 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAddressing Parameter Choice Issues in Unsupervised Domain Adaptation by Aggregation
May 02, 2023



We study the problem of choosing algorithm hyper-parameters in unsupervised domain adaptation, i.e., with labeled data in a source domain and unlabeled data in a target domain, drawn from a different input distribution. We follow the strategy to compute several models using different hyper-parameters, and, to subsequently compute a linear aggregation of the models. While several heuristics exist that follow this strategy, methods are still missing that rely on thorough theories for bounding the target error. In this turn, we propose a method that extends weighted least squares to vector-valued functions, e.g., deep neural networks. We show that the target error of the proposed algorithm is asymptotically not worse than twice the error of the unknown optimal aggregation. We also perform a large scale empirical comparative study on several datasets, including text, images, electroencephalogram, body sensor signals and signals from mobile phones. Our method outperforms deep embedded validation (DEV) and importance weighted validation (IWV) on all datasets, setting a new state-of-the-art performance for solving parameter choice issues in unsupervised domain adaptation with theoretical error guarantees. We further study several competitive heuristics, all outperforming IWV and DEV on at least five datasets. However, our method outperforms each heuristic on at least five of seven datasets.
* Oral talk (notable-top-5%) at International Conference On Learning Representations (ICLR), 2023
Learning General Audio Representations with Large-Scale Training of Patchout Audio Transformers
Nov 25, 2022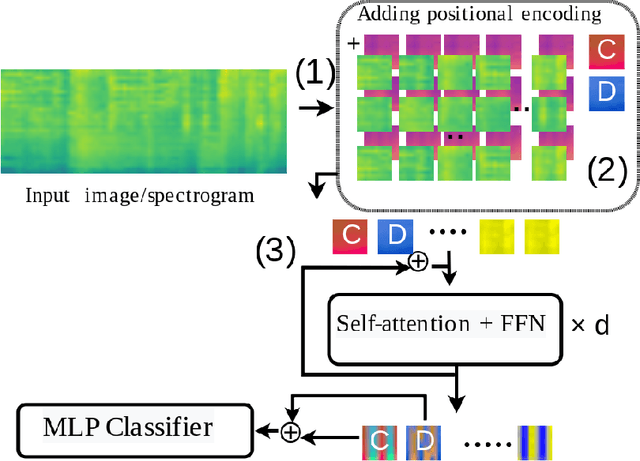


The success of supervised deep learning methods is largely due to their ability to learn relevant features from raw data. Deep Neural Networks (DNNs) trained on large-scale datasets are capable of capturing a diverse set of features, and learning a representation that can generalize onto unseen tasks and datasets that are from the same domain. Hence, these models can be used as powerful feature extractors, in combination with shallower models as classifiers, for smaller tasks and datasets where the amount of training data is insufficient for learning an end-to-end model from scratch. During the past years, Convolutional Neural Networks (CNNs) have largely been the method of choice for audio processing. However, recently attention-based transformer models have demonstrated great potential in supervised settings, outperforming CNNs. In this work, we investigate the use of audio transformers trained on large-scale datasets to learn general-purpose representations. We study how the different setups in these audio transformers affect the quality of their embeddings. We experiment with the models' time resolution, extracted embedding level, and receptive fields in order to see how they affect performance on a variety of tasks and datasets, following the HEAR 2021 NeurIPS challenge evaluation setup. Our results show that representations extracted by audio transformers outperform CNN representations. Furthermore, we will show that transformers trained on Audioset can be extremely effective representation extractors for a wide range of downstream tasks.
Reactive Exploration to Cope with Non-Stationarity in Lifelong Reinforcement Learning
Jul 12, 2022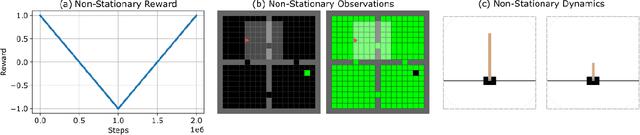
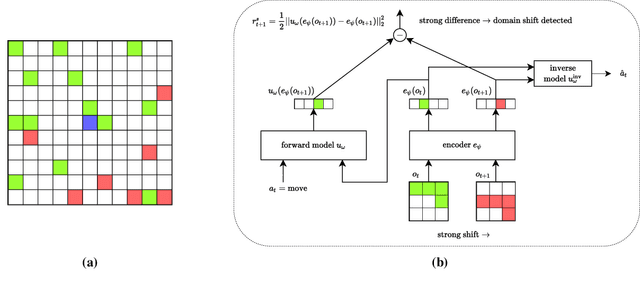
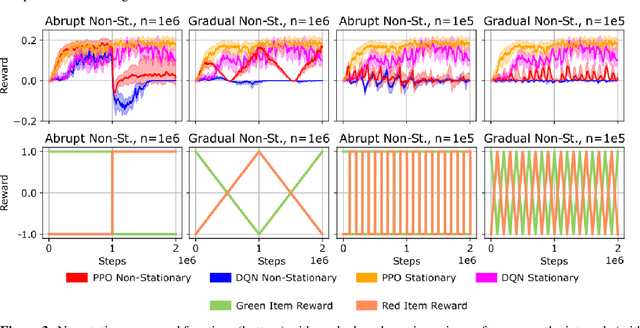
In lifelong learning, an agent learns throughout its entire life without resets, in a constantly changing environment, as we humans do. Consequently, lifelong learning comes with a plethora of research problems such as continual domain shifts, which result in non-stationary rewards and environment dynamics. These non-stationarities are difficult to detect and cope with due to their continuous nature. Therefore, exploration strategies and learning methods are required that are capable of tracking the steady domain shifts, and adapting to them. We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. To this end, we conduct experiments in order to investigate different exploration strategies. We empirically show that representatives of the policy-gradient family are better suited for lifelong learning, as they adapt more quickly to distribution shifts than Q-learning. Thereby, policy-gradient methods profit the most from Reactive Exploration and show good results in lifelong learning with continual domain shifts. Our code is available at: https://github.com/ml-jku/reactive-exploration.
Few-Shot Learning by Dimensionality Reduction in Gradient Space
Jun 07, 2022
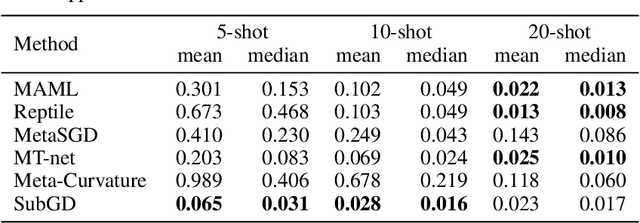
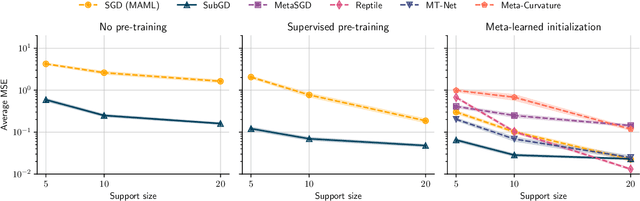
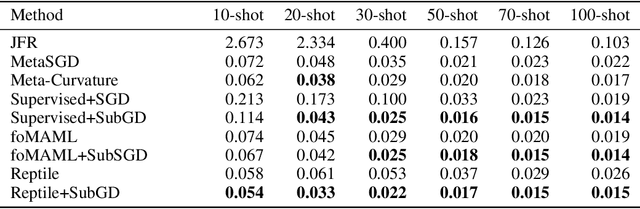
We introduce SubGD, a novel few-shot learning method which is based on the recent finding that stochastic gradient descent updates tend to live in a low-dimensional parameter subspace. In experimental and theoretical analyses, we show that models confined to a suitable predefined subspace generalize well for few-shot learning. A suitable subspace fulfills three criteria across the given tasks: it (a) allows to reduce the training error by gradient flow, (b) leads to models that generalize well, and (c) can be identified by stochastic gradient descent. SubGD identifies these subspaces from an eigendecomposition of the auto-correlation matrix of update directions across different tasks. Demonstrably, we can identify low-dimensional suitable subspaces for few-shot learning of dynamical systems, which have varying properties described by one or few parameters of the analytical system description. Such systems are ubiquitous among real-world applications in science and engineering. We experimentally corroborate the advantages of SubGD on three distinct dynamical systems problem settings, significantly outperforming popular few-shot learning methods both in terms of sample efficiency and performance.
History Compression via Language Models in Reinforcement Learning
May 24, 2022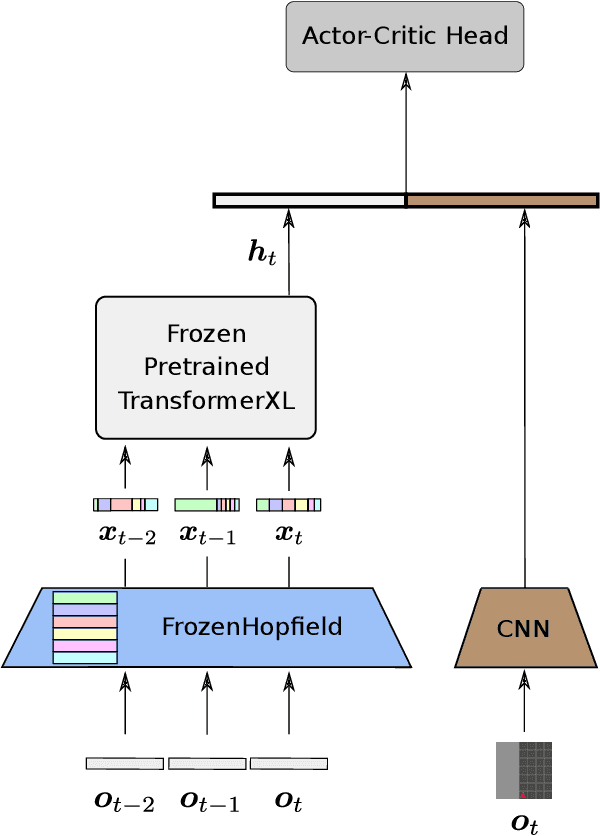

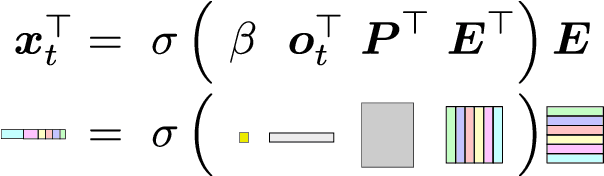

In a partially observable Markov decision process (POMDP), an agent typically uses a representation of the past to approximate the underlying MDP. We propose to utilize a frozen Pretrained Language Transformer (PLT) for history representation and compression to improve sample efficiency. To avoid training of the Transformer, we introduce FrozenHopfield, which automatically associates observations with original token embeddings. To form these associations, a modern Hopfield network stores the original token embeddings, which are retrieved by queries that are obtained by a random but fixed projection of observations. Our new method, HELM, enables actor-critic network architectures that contain a pretrained language Transformer for history representation as a memory module. Since a representation of the past need not be learned, HELM is much more sample efficient than competitors. On Minigrid and Procgen environments HELM achieves new state-of-the-art results. Our code is available at https://github.com/ml-jku/helm.
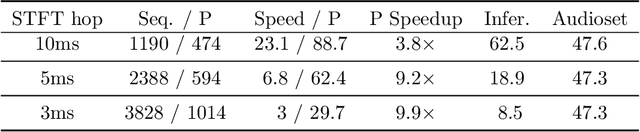
Efficient Training of Audio Transformers with Patchout
Oct 29, 2021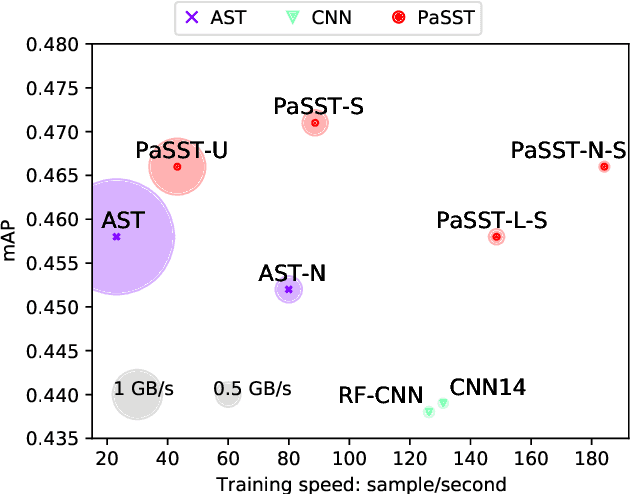
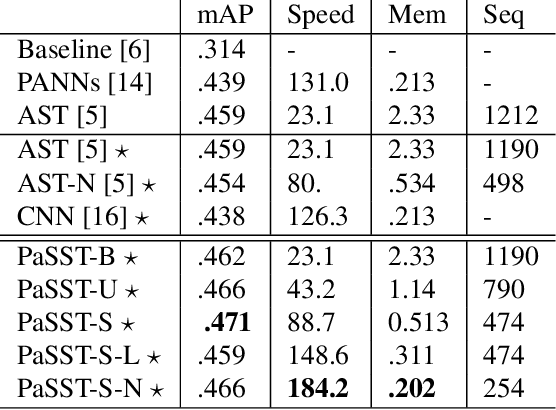
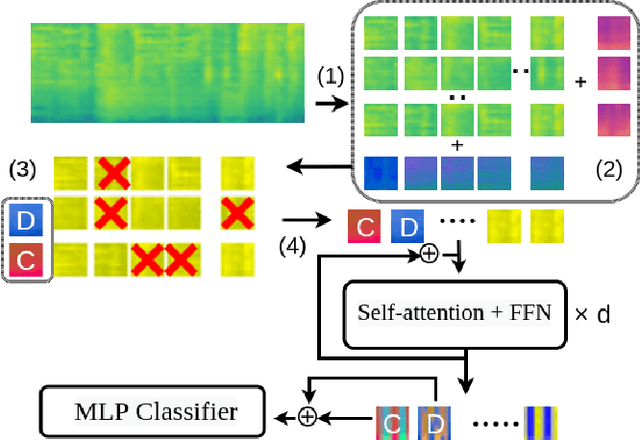

The great success of transformer-based models in natural language processing (NLP) has led to various attempts at adapting these architectures to other domains such as vision and audio. Recent work has shown that transformers can outperform Convolutional Neural Networks (CNNs) on vision and audio tasks. However, one of the main shortcomings of transformer models, compared to the well-established CNNs, is the computational complexity. Compute and memory complexity grow quadratically with the input length. Therefore, there has been extensive work on optimizing transformers, but often at the cost of lower predictive performance. In this work, we propose a novel method to optimize and regularize transformers on audio spectrograms. The proposed models achieve a new state-of-the-art performance on Audioset and can be trained on a single consumer-grade GPU. Furthermore, we propose a transformer model that outperforms CNNs in terms of both performance and training speed.
Over-Parameterization and Generalization in Audio Classification
Jul 19, 2021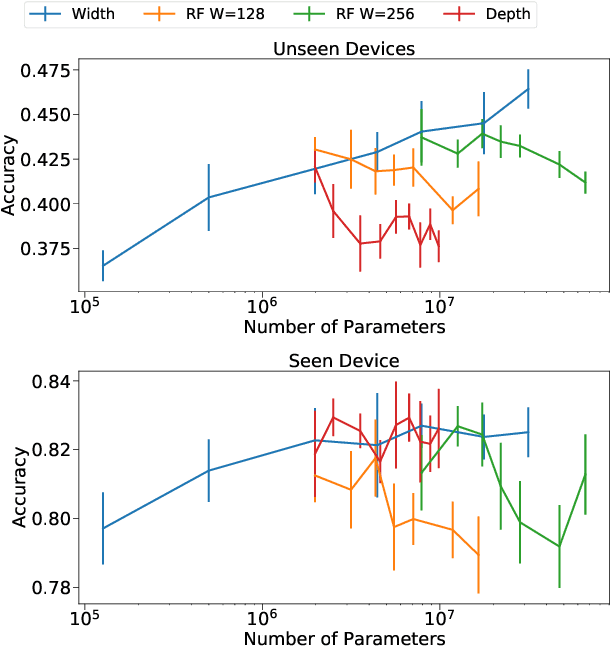
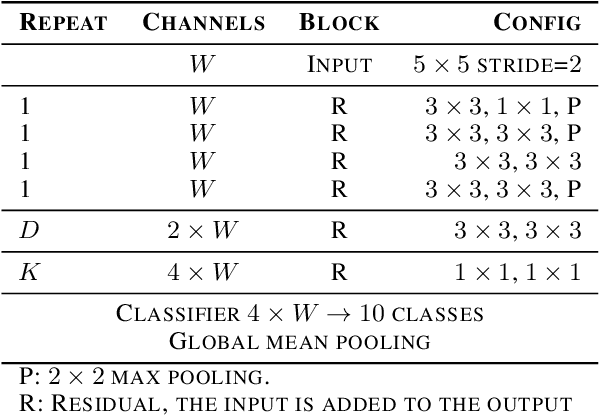
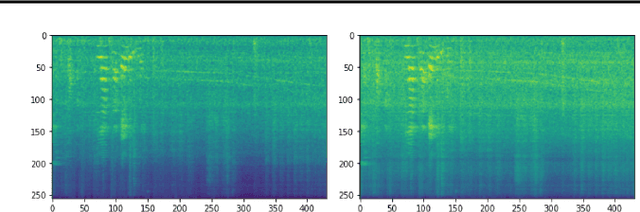
Convolutional Neural Networks (CNNs) have been dominating classification tasks in various domains, such as machine vision, machine listening, and natural language processing. In machine listening, while generally exhibiting very good generalization capabilities, CNNs are sensitive to the specific audio recording device used, which has been recognized as a substantial problem in the acoustic scene classification (DCASE) community. In this study, we investigate the relationship between over-parameterization of acoustic scene classification models, and their resulting generalization abilities. Specifically, we test scaling CNNs in width and depth, under different conditions. Our results indicate that increasing width improves generalization to unseen devices, even without an increase in the number of parameters.
Receptive Field Regularization Techniques for Audio Classification and Tagging with Deep Convolutional Neural Networks
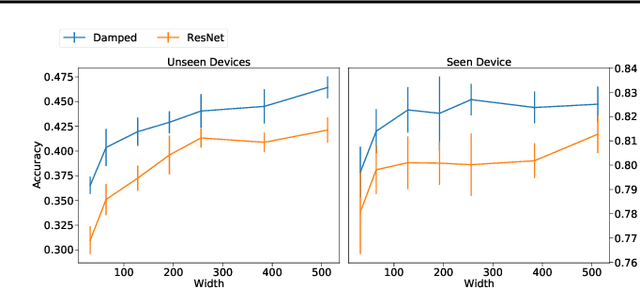
May 26, 2021
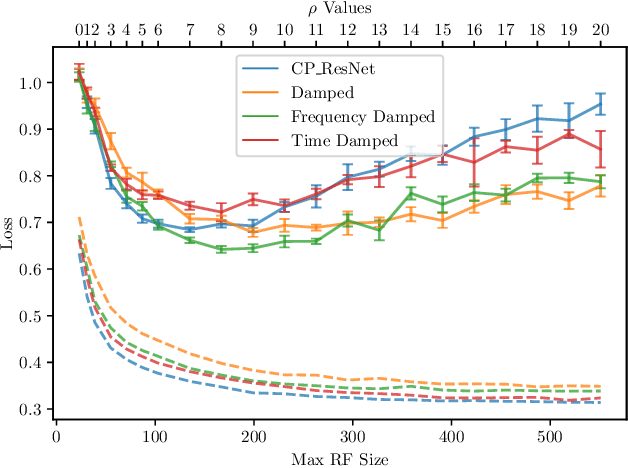
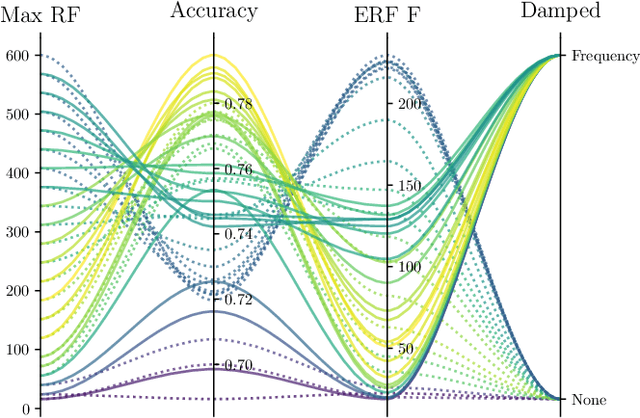
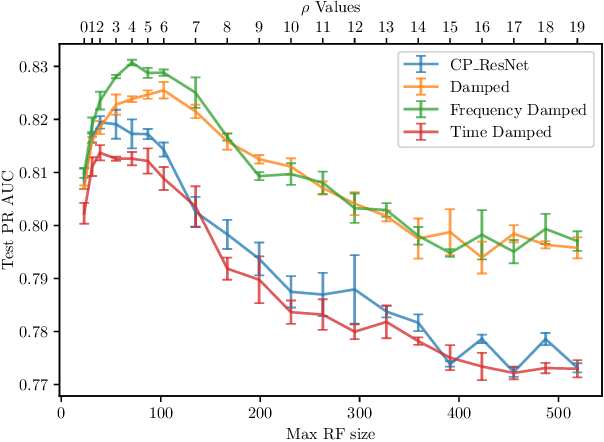
In this paper, we study the performance of variants of well-known Convolutional Neural Network (CNN) architectures on different audio tasks. We show that tuning the Receptive Field (RF) of CNNs is crucial to their generalization. An insufficient RF limits the CNN's ability to fit the training data. In contrast, CNNs with an excessive RF tend to over-fit the training data and fail to generalize to unseen testing data. As state-of-the-art CNN architectures-in computer vision and other domains-tend to go deeper in terms of number of layers, their RF size increases and therefore they degrade in performance in several audio classification and tagging tasks. We study well-known CNN architectures and how their building blocks affect their receptive field. We propose several systematic approaches to control the RF of CNNs and systematically test the resulting architectures on different audio classification and tagging tasks and datasets. The experiments show that regularizing the RF of CNNs using our proposed approaches can drastically improve the generalization of models, out-performing complex architectures and pre-trained models on larger datasets. The proposed CNNs achieve state-of-the-art results in multiple tasks, from acoustic scene classification to emotion and theme detection in music to instrument recognition, as demonstrated by top ranks in several pertinent challenges (DCASE, MediaEval).
Low-Complexity Models for Acoustic Scene Classification Based on Receptive Field Regularization and Frequency Damping
Nov 05, 2020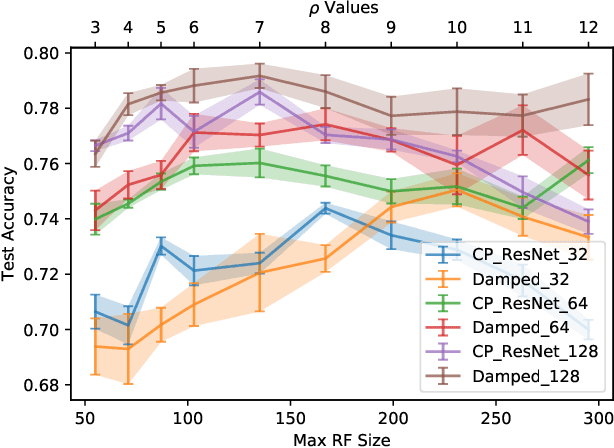
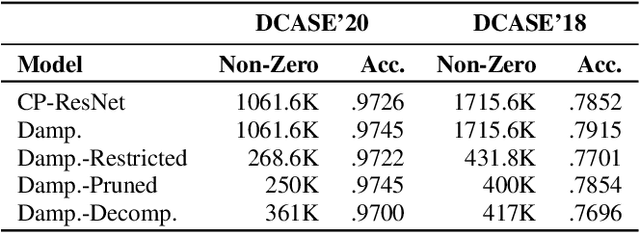
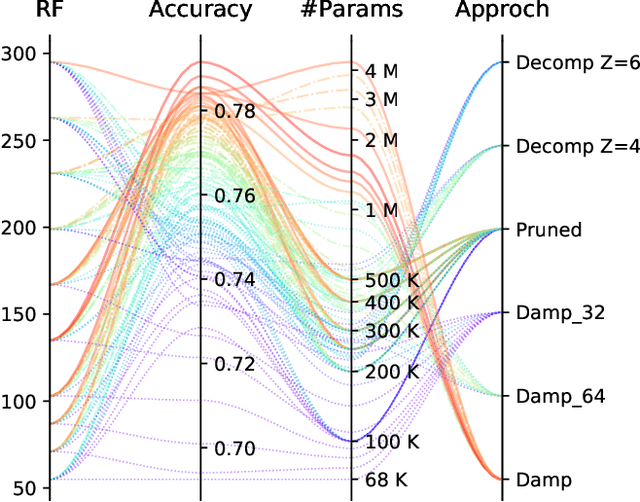
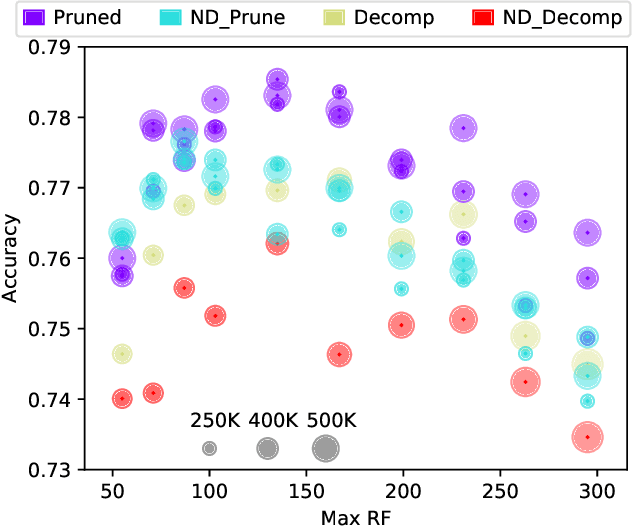
Deep Neural Networks are known to be very demanding in terms of computing and memory requirements. Due to the ever increasing use of embedded systems and mobile devices with a limited resource budget, designing low-complexity models without sacrificing too much of their predictive performance gained great importance. In this work, we investigate and compare several well-known methods to reduce the number of parameters in neural networks. We further put these into the context of a recent study on the effect of the Receptive Field (RF) on a model's performance, and empirically show that we can achieve high-performing low-complexity models by applying specific restrictions on the RFs, in combination with parameter reduction methods. Additionally, we propose a filter-damping technique for regularizing the RF of models, without altering their architecture and changing their parameter counts. We will show that incorporating this technique improves the performance in various low-complexity settings such as pruning and decomposed convolution. Using our proposed filter damping, we achieved the 1st rank at the DCASE-2020 Challenge in the task of Low-Complexity Acoustic Scene Classification.
On Data Augmentation and Adversarial Risk: An Empirical Analysis
Jul 06, 2020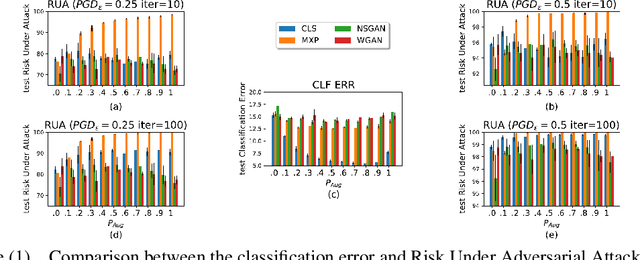
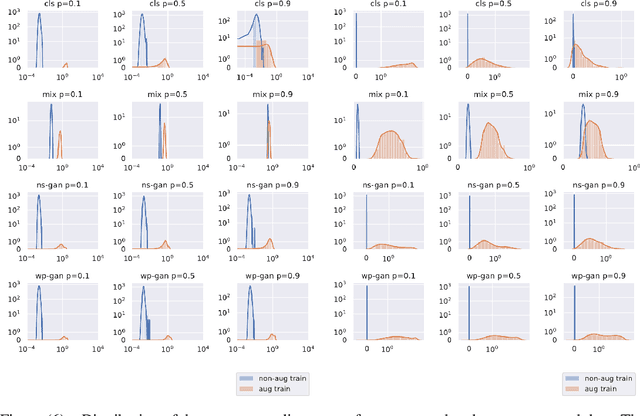
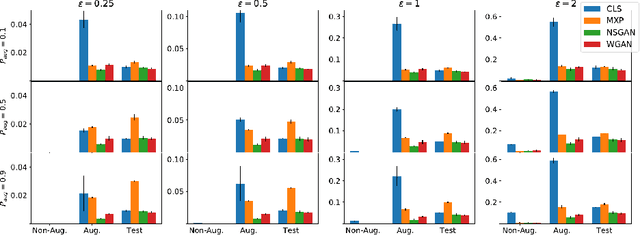
Data augmentation techniques have become standard practice in deep learning, as it has been shown to greatly improve the generalisation abilities of models. These techniques rely on different ideas such as invariance-preserving transformations (e.g, expert-defined augmentation), statistical heuristics (e.g, Mixup), and learning the data distribution (e.g, GANs). However, in the adversarial settings it remains unclear under what conditions such data augmentation methods reduce or even worsen the misclassification risk. In this paper, we therefore analyse the effect of different data augmentation techniques on the adversarial risk by three measures: (a) the well-known risk under adversarial attacks, (b) a new measure of prediction-change stress based on the Laplacian operator, and (c) the influence of training examples on prediction. The results of our empirical analysis disprove the hypothesis that an improvement in the classification performance induced by a data augmentation is always accompanied by an improvement in the risk under adversarial attack. Further, our results reveal that the augmented data has more influence than the non-augmented data, on the resulting models. Taken together, our results suggest that general-purpose data augmentations that do not take into the account the characteristics of the data and the task, must be applied with care.