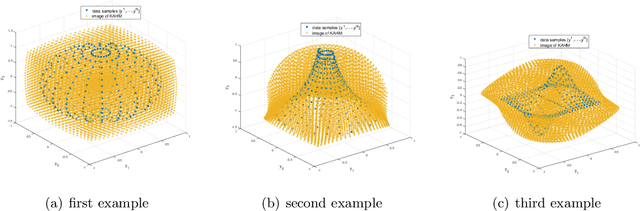

This paper explores the use of affine hulls of points as a means of representing data via learning in Reproducing Kernel Hilbert Spaces (RKHS), with the goal of partitioning the data space into geometric bodies that conceal privacy-sensitive information about individual data points, while preserving the structure of the original learning problem. To this end, we introduce the Kernel Affine Hull Machine (KAHM), which provides an effective way of computing a distance measure from the resulting bounded geometric body. KAHM is a critical building block in wide and deep autoencoders, which enable data representation learning for classification applications. To ensure privacy-preserving learning, we propose a novel method for generating fabricated data, which involves smoothing differentially private data samples through a transformation process. The resulting fabricated data guarantees not only differential privacy but also ensures that the KAHM modeling error is not larger than that of the original training data samples. We also address the accuracy-loss issue that arises with differentially private classifiers by using fabricated data. This approach results in a significant reduction in the risk of membership inference attacks while incurring only a marginal loss of accuracy. As an application, a KAHM based differentially private federated learning scheme is introduced featuring that the evaluation of global classifier requires only locally computed distance measures. Overall, our findings demonstrate the potential of KAHM as effective tool for privacy-preserving learning and classification.
Membership-Mappings for Practical Secure Distributed Deep Learning
Apr 12, 2022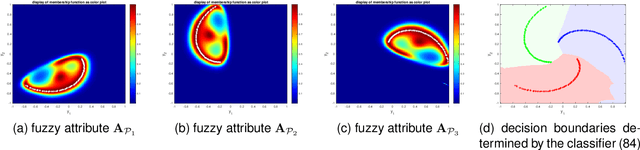
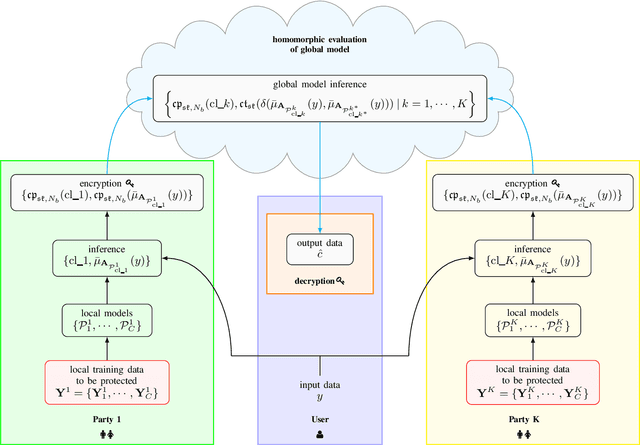
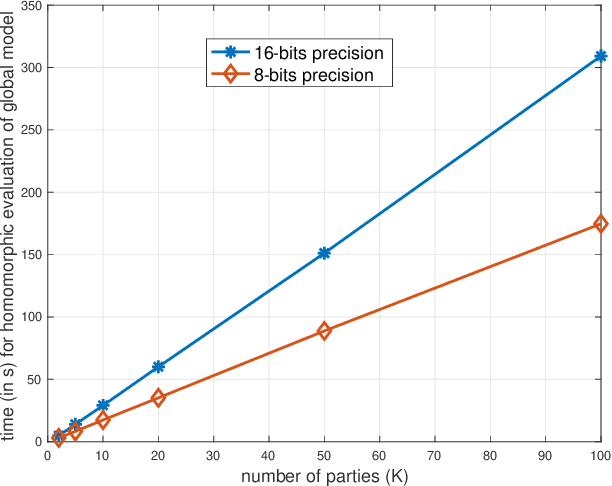
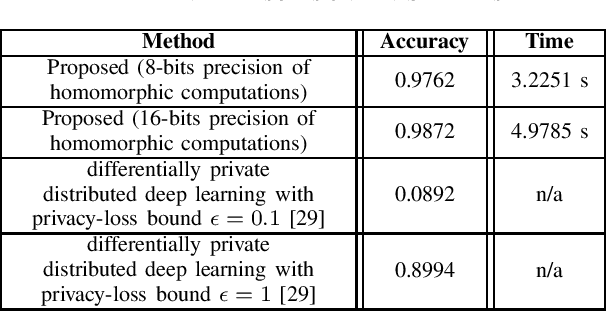
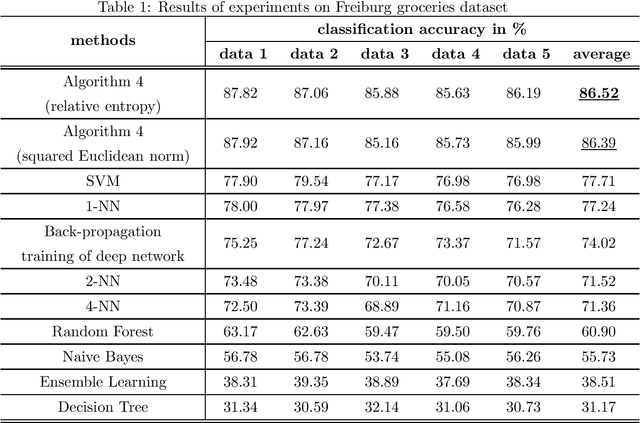
This study leverages the data representation capability of fuzzy based membership-mappings for practical secure distributed deep learning using fully homomorphic encryption. The impracticality issue of secure machine (deep) learning with fully homomorphic encrypted data, arising from large computational overhead, is addressed via applying fuzzy attributes. Fuzzy attributes are induced by globally convergent and robust variational membership-mappings based local deep models. Fuzzy attributes combine the local deep models in a robust and flexible manner such that the global model can be evaluated homomorphically in an efficient manner using a boolean circuit composed of bootstrapped binary gates. The proposed method, while preserving privacy in a distributed learning scenario, remains accurate, practical, and scalable. The method is evaluated through numerous experiments including demonstrations through MNIST dataset and Freiburg Groceries Dataset. Further, a biomedical application related to mental stress detection on individuals is considered.
Information Theoretic Evaluation of Privacy-Leakage, Interpretability, and Transferability for a Novel Trustworthy AI Framework
Jun 14, 2021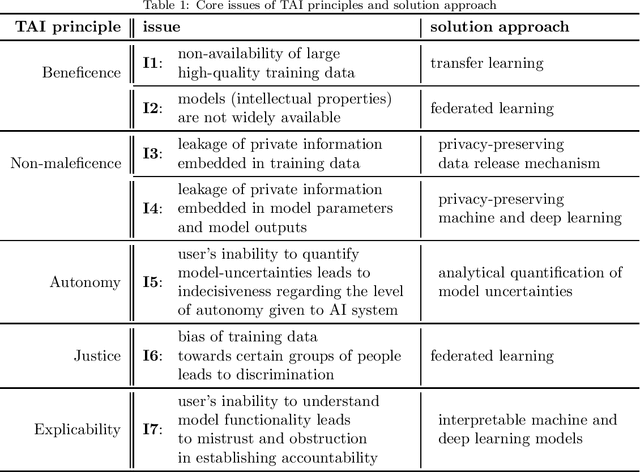
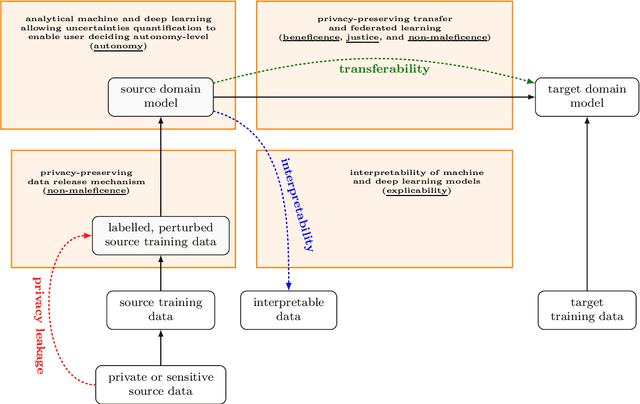
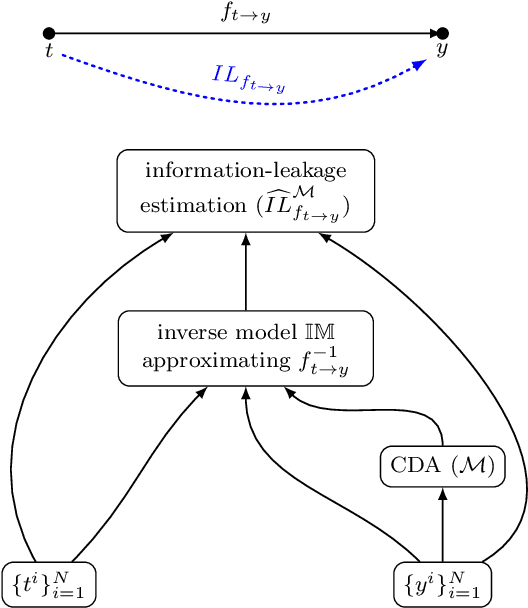

Guidelines and principles of trustworthy AI should be adhered to in practice during the development of AI systems. This work suggests a novel information theoretic trustworthy AI framework based on the hypothesis that information theory enables taking into account the ethical AI principles during the development of machine learning and deep learning models via providing a way to study and optimize the inherent tradeoffs between trustworthy AI principles. A unified approach to "privacy-preserving interpretable and transferable learning" is presented via introducing the information theoretic measures for privacy-leakage, interpretability, and transferability. A technique based on variational optimization, employing conditionally deep autoencoders, is developed for practically calculating the defined information theoretic measures for privacy-leakage, interpretability, and transferability.
Membership-Mappings for Data Representation Learning
Apr 14, 2021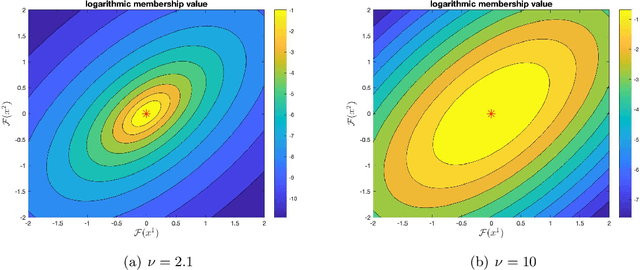
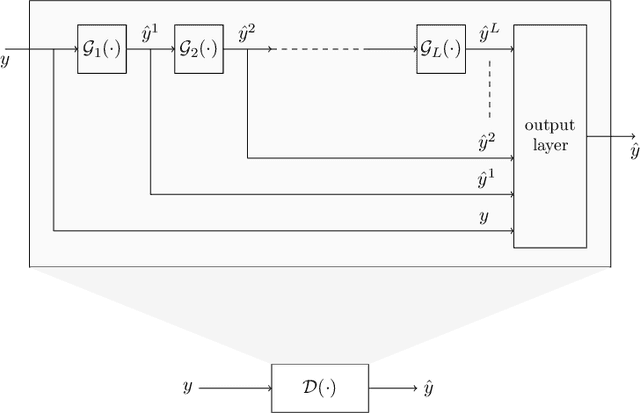
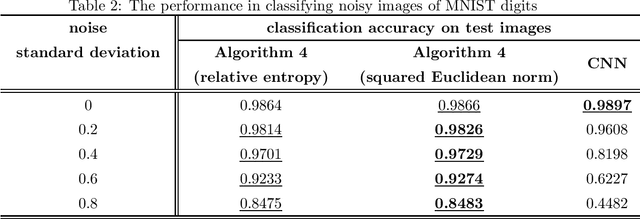
This study introduces using measure theoretic basis the notion of membership-mapping for representing data points through attribute values (motivated by fuzzy theory). A property of the membership-mapping, that can be exploited for data representation learning, is of providing an interpolation on the given data points in the data space. The study outlines an analytical approach to the variational learning of a membership-mappings based data representation model. An alternative idea of deep autoencoder, referred to as Bregman Divergence Based Conditionally Deep Autoencoder (that consists of layers such that each layer learns data representation at certain abstraction level through a membership-mappings based autoencoder), is presented. Experiments are provided to demonstrate the competitive performance of the proposed framework in classifying high-dimensional feature vectors and in rendering robustness to the classification.
What's the Difference Between Professional Human and Machine Translation? A Blind Multi-language Study on Domain-specific MT
Jun 08, 2020
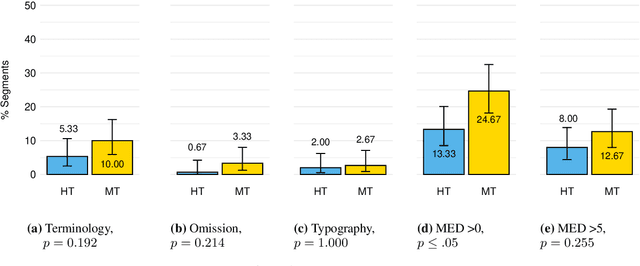

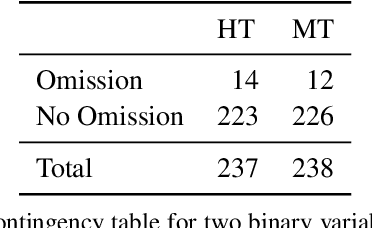
Machine translation (MT) has been shown to produce a number of errors that require human post-editing, but the extent to which professional human translation (HT) contains such errors has not yet been compared to MT. We compile pre-translated documents in which MT and HT are interleaved, and ask professional translators to flag errors and post-edit these documents in a blind evaluation. We find that the post-editing effort for MT segments is only higher in two out of three language pairs, and that the number of segments with wrong terminology, omissions, and typographical problems is similar in HT.
Deep Learning architectures for generalized immunofluorescence based nuclear image segmentation
Jul 30, 2019
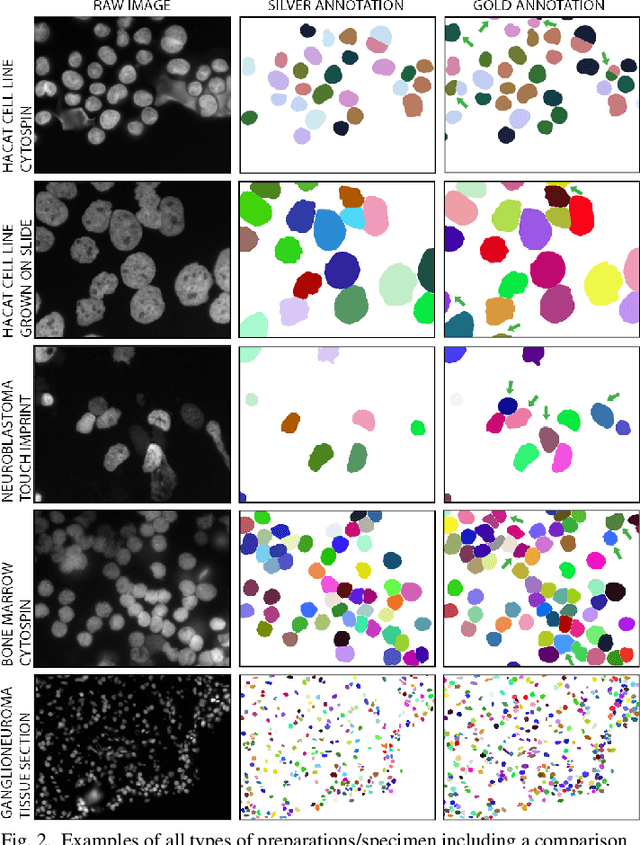
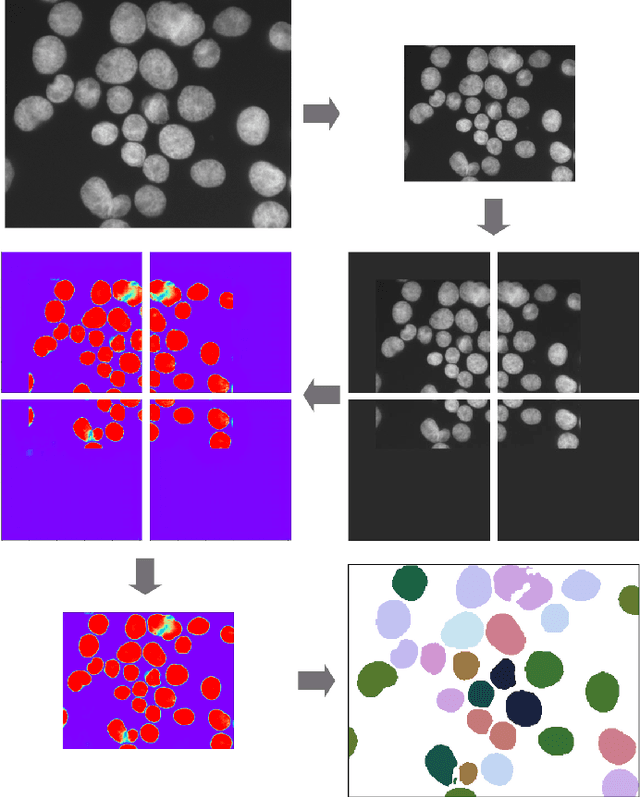

Separating and labeling each instance of a nucleus (instance-aware segmentation) is the key challenge in segmenting single cell nuclei on fluorescence microscopy images. Deep Neural Networks can learn the implicit transformation of a nuclear image into a probability map indicating the class membership of each pixel (nucleus or background), but the use of post-processing steps to turn the probability map into a labeled object mask is error-prone. This especially accounts for nuclear images of tissue sections and nuclear images across varying tissue preparations. In this work, we aim to evaluate the performance of state-of-the-art deep learning architectures to segment nuclei in fluorescence images of various tissue origins and sample preparation types without post-processing. We compare architectures that operate on pixel to pixel translation and an architecture that operates on object detection and subsequent locally applied segmentation. In addition, we propose a novel strategy to create artificial images to extend the training set. We evaluate the influence of ground truth annotation quality, image scale and segmentation complexity on segmentation performance. Results show that three out of four deep learning architectures (U-Net, U-Net with ResNet34 backbone, Mask R-CNN) can segment fluorescent nuclear images on most of the sample preparation types and tissue origins with satisfactory segmentation performance. Mask R-CNN, an architecture designed to address instance aware segmentation tasks, outperforms other architectures. Equal nuclear mean size, consistent nuclear annotations and the use of artificially generated images result in overall acceptable precision and recall across different tissues and sample preparation types.
On Conditioning GANs to Hierarchical Ontologies
May 16, 2019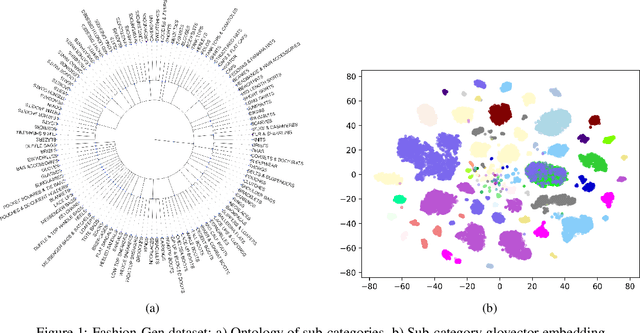
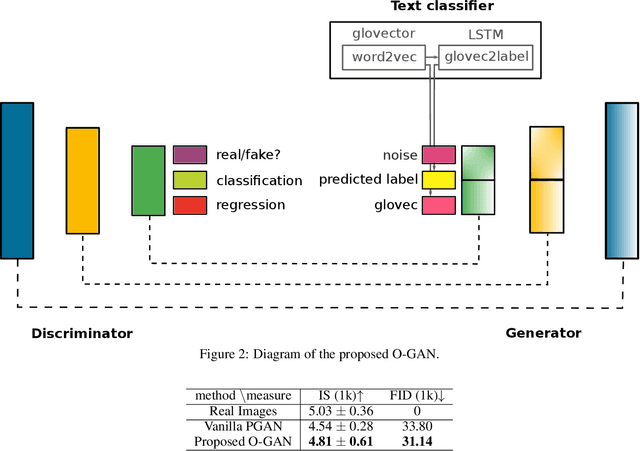


The recent success of Generative Adversarial Networks (GAN) is a result of their ability to generate high quality images from a latent vector space. An important application is the generation of images from a text description, where the text description is encoded and further used in the conditioning of the generated image. Thus the generative network has to additionally learn a mapping from the text latent vector space to a highly complex and multi-modal image data distribution, which makes the training of such models challenging. To handle the complexities of fashion image and meta data, we propose Ontology Generative Adversarial Networks (O-GANs) for fashion image synthesis that is conditioned on an hierarchical fashion ontology in order to improve the image generation fidelity. We show that the incorporation of the ontology leads to better image quality as measured by Fr\'{e}chet Inception Distance and Inception Score. Additionally, we show that the O-GAN achieves better conditioning results evaluated by implicit similarity between the text and the generated image.
Deep SNP: An End-to-end Deep Neural Network with Attention-based Localization for Break-point Detection in SNP Array Genomic data
Jun 22, 2018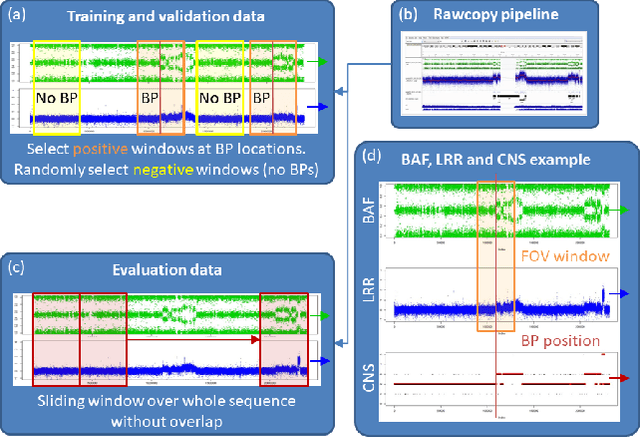

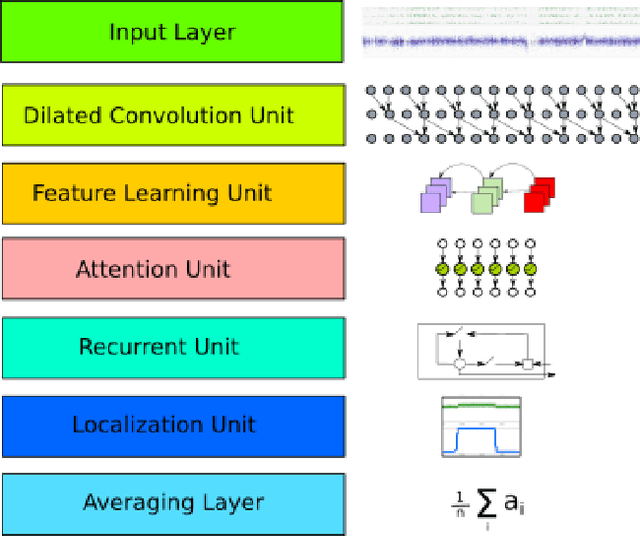
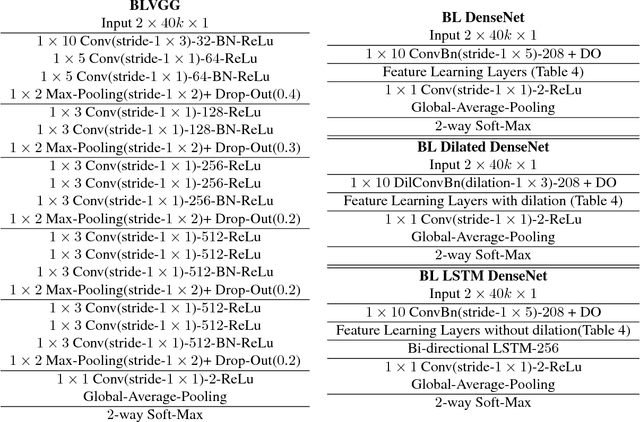
Diagnosis and risk stratification of cancer and many other diseases require the detection of genomic breakpoints as a prerequisite of calling copy number alterations (CNA). This, however, is still challenging and requires time-consuming manual curation. As deep-learning methods outperformed classical state-of-the-art algorithms in various domains and have also been successfully applied to life science problems including medicine and biology, we here propose Deep SNP, a novel Deep Neural Network to learn from genomic data. Specifically, we used a manually curated dataset from 12 genomic single nucleotide polymorphism array (SNPa) profiles as truth-set and aimed at predicting the presence or absence of genomic breakpoints, an indicator of structural chromosomal variations, in windows of 40,000 probes. We compare our results with well-known neural network models as well as Rawcopy though this tool is designed to predict breakpoints and in addition genomic segments with high sensitivity. We show, that Deep SNP is capable of successfully predicting the presence or absence of a breakpoint in large genomic windows and outperforms state-of-the-art neural network models. Qualitative examples suggest that integration of a localization unit may enable breakpoint detection and prediction of genomic segments, even if the breakpoint coordinates were not provided for network training. These results warrant further evaluation of DeepSNP for breakpoint localization and subsequent calling of genomic segments.