 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDOMR: Establishing Cross-View Segmentation via Dense Object Matching
Aug 06, 2025Cross-view object correspondence involves matching objects between egocentric (first-person) and exocentric (third-person) views. It is a critical yet challenging task for visual understanding. In this work, we propose the Dense Object Matching and Refinement (DOMR) framework to establish dense object correspondences across views. The framework centers around the Dense Object Matcher (DOM) module, which jointly models multiple objects. Unlike methods that directly match individual object masks to image features, DOM leverages both positional and semantic relationships among objects to find correspondences. DOM integrates a proposal generation module with a dense matching module that jointly encodes visual, spatial, and semantic cues, explicitly constructing inter-object relationships to achieve dense matching among objects. Furthermore, we combine DOM with a mask refinement head designed to improve the completeness and accuracy of the predicted masks, forming the complete DOMR framework. Extensive evaluations on the Ego-Exo4D benchmark demonstrate that our approach achieves state-of-the-art performance with a mean IoU of 49.7% on Ego$\to$Exo and 55.2% on Exo$\to$Ego. These results outperform those of previous methods by 5.8% and 4.3%, respectively, validating the effectiveness of our integrated approach for cross-view understanding.
Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID
Apr 02, 2025The exponential growth of online content has posed significant challenges to ID-based models in industrial recommendation systems, ranging from extremely high cardinality and dynamically growing ID space, to highly skewed engagement distributions, to prediction instability as a result of natural id life cycles (e.g, the birth of new IDs and retirement of old IDs). To address these issues, many systems rely on random hashing to handle the id space and control the corresponding model parameters (i.e embedding table). However, this approach introduces data pollution from multiple ids sharing the same embedding, leading to degraded model performance and embedding representation instability. This paper examines these challenges and introduces Semantic ID prefix ngram, a novel token parameterization technique that significantly improves the performance of the original Semantic ID. Semantic ID prefix ngram creates semantically meaningful collisions by hierarchically clustering items based on their content embeddings, as opposed to random assignments. Through extensive experimentation, we demonstrate that Semantic ID prefix ngram not only addresses embedding instability but also significantly improves tail id modeling, reduces overfitting, and mitigates representation shifts. We further highlight the advantages of Semantic ID prefix ngram in attention-based models that contextualize user histories, showing substantial performance improvements. We also report our experience of integrating Semantic ID into Meta production Ads Ranking system, leading to notable performance gains and enhanced prediction stability in live deployments.
M$^3$amba: CLIP-driven Mamba Model for Multi-modal Remote Sensing Classification
Mar 09, 2025Multi-modal fusion holds great promise for integrating information from different modalities. However, due to a lack of consideration for modal consistency, existing multi-modal fusion methods in the field of remote sensing still face challenges of incomplete semantic information and low computational efficiency in their fusion designs. Inspired by the observation that the visual language pre-training model CLIP can effectively extract strong semantic information from visual features, we propose M$^3$amba, a novel end-to-end CLIP-driven Mamba model for multi-modal fusion to address these challenges. Specifically, we introduce CLIP-driven modality-specific adapters in the fusion architecture to avoid the bias of understanding specific domains caused by direct inference, making the original CLIP encoder modality-specific perception. This unified framework enables minimal training to achieve a comprehensive semantic understanding of different modalities, thereby guiding cross-modal feature fusion. To further enhance the consistent association between modality mappings, a multi-modal Mamba fusion architecture with linear complexity and a cross-attention module Cross-SS2D are designed, which fully considers effective and efficient information interaction to achieve complete fusion. Extensive experiments have shown that M$^3$amba has an average performance improvement of at least 5.98\% compared with the state-of-the-art methods in multi-modal hyperspectral image classification tasks in the remote sensing field, while also demonstrating excellent training efficiency, achieving a double improvement in accuracy and efficiency. The code is released at https://github.com/kaka-Cao/M3amba.
Data-Efficient Pretraining with Group-Level Data Influence Modeling
Feb 20, 2025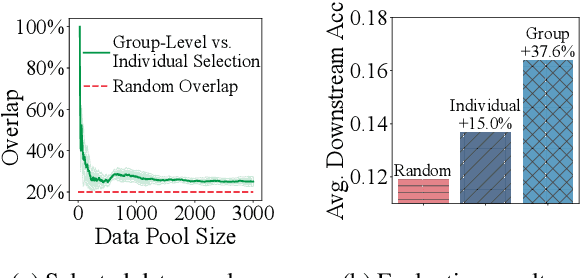
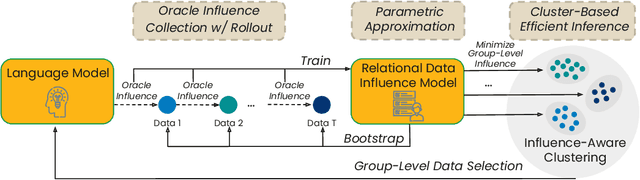
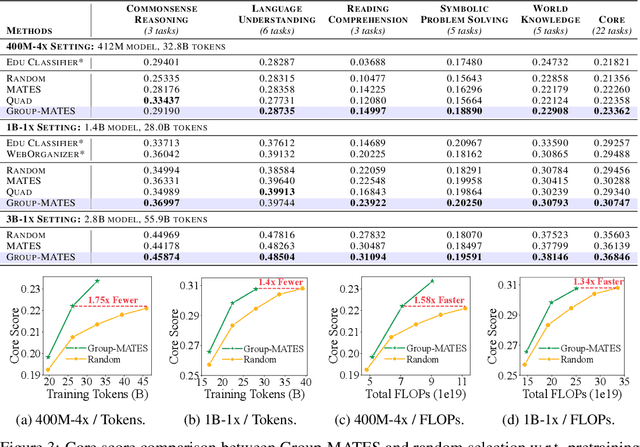
Data-efficient pretraining has shown tremendous potential to elevate scaling laws. This paper argues that effective pretraining data should be curated at the group level, treating a set of data points as a whole rather than as independent contributors. To achieve that, we propose Group-Level Data Influence Modeling (Group-MATES), a novel data-efficient pretraining method that captures and optimizes group-level data utility. Specifically, Group-MATES collects oracle group-level influences by locally probing the pretraining model with data sets. It then fine-tunes a relational data influence model to approximate oracles as relationship-weighted aggregations of individual influences. The fine-tuned model selects the data subset by maximizing its group-level influence prediction, with influence-aware clustering to enable efficient inference. Experiments on the DCLM benchmark demonstrate that Group-MATES achieves a 10% relative core score improvement on 22 downstream tasks over DCLM-Baseline and 5% over individual-influence-based methods, establishing a new state-of-the-art. Further analyses highlight the effectiveness of relational data influence models in capturing intricate interactions between data points.
Towards Efficient Model-Heterogeneity Federated Learning for Large Models
Nov 25, 2024As demand grows for complex tasks and high-performance applications in edge computing, the deployment of large models in federated learning has become increasingly urgent, given their superior representational power and generalization capabilities. However, the resource constraints and heterogeneity among clients present significant challenges to this deployment. To tackle these challenges, we introduce HeteroTune, an innovative fine-tuning framework tailored for model-heterogeneity federated learning (MHFL). In particular, we propose a novel parameter-efficient fine-tuning (PEFT) structure, called FedAdapter, which employs a multi-branch cross-model aggregator to enable efficient knowledge aggregation across diverse models. Benefiting from the lightweight FedAdapter, our approach significantly reduces both the computational and communication overhead. Finally, our approach is simple yet effective, making it applicable to a wide range of large model fine-tuning tasks. Extensive experiments on computer vision (CV) and natural language processing (NLP) tasks demonstrate that our method achieves state-of-the-art results, seamlessly integrating efficiency and performance.
Towards Accurate and Efficient Sub-8-Bit Integer Training
Nov 17, 2024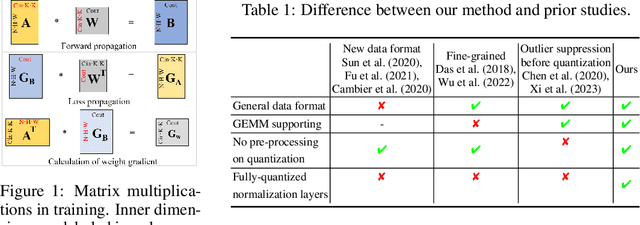
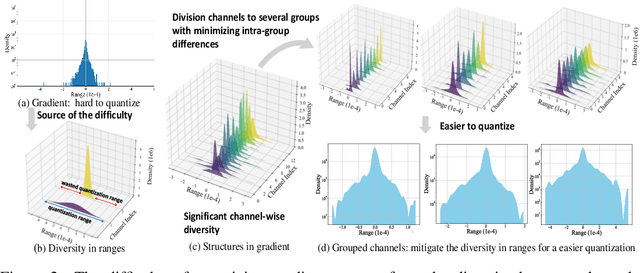
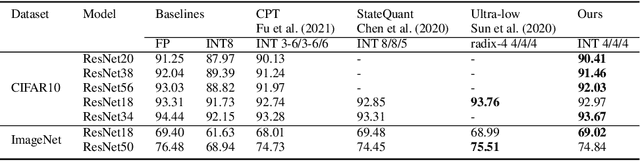
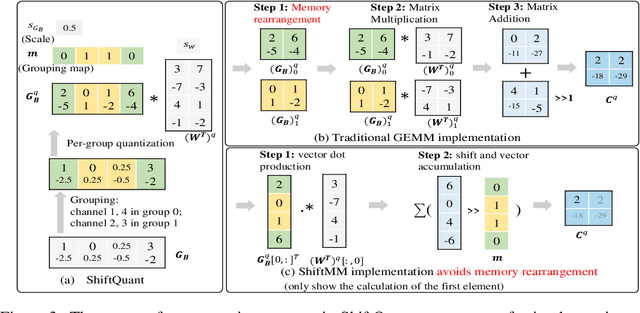
Neural network training is a memory- and compute-intensive task. Quantization, which enables low-bitwidth formats in training, can significantly mitigate the workload. To reduce quantization error, recent methods have developed new data formats and additional pre-processing operations on quantizers. However, it remains quite challenging to achieve high accuracy and efficiency simultaneously. In this paper, we explore sub-8-bit integer training from its essence of gradient descent optimization. Our integer training framework includes two components: ShiftQuant to realize accurate gradient estimation, and L1 normalization to smoothen the loss landscape. ShiftQuant attains performance that approaches the theoretical upper bound of group quantization. Furthermore, it liberates group quantization from inefficient memory rearrangement. The L1 normalization facilitates the implementation of fully quantized normalization layers with impressive convergence accuracy. Our method frees sub-8-bit integer training from pre-processing and supports general devices. This framework achieves negligible accuracy loss across various neural networks and tasks ($0.92\%$ on 4-bit ResNets, $0.61\%$ on 6-bit Transformers). The prototypical implementation of ShiftQuant achieves more than $1.85\times/15.3\%$ performance improvement on CPU/GPU compared to its FP16 counterparts, and $33.9\%$ resource consumption reduction on FPGA than the FP16 counterparts. The proposed fully-quantized L1 normalization layers achieve more than $35.54\%$ improvement in throughout on CPU compared to traditional L2 normalization layers. Moreover, theoretical analysis verifies the advancement of our method.
SeaDATE: Remedy Dual-Attention Transformer with Semantic Alignment via Contrast Learning for Multimodal Object Detection
Oct 15, 2024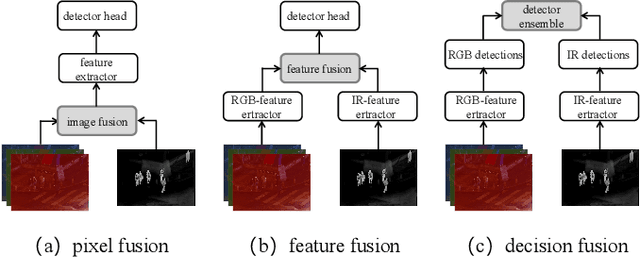
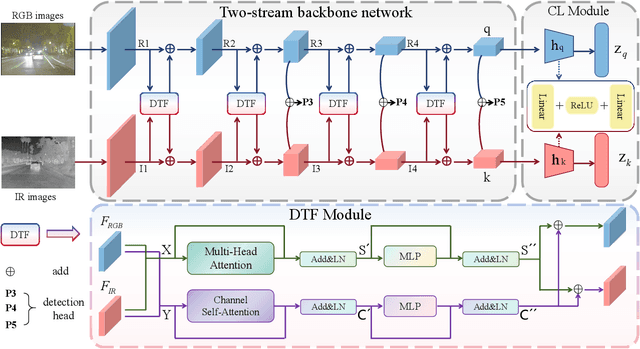
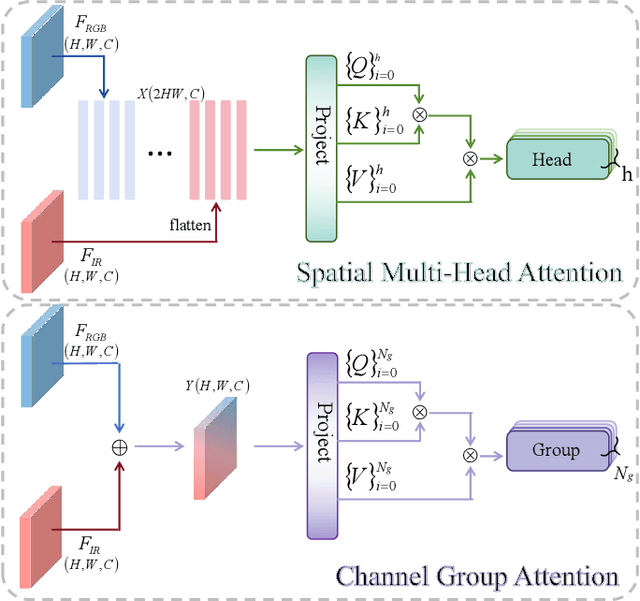
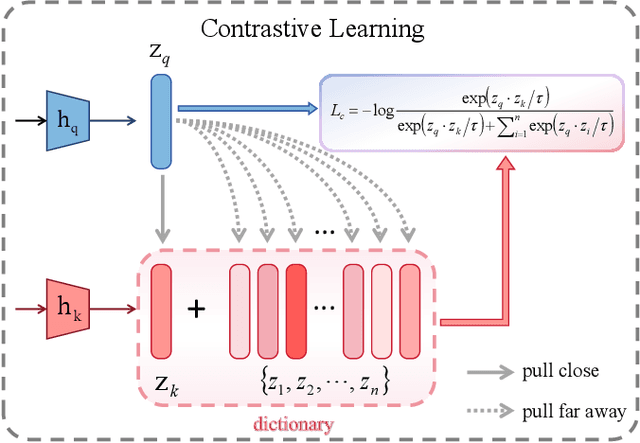
Multimodal object detection leverages diverse modal information to enhance the accuracy and robustness of detectors. By learning long-term dependencies, Transformer can effectively integrate multimodal features in the feature extraction stage, which greatly improves the performance of multimodal object detection. However, current methods merely stack Transformer-guided fusion techniques without exploring their capability to extract features at various depth layers of network, thus limiting the improvements in detection performance. In this paper, we introduce an accurate and efficient object detection method named SeaDATE. Initially, we propose a novel dual attention Feature Fusion (DTF) module that, under Transformer's guidance, integrates local and global information through a dual attention mechanism, strengthening the fusion of modal features from orthogonal perspectives using spatial and channel tokens. Meanwhile, our theoretical analysis and empirical validation demonstrate that the Transformer-guided fusion method, treating images as sequences of pixels for fusion, performs better on shallow features' detail information compared to deep semantic information. To address this, we designed a contrastive learning (CL) module aimed at learning features of multimodal samples, remedying the shortcomings of Transformer-guided fusion in extracting deep semantic features, and effectively utilizing cross-modal information. Extensive experiments and ablation studies on the FLIR, LLVIP, and M3FD datasets have proven our method to be effective, achieving state-of-the-art detection performance.
FoRA: Low-Rank Adaptation Model beyond Multimodal Siamese Network
Jul 23, 2024Multimodal object detection offers a promising prospect to facilitate robust detection in various visual conditions. However, existing two-stream backbone networks are challenged by complex fusion and substantial parameter increments. This is primarily due to large data distribution biases of multimodal homogeneous information. In this paper, we propose a novel multimodal object detector, named Low-rank Modal Adaptors (LMA) with a shared backbone. The shared parameters enhance the consistency of homogeneous information, while lightweight modal adaptors focus on modality unique features. Furthermore, we design an adaptive rank allocation strategy to adapt to the varying heterogeneity at different feature levels. When applied to two multimodal object detection datasets, experiments validate the effectiveness of our method. Notably, on DroneVehicle, LMA attains a 10.4% accuracy improvement over the state-of-the-art method with a 149M-parameters reduction. The code is available at https://github.com/zyszxhy/FoRA. Our work was submitted to ACM MM in April 2024, but was rejected. We will continue to refine our work and paper writing next, mainly including proof of theory and multi-task applications of FoRA.
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
May 19, 2024Content-based recommendation systems play a crucial role in delivering personalized content to users in the digital world. In this work, we introduce EmbSum, a novel framework that enables offline pre-computations of users and candidate items while capturing the interactions within the user engagement history. By utilizing the pretrained encoder-decoder model and poly-attention layers, EmbSum derives User Poly-Embedding (UPE) and Content Poly-Embedding (CPE) to calculate relevance scores between users and candidate items. EmbSum actively learns the long user engagement histories by generating user-interest summary with supervision from large language model (LLM). The effectiveness of EmbSum is validated on two datasets from different domains, surpassing state-of-the-art (SoTA) methods with higher accuracy and fewer parameters. Additionally, the model's ability to generate summaries of user interests serves as a valuable by-product, enhancing its usefulness for personalized content recommendations.
EfficientMFD: Towards More Efficient Multimodal Synchronous Fusion Detection
Mar 14, 2024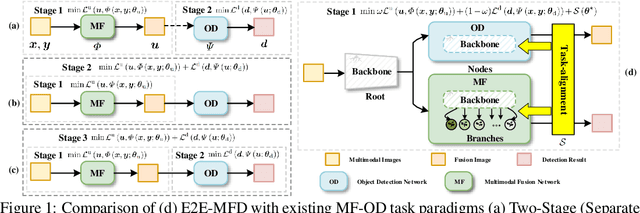
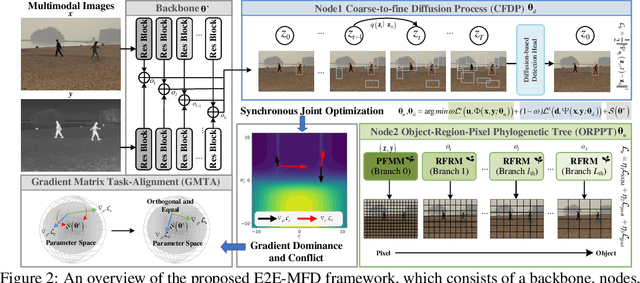
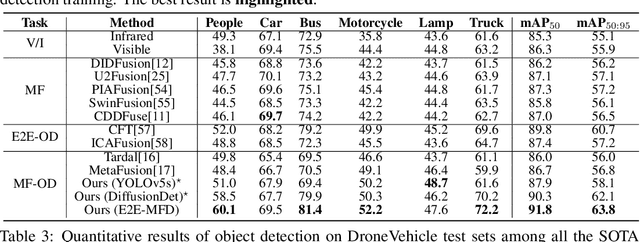

Multimodal image fusion and object detection play a vital role in autonomous driving. Current joint learning methods have made significant progress in the multimodal fusion detection task combining the texture detail and objective semantic information. However, the tedious training steps have limited its applications to wider real-world industrial deployment. To address this limitation, we propose a novel end-to-end multimodal fusion detection algorithm, named EfficientMFD, to simplify models that exhibit decent performance with only one training step. Synchronous joint optimization is utilized in an end-to-end manner between two components, thus not being affected by the local optimal solution of the individual task. Besides, a comprehensive optimization is established in the gradient matrix between the shared parameters for both tasks. It can converge to an optimal point with fusion detection weights. We extensively test it on several public datasets, demonstrating superior performance on not only visually appealing fusion but also favorable detection performance (e.g., 6.6% mAP50:95) over other state-of-the-art approaches.