 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterFlywheel: Scaling Iterative Improvement of Engaging and Steerable LLMs in Production
Mar 02, 2026This report presents CharacterFlywheel, an iterative flywheel process for improving large language models (LLMs) in production social chat applications across Instagram, WhatsApp, and Messenger. Starting from LLaMA 3.1, we refined models across 15 generations using data from both internal and external real-user traffic. Through continuous deployments from July 2024 to April 2025, we conducted controlled 7-day A/B tests showing consistent engagement improvements: 7 of 8 newly deployed models demonstrated positive lift over the baseline, with the strongest performers achieving up to 8.8% improvement in engagement breadth and 19.4% in engagement depth. We also observed substantial gains in steerability, with instruction following increasing from 59.2% to 84.8% and instruction violations decreasing from 26.6% to 5.8%. We detail the CharacterFlywheel process which integrates data curation, reward modeling to estimate and interpolate the landscape of engagement metrics, supervised fine-tuning (SFT), reinforcement learning (RL), and both offline and online evaluation to ensure reliable progress at each optimization step. We also discuss our methods for overfitting prevention and navigating production dynamics at scale. These contributions advance the scientific rigor and understanding of LLMs in social applications serving millions of users.
Preference Discerning with LLM-Enhanced Generative Retrieval
Dec 11, 2024



Sequential recommendation systems aim to provide personalized recommendations for users based on their interaction history. To achieve this, they often incorporate auxiliary information, such as textual descriptions of items and auxiliary tasks, like predicting user preferences and intent. Despite numerous efforts to enhance these models, they still suffer from limited personalization. To address this issue, we propose a new paradigm, which we term preference discerning. In preference dscerning, we explicitly condition a generative sequential recommendation system on user preferences within its context. To this end, we generate user preferences using Large Language Models (LLMs) based on user reviews and item-specific data. To evaluate preference discerning capabilities of sequential recommendation systems, we introduce a novel benchmark that provides a holistic evaluation across various scenarios, including preference steering and sentiment following. We assess current state-of-the-art methods using our benchmark and show that they struggle to accurately discern user preferences. Therefore, we propose a new method named Mender ($\textbf{M}$ultimodal Prefer$\textbf{en}$ce $\textbf{d}$iscern$\textbf{er}$), which improves upon existing methods and achieves state-of-the-art performance on our benchmark. Our results show that Mender can be effectively guided by human preferences even though they have not been observed during training, paving the way toward more personalized sequential recommendation systems. We will open-source the code and benchmarks upon publication.
APOLLO: SGD-like Memory, AdamW-level Performance
Dec 09, 2024



Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing batch sizes, limiting training scalability and throughput. To address this, various memory-efficient optimizers have been proposed to reduce optimizer memory usage. However, they face critical challenges: (i) reliance on costly SVD operations; (ii) significant performance trade-offs compared to AdamW; and (iii) still substantial optimizer memory overhead to maintain competitive performance. In this work, we identify that AdamW's learning rate adaptation rule can be effectively coarsened as a structured learning rate update. Based on this insight, we propose Approximated Gradient Scaling for Memory-Efficient LLM Optimization (APOLLO), which approximates learning rate scaling using an auxiliary low-rank optimizer state based on pure random projection. This structured learning rate update rule makes APOLLO highly tolerant to further memory reductions while delivering comparable pre-training performance. Even its rank-1 variant, APOLLO-Mini, achieves superior pre-training performance compared to AdamW with SGD-level memory costs. Extensive experiments demonstrate that the APOLLO series performs on-par with or better than AdamW, while achieving greater memory savings by nearly eliminating the optimization states of AdamW. These savings provide significant system-level benefits: (1) Enhanced Throughput: 3x throughput on an 8xA100-80GB setup compared to AdamW by supporting 4x larger batch sizes. (2) Improved Model Scalability: Pre-training LLaMA-13B with naive DDP on A100-80GB GPUs without system-level optimizations. (3) Low-End GPU Friendly Pre-training: Pre-training LLaMA-7B on a single GPU using less than 12 GB of memory with weight quantization.
Unifying Generative and Dense Retrieval for Sequential Recommendation
Nov 27, 2024

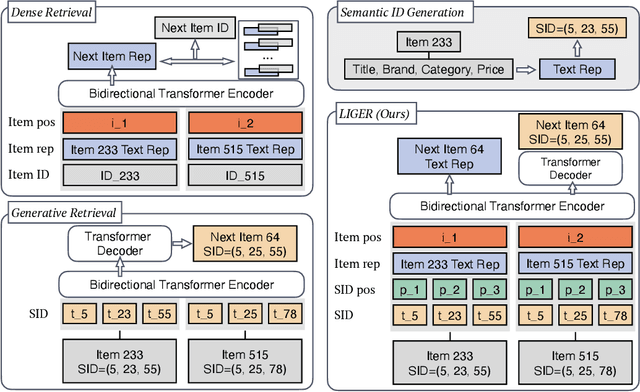
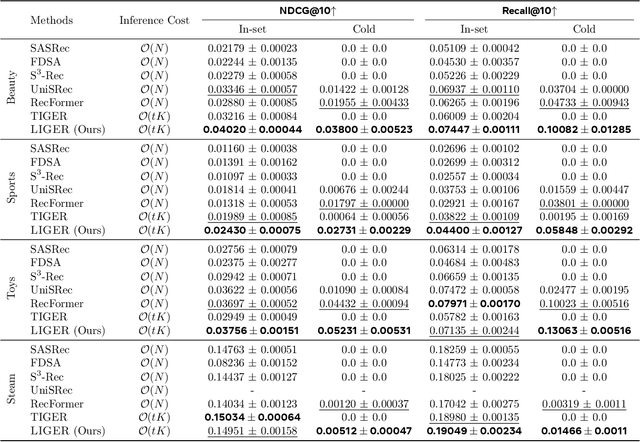
Sequential dense retrieval models utilize advanced sequence learning techniques to compute item and user representations, which are then used to rank relevant items for a user through inner product computation between the user and all item representations. However, this approach requires storing a unique representation for each item, resulting in significant memory requirements as the number of items grow. In contrast, the recently proposed generative retrieval paradigm offers a promising alternative by directly predicting item indices using a generative model trained on semantic IDs that encapsulate items' semantic information. Despite its potential for large-scale applications, a comprehensive comparison between generative retrieval and sequential dense retrieval under fair conditions is still lacking, leaving open questions regarding performance, and computation trade-offs. To address this, we compare these two approaches under controlled conditions on academic benchmarks and propose LIGER (LeveragIng dense retrieval for GEnerative Retrieval), a hybrid model that combines the strengths of these two widely used methods. LIGER integrates sequential dense retrieval into generative retrieval, mitigating performance differences and enhancing cold-start item recommendation in the datasets evaluated. This hybrid approach provides insights into the trade-offs between these approaches and demonstrates improvements in efficiency and effectiveness for recommendation systems in small-scale benchmarks.
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
May 19, 2024Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.
SPAR: Personalized Content-Based Recommendation via Long Engagement Attention
Feb 16, 2024



Leveraging users' long engagement histories is essential for personalized content recommendations. The success of pretrained language models (PLMs) in NLP has led to their use in encoding user histories and candidate items, framing content recommendations as textual semantic matching tasks. However, existing works still struggle with processing very long user historical text and insufficient user-item interaction. In this paper, we introduce a content-based recommendation framework, SPAR, which effectively tackles the challenges of holistic user interest extraction from the long user engagement history. It achieves so by leveraging PLM, poly-attention layers and attention sparsity mechanisms to encode user's history in a session-based manner. The user and item side features are sufficiently fused for engagement prediction while maintaining standalone representations for both sides, which is efficient for practical model deployment. Moreover, we enhance user profiling by exploiting large language model (LLM) to extract global interests from user engagement history. Extensive experiments on two benchmark datasets demonstrate that our framework outperforms existing state-of-the-art (SoTA) methods.