 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeANTIC: Adaptive Neural Temporal In-situ Compressor
Apr 10, 2026The persistent storage requirements for high-resolution, spatiotemporally evolving fields governed by large-scale and high-dimensional partial differential equations (PDEs) have reached the petabyte-to-exabyte scale. Transient simulations modeling Navier-Stokes equations, magnetohydrodynamics, plasma physics, or binary black hole mergers generate data volumes that are prohibitive for modern high-performance computing (HPC) infrastructures. To address this bottleneck, we introduce ANTIC (Adaptive Neural Temporal in situ Compressor), an end-to-end in situ compression pipeline. ANTIC consists of an adaptive temporal selector tailored to high-dimensional physics that identifies and filters informative snapshots at simulation time, combined with a spatial neural compression module based on continual fine-tuning that learns residual updates between adjacent snapshots using neural fields. By operating in a single streaming pass, ANTIC enables a combined compression of temporal and spatial components and effectively alleviates the need for explicit on-disk storage of entire time-evolved trajectories. Experimental results demonstrate how storage reductions of several orders of magnitude relate to physics accuracy.
From Circuits to Dynamics: Understanding and Stabilizing Failure in 3D Diffusion Transformers
Feb 11, 2026Reliable surface completion from sparse point clouds underpins many applications spanning content creation and robotics. While 3D diffusion transformers attain state-of-the-art results on this task, we uncover that they exhibit a catastrophic mode of failure: arbitrarily small on-surface perturbations to the input point cloud can fracture the output into multiple disconnected pieces -- a phenomenon we call Meltdown. Using activation-patching from mechanistic interpretability, we localize Meltdown to a single early denoising cross-attention activation. We find that the singular-value spectrum of this activation provides a scalar proxy: its spectral entropy rises when fragmentation occurs and returns to baseline when patched. Interpreted through diffusion dynamics, we show that this proxy tracks a symmetry-breaking bifurcation of the reverse process. Guided by this insight, we introduce PowerRemap, a test-time control that stabilizes sparse point-cloud conditioning. We demonstrate that Meltdown persists across state-of-the-art architectures (WaLa, Make-a-Shape), datasets (GSO, SimJEB) and denoising strategies (DDPM, DDIM), and that PowerRemap effectively counters this failure with stabilization rates of up to 98.3%. Overall, this work is a case study on how diffusion model behavior can be understood and guided based on mechanistic analysis, linking a circuit-level cross-attention mechanism to diffusion-dynamics accounts of trajectory bifurcations.
GyroSwin: 5D Surrogates for Gyrokinetic Plasma Turbulence Simulations
Oct 08, 2025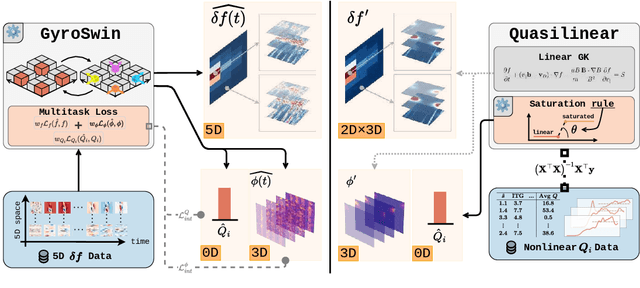

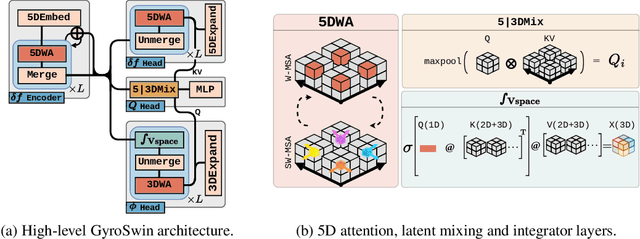
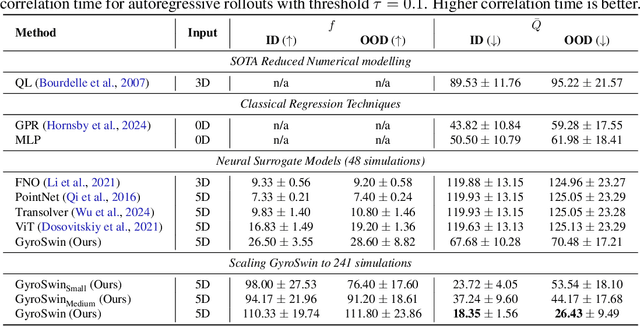
Nuclear fusion plays a pivotal role in the quest for reliable and sustainable energy production. A major roadblock to viable fusion power is understanding plasma turbulence, which significantly impairs plasma confinement, and is vital for next-generation reactor design. Plasma turbulence is governed by the nonlinear gyrokinetic equation, which evolves a 5D distribution function over time. Due to its high computational cost, reduced-order models are often employed in practice to approximate turbulent transport of energy. However, they omit nonlinear effects unique to the full 5D dynamics. To tackle this, we introduce GyroSwin, the first scalable 5D neural surrogate that can model 5D nonlinear gyrokinetic simulations, thereby capturing the physical phenomena neglected by reduced models, while providing accurate estimates of turbulent heat transport.GyroSwin (i) extends hierarchical Vision Transformers to 5D, (ii) introduces cross-attention and integration modules for latent 3D$\leftrightarrow$5D interactions between electrostatic potential fields and the distribution function, and (iii) performs channelwise mode separation inspired by nonlinear physics. We demonstrate that GyroSwin outperforms widely used reduced numerics on heat flux prediction, captures the turbulent energy cascade, and reduces the cost of fully resolved nonlinear gyrokinetics by three orders of magnitude while remaining physically verifiable. GyroSwin shows promising scaling laws, tested up to one billion parameters, paving the way for scalable neural surrogates for gyrokinetic simulations of plasma turbulence.
5D Neural Surrogates for Nonlinear Gyrokinetic Simulations of Plasma Turbulence
Feb 11, 2025Nuclear fusion plays a pivotal role in the quest for reliable and sustainable energy production. A major roadblock to achieving commercially viable fusion power is understanding plasma turbulence, which can significantly degrade plasma confinement. Modelling turbulence is crucial to design performing plasma scenarios for next-generation reactor-class devices and current experimental machines. The nonlinear gyrokinetic equation underpinning turbulence modelling evolves a 5D distribution function over time. Solving this equation numerically is extremely expensive, requiring up to weeks for a single run to converge, making it unfeasible for iterative optimisation and control studies. In this work, we propose a method for training neural surrogates for 5D gyrokinetic simulations. Our method extends a hierarchical vision transformer to five dimensions and is trained on the 5D distribution function for the adiabatic electron approximation. We demonstrate that our model can accurately infer downstream physical quantities such as heat flux time trace and electrostatic potentials for single-step predictions two orders of magnitude faster than numerical codes. Our work paves the way towards neural surrogates for plasma turbulence simulations to accelerate deployment of commercial energy production via nuclear fusion.
Preference Discerning with LLM-Enhanced Generative Retrieval
Dec 11, 2024



Sequential recommendation systems aim to provide personalized recommendations for users based on their interaction history. To achieve this, they often incorporate auxiliary information, such as textual descriptions of items and auxiliary tasks, like predicting user preferences and intent. Despite numerous efforts to enhance these models, they still suffer from limited personalization. To address this issue, we propose a new paradigm, which we term preference discerning. In preference dscerning, we explicitly condition a generative sequential recommendation system on user preferences within its context. To this end, we generate user preferences using Large Language Models (LLMs) based on user reviews and item-specific data. To evaluate preference discerning capabilities of sequential recommendation systems, we introduce a novel benchmark that provides a holistic evaluation across various scenarios, including preference steering and sentiment following. We assess current state-of-the-art methods using our benchmark and show that they struggle to accurately discern user preferences. Therefore, we propose a new method named Mender ($\textbf{M}$ultimodal Prefer$\textbf{en}$ce $\textbf{d}$iscern$\textbf{er}$), which improves upon existing methods and achieves state-of-the-art performance on our benchmark. Our results show that Mender can be effectively guided by human preferences even though they have not been observed during training, paving the way toward more personalized sequential recommendation systems. We will open-source the code and benchmarks upon publication.
Unifying Generative and Dense Retrieval for Sequential Recommendation
Nov 27, 2024

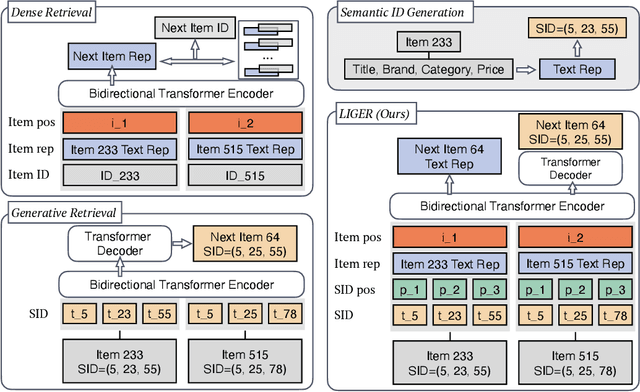
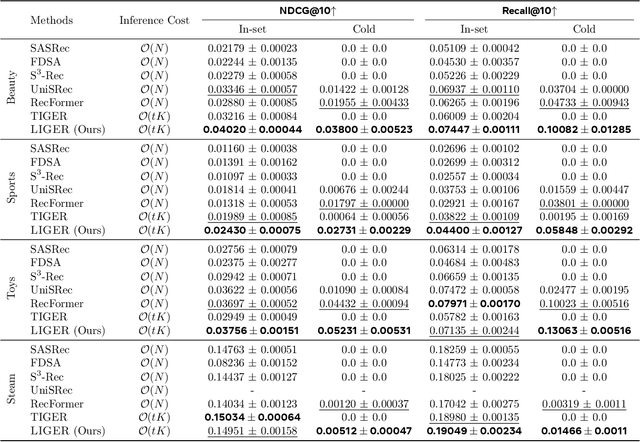
Sequential dense retrieval models utilize advanced sequence learning techniques to compute item and user representations, which are then used to rank relevant items for a user through inner product computation between the user and all item representations. However, this approach requires storing a unique representation for each item, resulting in significant memory requirements as the number of items grow. In contrast, the recently proposed generative retrieval paradigm offers a promising alternative by directly predicting item indices using a generative model trained on semantic IDs that encapsulate items' semantic information. Despite its potential for large-scale applications, a comprehensive comparison between generative retrieval and sequential dense retrieval under fair conditions is still lacking, leaving open questions regarding performance, and computation trade-offs. To address this, we compare these two approaches under controlled conditions on academic benchmarks and propose LIGER (LeveragIng dense retrieval for GEnerative Retrieval), a hybrid model that combines the strengths of these two widely used methods. LIGER integrates sequential dense retrieval into generative retrieval, mitigating performance differences and enhancing cold-start item recommendation in the datasets evaluated. This hybrid approach provides insights into the trade-offs between these approaches and demonstrates improvements in efficiency and effectiveness for recommendation systems in small-scale benchmarks.
Retrieval-Augmented Decision Transformer: External Memory for In-context RL
Oct 09, 2024



In-context learning (ICL) is the ability of a model to learn a new task by observing a few exemplars in its context. While prevalent in NLP, this capability has recently also been observed in Reinforcement Learning (RL) settings. Prior in-context RL methods, however, require entire episodes in the agent's context. Given that complex environments typically lead to long episodes with sparse rewards, these methods are constrained to simple environments with short episodes. To address these challenges, we introduce Retrieval-Augmented Decision Transformer (RA-DT). RA-DT employs an external memory mechanism to store past experiences from which it retrieves only sub-trajectories relevant for the current situation. The retrieval component in RA-DT does not require training and can be entirely domain-agnostic. We evaluate the capabilities of RA-DT on grid-world environments, robotics simulations, and procedurally-generated video games. On grid-worlds, RA-DT outperforms baselines, while using only a fraction of their context length. Furthermore, we illuminate the limitations of current in-context RL methods on complex environments and discuss future directions. To facilitate future research, we release datasets for four of the considered environments.
One Initialization to Rule them All: Fine-tuning via Explained Variance Adaptation
Oct 09, 2024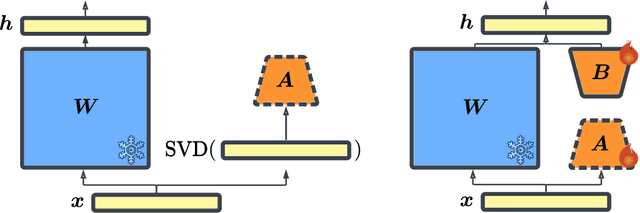
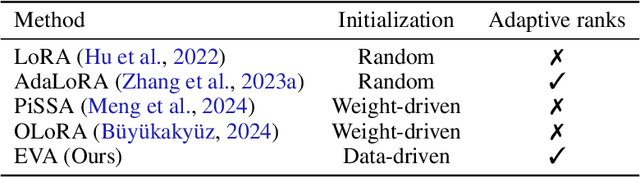
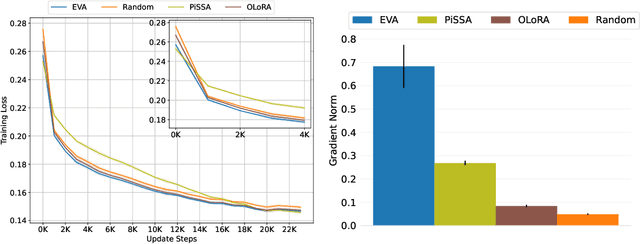
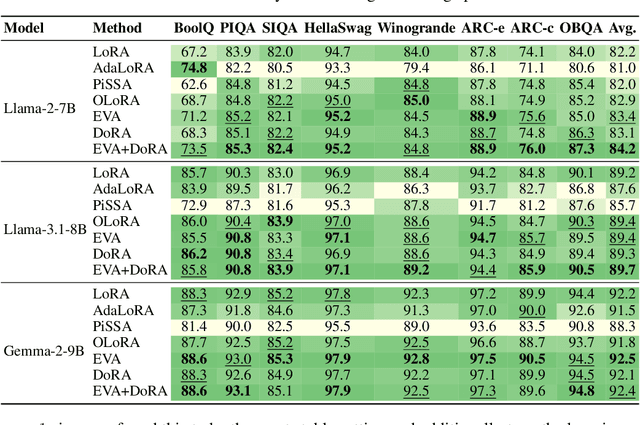
Foundation models (FMs) are pre-trained on large-scale datasets and then fine-tuned on a downstream task for a specific application. The most successful and most commonly used fine-tuning method is to update the pre-trained weights via a low-rank adaptation (LoRA). LoRA introduces new weight matrices that are usually initialized at random with a uniform rank distribution across model weights. Recent works focus on weight-driven initialization or learning of adaptive ranks during training. Both approaches have only been investigated in isolation, resulting in slow convergence or a uniform rank distribution, in turn leading to sub-optimal performance. We propose to enhance LoRA by initializing the new weights in a data-driven manner by computing singular value decomposition on minibatches of activation vectors. Then, we initialize the LoRA matrices with the obtained right-singular vectors and re-distribute ranks among all weight matrices to explain the maximal amount of variance and continue the standard LoRA fine-tuning procedure. This results in our new method Explained Variance Adaptation (EVA). We apply EVA to a variety of fine-tuning tasks ranging from language generation and understanding to image classification and reinforcement learning. EVA exhibits faster convergence than competitors and attains the highest average score across a multitude of tasks per domain.
SITTA: A Semantic Image-Text Alignment for Image Captioning
Jul 10, 2023Textual and semantic comprehension of images is essential for generating proper captions. The comprehension requires detection of objects, modeling of relations between them, an assessment of the semantics of the scene and, finally, representing the extracted knowledge in a language space. To achieve rich language capabilities while ensuring good image-language mappings, pretrained language models (LMs) were conditioned on pretrained multi-modal (image-text) models that allow for image inputs. This requires an alignment of the image representation of the multi-modal model with the language representations of a generative LM. However, it is not clear how to best transfer semantics detected by the vision encoder of the multi-modal model to the LM. We introduce two novel ways of constructing a linear mapping that successfully transfers semantics between the embedding spaces of the two pretrained models. The first aligns the embedding space of the multi-modal language encoder with the embedding space of the pretrained LM via token correspondences. The latter leverages additional data that consists of image-text pairs to construct the mapping directly from vision to language space. Using our semantic mappings, we unlock image captioning for LMs without access to gradient information. By using different sources of data we achieve strong captioning performance on MS-COCO and Flickr30k datasets. Even in the face of limited data, our method partly exceeds the performance of other zero-shot and even finetuned competitors. Our ablation studies show that even LMs at a scale of merely 250M parameters can generate decent captions employing our semantic mappings. Our approach makes image captioning more accessible for institutions with restricted computational resources.
Learning to Modulate pre-trained Models in RL
Jun 26, 2023Reinforcement Learning (RL) has been successful in various domains like robotics, game playing, and simulation. While RL agents have shown impressive capabilities in their specific tasks, they insufficiently adapt to new tasks. In supervised learning, this adaptation problem is addressed by large-scale pre-training followed by fine-tuning to new down-stream tasks. Recently, pre-training on multiple tasks has been gaining traction in RL. However, fine-tuning a pre-trained model often suffers from catastrophic forgetting, that is, the performance on the pre-training tasks deteriorates when fine-tuning on new tasks. To investigate the catastrophic forgetting phenomenon, we first jointly pre-train a model on datasets from two benchmark suites, namely Meta-World and DMControl. Then, we evaluate and compare a variety of fine-tuning methods prevalent in natural language processing, both in terms of performance on new tasks, and how well performance on pre-training tasks is retained. Our study shows that with most fine-tuning approaches, the performance on pre-training tasks deteriorates significantly. Therefore, we propose a novel method, Learning-to-Modulate (L2M), that avoids the degradation of learned skills by modulating the information flow of the frozen pre-trained model via a learnable modulation pool. Our method achieves state-of-the-art performance on the Continual-World benchmark, while retaining performance on the pre-training tasks. Finally, to aid future research in this area, we release a dataset encompassing 50 Meta-World and 16 DMControl tasks.