 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing CUDA like a Human: Micro-Profiling Tools as Expert Surrogates for LLM-Based GPU Kernel Optimization
Jun 24, 2026We present KernelPro, a closed-loop multi-agent system that automatically generates, profiles, and iteratively optimizes GPU kernel code by integrating large language model (LLM) code generation with hardware profiler feedback and pluggable bottleneck detection tools. KernelPro introduces four contributions: (1) a semantic feedback operator that encodes expert heuristics as pluggable micro-profiling tools, transforming raw hardware metrics into actionable natural language guidance; (2) a two-stage tool invocation architecture where roofline-based bottleneck classification filters which specialized analysis tools execute, combining kernel-level (ncu), instruction-level (SASS), and system-level (nsys) profiling; (3) a domain-adapted MCTS with progressive widening, asymmetric branching, log-reward calibration, dead-end pruning, and search memory for cross-iteration learning; and (4) direct CuTe source-level code generation via autonomous code search over the CUTLASS/CuTe codebase. On KernelBench, KernelPro achieves geometric mean speedups of 2.42x/4.69x/5.30x on Levels 1/2/3, establishing state-of-the-art performance across all difficulty levels. On VeOmni's expert-optimized MoE training kernels, KernelPro achieves 1.23x over hand-tuned Triton by generating a from-scratch raw-CUDA+CuTe Hopper WGMMA kernel. Ablation studies demonstrate that each design component independently and significantly improves optimization quality: micro-profiling tools (p < 0.0001 vs raw metrics), MCTS search (26% higher geometric mean vs greedy, p = 0.004), and proactive tool orchestration (23% improvement, p = 0.035). Finally, KernelPro is the first CUDA kernel coding agent to optimize energy efficiency beyond the speed-only focus of prior systems, demonstrating an 11.6% measured energy reduction at matched speed.
A Large Recurrent Action Model: xLSTM enables Fast Inference for Robotics Tasks
Oct 29, 2024In recent years, there has been a trend in the field of Reinforcement Learning (RL) towards large action models trained offline on large-scale datasets via sequence modeling. Existing models are primarily based on the Transformer architecture, which result in powerful agents. However, due to slow inference times, Transformer-based approaches are impractical for real-time applications, such as robotics. Recently, modern recurrent architectures, such as xLSTM and Mamba, have been proposed that exhibit parallelization benefits during training similar to the Transformer architecture while offering fast inference. In this work, we study the aptitude of these modern recurrent architectures for large action models. Consequently, we propose a Large Recurrent Action Model (LRAM) with an xLSTM at its core that comes with linear-time inference complexity and natural sequence length extrapolation abilities. Experiments on 432 tasks from 6 domains show that LRAM compares favorably to Transformers in terms of performance and speed.
Retrieval-Augmented Decision Transformer: External Memory for In-context RL
Oct 09, 2024



In-context learning (ICL) is the ability of a model to learn a new task by observing a few exemplars in its context. While prevalent in NLP, this capability has recently also been observed in Reinforcement Learning (RL) settings. Prior in-context RL methods, however, require entire episodes in the agent's context. Given that complex environments typically lead to long episodes with sparse rewards, these methods are constrained to simple environments with short episodes. To address these challenges, we introduce Retrieval-Augmented Decision Transformer (RA-DT). RA-DT employs an external memory mechanism to store past experiences from which it retrieves only sub-trajectories relevant for the current situation. The retrieval component in RA-DT does not require training and can be entirely domain-agnostic. We evaluate the capabilities of RA-DT on grid-world environments, robotics simulations, and procedurally-generated video games. On grid-worlds, RA-DT outperforms baselines, while using only a fraction of their context length. Furthermore, we illuminate the limitations of current in-context RL methods on complex environments and discuss future directions. To facilitate future research, we release datasets for four of the considered environments.
Contrastive Abstraction for Reinforcement Learning
Oct 01, 2024



Learning agents with reinforcement learning is difficult when dealing with long trajectories that involve a large number of states. To address these learning problems effectively, the number of states can be reduced by abstract representations that cluster states. In principle, deep reinforcement learning can find abstract states, but end-to-end learning is unstable. We propose contrastive abstraction learning to find abstract states, where we assume that successive states in a trajectory belong to the same abstract state. Such abstract states may be basic locations, achieved subgoals, inventory, or health conditions. Contrastive abstraction learning first constructs clusters of state representations by contrastive learning and then applies modern Hopfield networks to determine the abstract states. The first phase of contrastive abstraction learning is self-supervised learning, where contrastive learning forces states with sequential proximity to have similar representations. The second phase uses modern Hopfield networks to map similar state representations to the same fixed point, i.e.\ to an abstract state. The level of abstraction can be adjusted by determining the number of fixed points of the modern Hopfield network. Furthermore, \textit{contrastive abstraction learning} does not require rewards and facilitates efficient reinforcement learning for a wide range of downstream tasks. Our experiments demonstrate the effectiveness of contrastive abstraction learning for reinforcement learning.
Simplified priors for Object-Centric Learning
Oct 01, 2024



Humans excel at abstracting data and constructing \emph{reusable} concepts, a capability lacking in current continual learning systems. The field of object-centric learning addresses this by developing abstract representations, or slots, from data without human supervision. Different methods have been proposed to tackle this task for images, whereas most are overly complex, non-differentiable, or poorly scalable. In this paper, we introduce a conceptually simple, fully-differentiable, non-iterative, and scalable method called SAMP Simplified Slot Attention with Max Pool Priors). It is implementable using only Convolution and MaxPool layers and an Attention layer. Our method encodes the input image with a Convolutional Neural Network and then uses a branch of alternating Convolution and MaxPool layers to create specialized sub-networks and extract primitive slots. These primitive slots are then used as queries for a Simplified Slot Attention over the encoded image. Despite its simplicity, our method is competitive or outperforms previous methods on standard benchmarks.
Reactive Exploration to Cope with Non-Stationarity in Lifelong Reinforcement Learning
Jul 12, 2022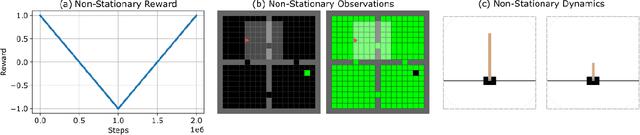
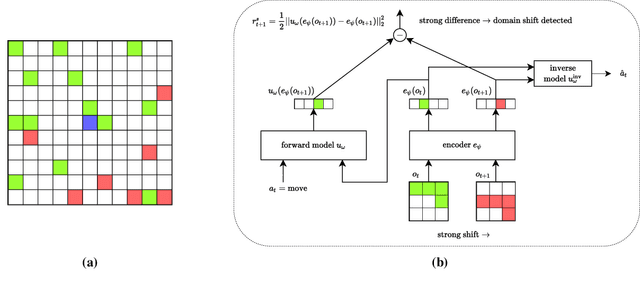
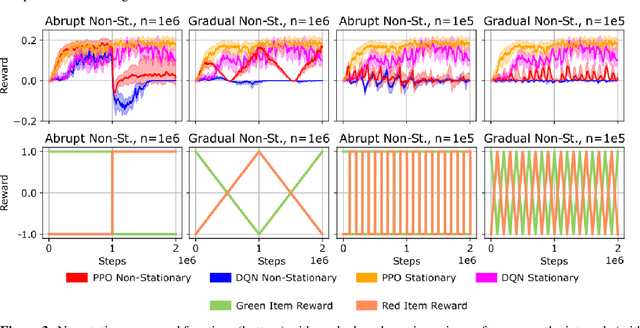
In lifelong learning, an agent learns throughout its entire life without resets, in a constantly changing environment, as we humans do. Consequently, lifelong learning comes with a plethora of research problems such as continual domain shifts, which result in non-stationary rewards and environment dynamics. These non-stationarities are difficult to detect and cope with due to their continuous nature. Therefore, exploration strategies and learning methods are required that are capable of tracking the steady domain shifts, and adapting to them. We propose Reactive Exploration to track and react to continual domain shifts in lifelong reinforcement learning, and to update the policy correspondingly. To this end, we conduct experiments in order to investigate different exploration strategies. We empirically show that representatives of the policy-gradient family are better suited for lifelong learning, as they adapt more quickly to distribution shifts than Q-learning. Thereby, policy-gradient methods profit the most from Reactive Exploration and show good results in lifelong learning with continual domain shifts. Our code is available at: https://github.com/ml-jku/reactive-exploration.
History Compression via Language Models in Reinforcement Learning
May 24, 2022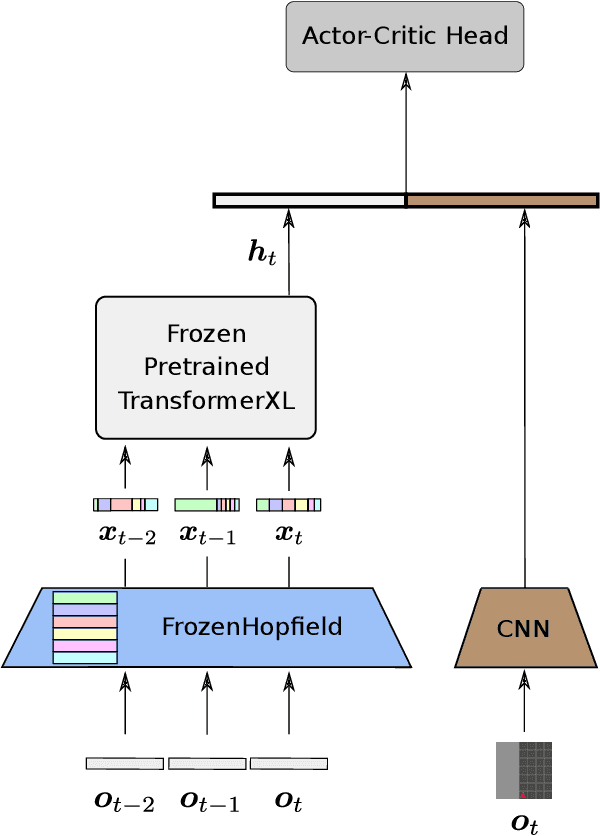

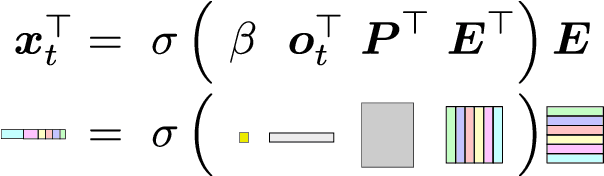

In a partially observable Markov decision process (POMDP), an agent typically uses a representation of the past to approximate the underlying MDP. We propose to utilize a frozen Pretrained Language Transformer (PLT) for history representation and compression to improve sample efficiency. To avoid training of the Transformer, we introduce FrozenHopfield, which automatically associates observations with original token embeddings. To form these associations, a modern Hopfield network stores the original token embeddings, which are retrieved by queries that are obtained by a random but fixed projection of observations. Our new method, HELM, enables actor-critic network architectures that contain a pretrained language Transformer for history representation as a memory module. Since a representation of the past need not be learned, HELM is much more sample efficient than competitors. On Minigrid and Procgen environments HELM achieves new state-of-the-art results. Our code is available at https://github.com/ml-jku/helm.
A Globally Convergent Evolutionary Strategy for Stochastic Constrained Optimization with Applications to Reinforcement Learning
Feb 21, 2022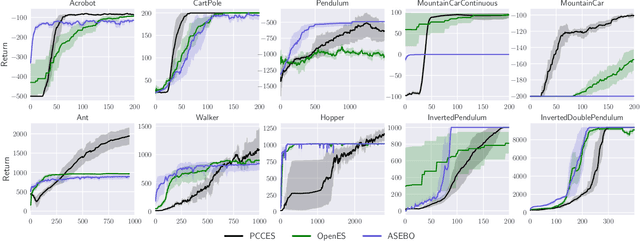
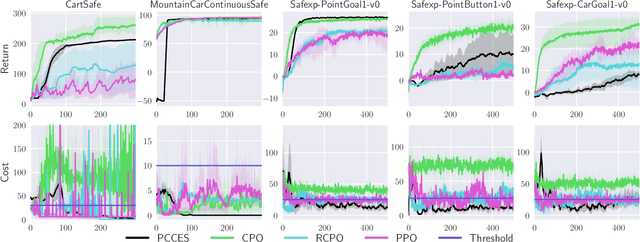
Evolutionary strategies have recently been shown to achieve competing levels of performance for complex optimization problems in reinforcement learning. In such problems, one often needs to optimize an objective function subject to a set of constraints, including for instance constraints on the entropy of a policy or to restrict the possible set of actions or states accessible to an agent. Convergence guarantees for evolutionary strategies to optimize stochastic constrained problems are however lacking in the literature. In this work, we address this problem by designing a novel optimization algorithm with a sufficient decrease mechanism that ensures convergence and that is based only on estimates of the functions. We demonstrate the applicability of this algorithm on two types of experiments: i) a control task for maximizing rewards and ii) maximizing rewards subject to a non-relaxable set of constraints.
Understanding the Effects of Dataset Characteristics on Offline Reinforcement Learning
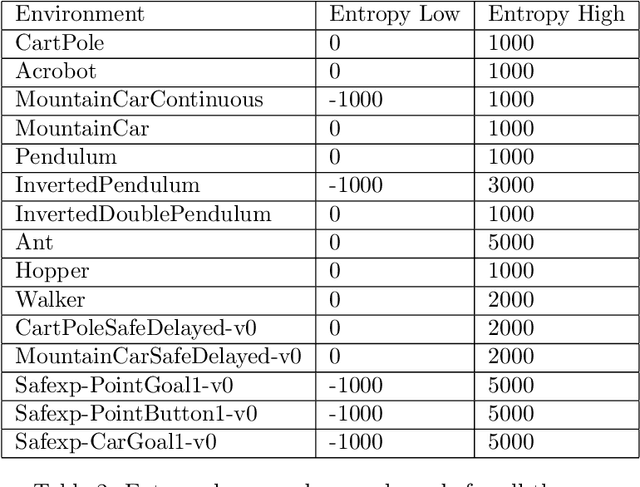
Nov 08, 2021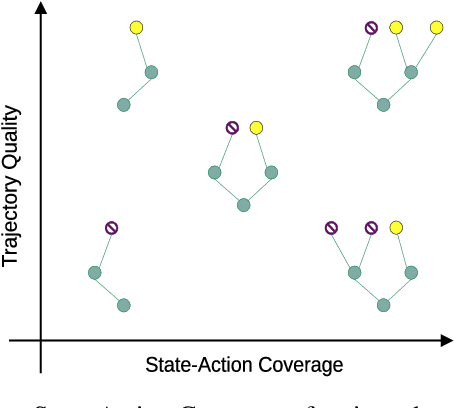
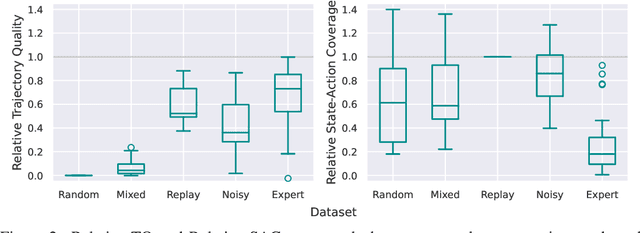
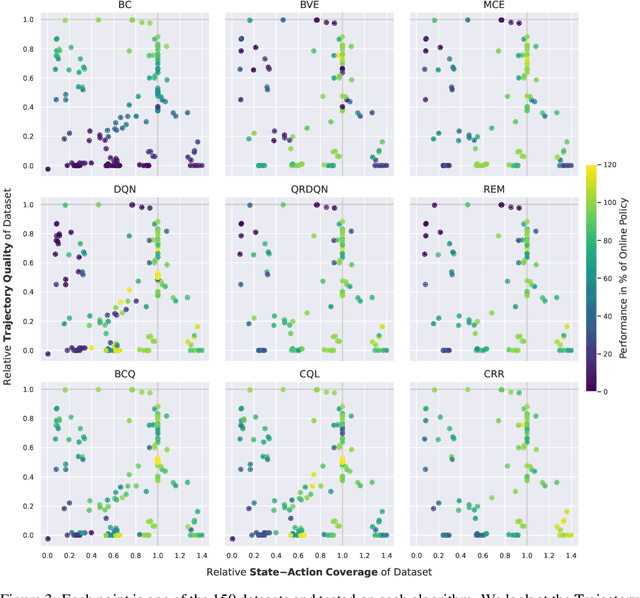

In real world, affecting the environment by a weak policy can be expensive or very risky, therefore hampers real world applications of reinforcement learning. Offline Reinforcement Learning (RL) can learn policies from a given dataset without interacting with the environment. However, the dataset is the only source of information for an Offline RL algorithm and determines the performance of the learned policy. We still lack studies on how dataset characteristics influence different Offline RL algorithms. Therefore, we conducted a comprehensive empirical analysis of how dataset characteristics effect the performance of Offline RL algorithms for discrete action environments. A dataset is characterized by two metrics: (1) the average dataset return measured by the Trajectory Quality (TQ) and (2) the coverage measured by the State-Action Coverage (SACo). We found that variants of the off-policy Deep Q-Network family require datasets with high SACo to perform well. Algorithms that constrain the learned policy towards the given dataset perform well for datasets with high TQ or SACo. For datasets with high TQ, Behavior Cloning outperforms or performs similarly to the best Offline RL algorithms.