 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReactive Exploration to Cope with Non-Stationarity in Lifelong Reinforcement Learning
Jul 12, 2022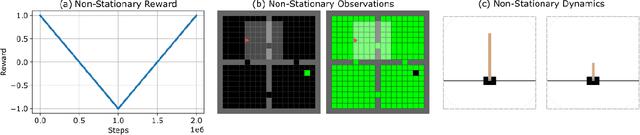
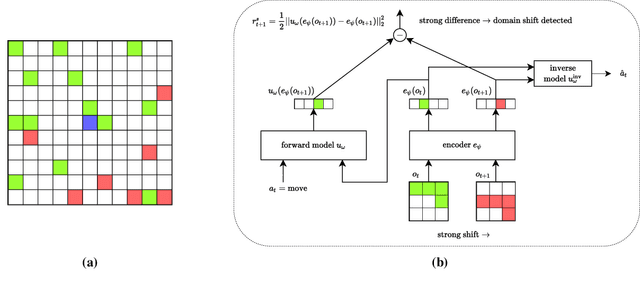
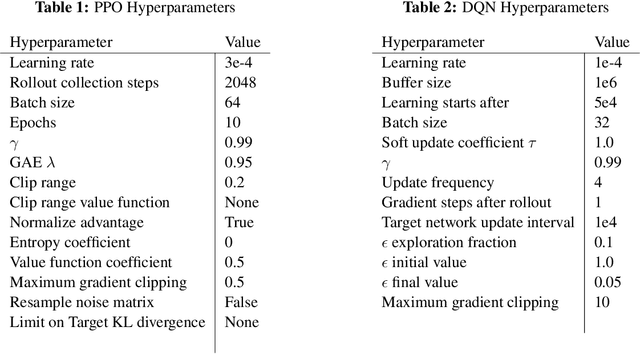
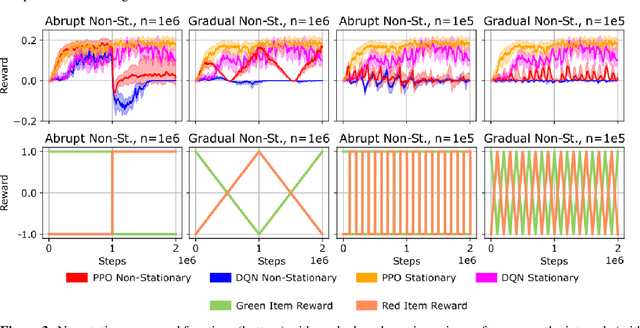
In lifelong learning, an agent learns throughout its entire life without resets, in a constantly changing environment, as we humans do. Consequently, lifelong learning comes with a plethora of research problems such as continual domain shifts, which result in non-stationary rewards and environment dynamics. These non-stationarities are difficult to detect and cope with due to their continuous nature. Therefore, exploration strategies and learning methods are required that are capable of tracking the steady domain shifts, and adapting to them. We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. To this end, we conduct experiments in order to investigate different exploration strategies. We empirically show that representatives of the policy-gradient family are better suited for lifelong learning, as they adapt more quickly to distribution shifts than Q-learning. Thereby, policy-gradient methods profit the most from Reactive Exploration and show good results in lifelong learning with continual domain shifts. Our code is available at: https://github.com/ml-jku/reactive-exploration.
Exploring Visual Patterns in Projected Human and Machine Decision-Making Paths
Jan 20, 2020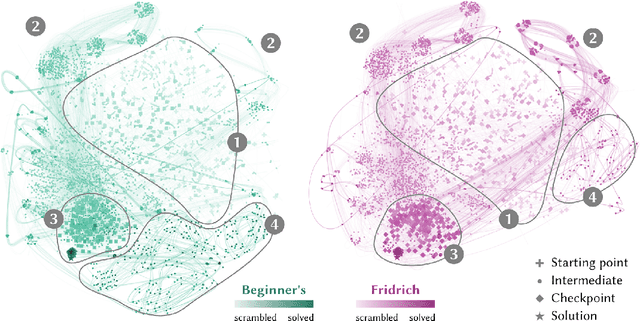


In problem solving, the paths towards solutions can be viewed as a sequence of decisions. The decisions, made by humans or computers, describe a trajectory through a high-dimensional representation space of the problem. Using dimensionality reduction, these trajectories can be visualized in lower dimensional space. Such embedded trajectories have previously been applied to a wide variety of data, but so far, almost exclusively the self-similarity of single trajectories has been analyzed. In contrast, we describe patterns emerging from drawing many trajectories---for different initial conditions, end states, or solution strategies---in the same embedding space. We argue that general statements about the problem solving tasks and solving strategies can be made by interpreting these patterns. We explore and characterize such patterns in trajectories resulting from human and machine-made decisions in a variety of application domains: logic puzzles (Rubik's cube), strategy games (chess), and optimization problems (neural network training). In the context of Rubik's cube, we present a physical interactive demonstrator that uses trajectory visualization to provide immediate feedback to users regarding the consequences of their decisions. We also discuss the importance of suitably chosen representation spaces and similarity metrics for the embedding.