 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSR-Nav: Spatial Relationships Matter for Zero-shot Object Goal Navigation
Mar 19, 2026Zero-shot object-goal navigation aims to find target objects in unseen environments using only egocentric observation. Recent methods leverage foundation models' comprehension and reasoning capabilities to enhance navigation performance. However, when faced with poor viewpoints or weak semantic cues, foundation models often fail to support reliable reasoning in both perception and planning, resulting in inefficient or failed navigation. We observe that inherent relationships among objects and regions encode structured scene priors, which help agents infer plausible target locations even under partial observations. Motivated by this insight, we propose Spatial Relation-aware Navigation (SR-Nav), a framework that models both observed and experience-based spatial relationships to enhance both perception and planning. Specifically, SR-Nav first constructs a Dynamic Spatial Relationship Graph (DSRG) that encodes the target-centered spatial relationships through the foundation models and updates dynamically with real-time observations. We then introduce a Relation-aware Matching Module. It utilizes relationship matching instead of naive detection, leveraging diverse relationships in the DSRG to verify and correct errors, enhancing visual perception robustness. Finally, we design a Dynamic Relationship Planning Module to reduce the planning search space by dynamically computing the optimal paths based on the DSRG from the current position, thereby guiding planning and reducing exploration redundancy. Experiments on HM3D show that our method achieves state-of-the-art performance in both success rate and navigation efficiency. The code will be publicly available at https://github.com/Mzyw-1314/SR-Nav
Survey of Multimodal Geospatial Foundation Models: Techniques, Applications, and Challenges
Oct 27, 2025Foundation models have transformed natural language processing and computer vision, and their impact is now reshaping remote sensing image analysis. With powerful generalization and transfer learning capabilities, they align naturally with the multimodal, multi-resolution, and multi-temporal characteristics of remote sensing data. To address unique challenges in the field, multimodal geospatial foundation models (GFMs) have emerged as a dedicated research frontier. This survey delivers a comprehensive review of multimodal GFMs from a modality-driven perspective, covering five core visual and vision-language modalities. We examine how differences in imaging physics and data representation shape interaction design, and we analyze key techniques for alignment, integration, and knowledge transfer to tackle modality heterogeneity, distribution shifts, and semantic gaps. Advances in training paradigms, architectures, and task-specific adaptation strategies are systematically assessed alongside a wealth of emerging benchmarks. Representative multimodal visual and vision-language GFMs are evaluated across ten downstream tasks, with insights into their architectures, performance, and application scenarios. Real-world case studies, spanning land cover mapping, agricultural monitoring, disaster response, climate studies, and geospatial intelligence, demonstrate the practical potential of GFMs. Finally, we outline pressing challenges in domain generalization, interpretability, efficiency, and privacy, and chart promising avenues for future research.
High-Energy Concentration for Federated Learning in Frequency Domain
Sep 16, 2025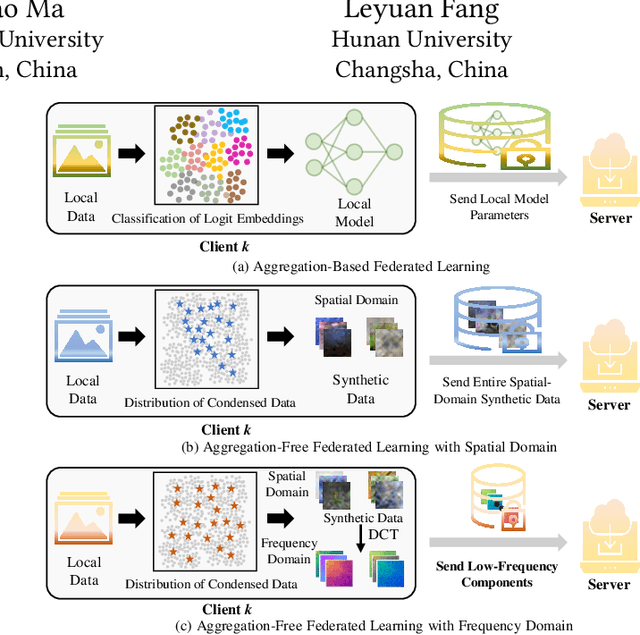
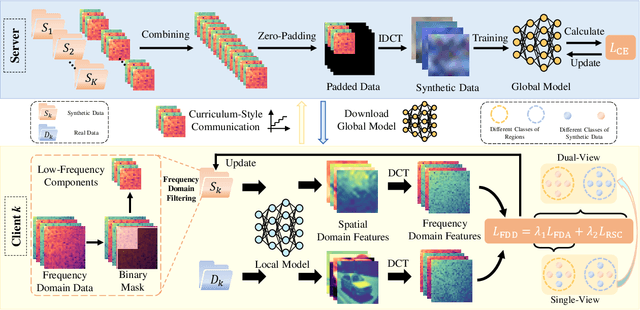
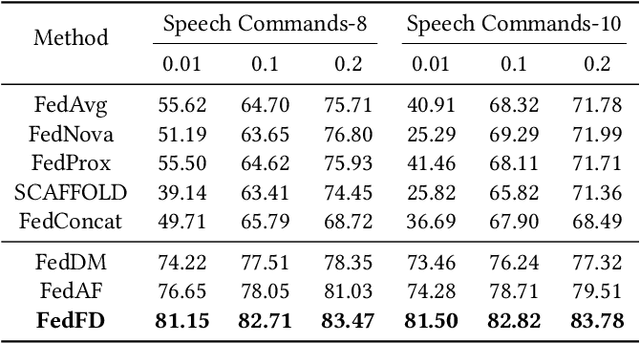
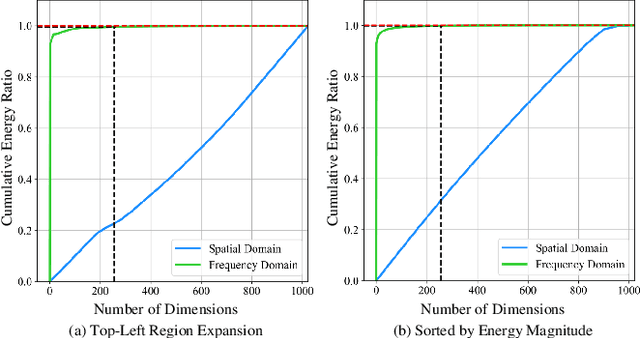
Federated Learning (FL) presents significant potential for collaborative optimization without data sharing. Since synthetic data is sent to the server, leveraging the popular concept of dataset distillation, this FL framework protects real data privacy while alleviating data heterogeneity. However, such methods are still challenged by the redundant information and noise in entire spatial-domain designs, which inevitably increases the communication burden. In this paper, we propose a novel Frequency-Domain aware FL method with high-energy concentration (FedFD) to address this problem. Our FedFD is inspired by the discovery that the discrete cosine transform predominantly distributes energy to specific regions, referred to as high-energy concentration. The principle behind FedFD is that low-energy like high-frequency components usually contain redundant information and noise, thus filtering them helps reduce communication costs and optimize performance. Our FedFD is mathematically formulated to preserve the low-frequency components using a binary mask, facilitating an optimal solution through frequency-domain distribution alignment. In particular, real data-driven synthetic classification is imposed into the loss to enhance the quality of the low-frequency components. On five image and speech datasets, FedFD achieves superior performance than state-of-the-art methods while reducing communication costs. For example, on the CIFAR-10 dataset with Dirichlet coefficient $\alpha = 0.01$, FedFD achieves a minimum reduction of 37.78\% in the communication cost, while attaining a 10.88\% performance gain.
Beyond Distribution Shifts: Adaptive Hyperspectral Image Classification at Test Time
Sep 10, 2025Hyperspectral image (HSI) classification models are highly sensitive to distribution shifts caused by various real-world degradations such as noise, blur, compression, and atmospheric effects. To address this challenge, we propose HyperTTA, a unified framework designed to enhance model robustness under diverse degradation conditions. Specifically, we first construct a multi-degradation hyperspectral dataset that systematically simulates nine representative types of degradations, providing a comprehensive benchmark for robust classification evaluation. Based on this, we design a spectral-spatial transformer classifier (SSTC) enhanced with a multi-level receptive field mechanism and label smoothing regularization to jointly capture multi-scale spatial context and improve generalization. Furthermore, HyperTTA incorporates a lightweight test-time adaptation (TTA) strategy, the confidence-aware entropy-minimized LayerNorm adapter (CELA), which updates only the affine parameters of LayerNorm layers by minimizing prediction entropy on high-confidence unlabeled target samples. This confidence-aware adaptation prevents unreliable updates from noisy predictions, enabling robust and dynamic adaptation without access to source data or target annotations. Extensive experiments on two benchmark datasets demonstrate that HyperTTA outperforms existing baselines across a wide range of degradation scenarios, validating the effectiveness of both its classification backbone and the proposed TTA scheme. Code will be made available publicly.
Towards Efficient Model-Heterogeneity Federated Learning for Large Models
Nov 25, 2024As demand grows for complex tasks and high-performance applications in edge computing, the deployment of large models in federated learning has become increasingly urgent, given their superior representational power and generalization capabilities. However, the resource constraints and heterogeneity among clients present significant challenges to this deployment. To tackle these challenges, we introduce HeteroTune, an innovative fine-tuning framework tailored for model-heterogeneity federated learning (MHFL). In particular, we propose a novel parameter-efficient fine-tuning (PEFT) structure, called FedAdapter, which employs a multi-branch cross-model aggregator to enable efficient knowledge aggregation across diverse models. Benefiting from the lightweight FedAdapter, our approach significantly reduces both the computational and communication overhead. Finally, our approach is simple yet effective, making it applicable to a wide range of large model fine-tuning tasks. Extensive experiments on computer vision (CV) and natural language processing (NLP) tasks demonstrate that our method achieves state-of-the-art results, seamlessly integrating efficiency and performance.
DREB-Net: Dual-stream Restoration Embedding Blur-feature Fusion Network for High-mobility UAV Object Detection
Oct 23, 2024



Object detection algorithms are pivotal components of unmanned aerial vehicle (UAV) imaging systems, extensively employed in complex fields. However, images captured by high-mobility UAVs often suffer from motion blur cases, which significantly impedes the performance of advanced object detection algorithms. To address these challenges, we propose an innovative object detection algorithm specifically designed for blurry images, named DREB-Net (Dual-stream Restoration Embedding Blur-feature Fusion Network). First, DREB-Net addresses the particularities of blurry image object detection problem by incorporating a Blurry image Restoration Auxiliary Branch (BRAB) during the training phase. Second, it fuses the extracted shallow features via Multi-level Attention-Guided Feature Fusion (MAGFF) module, to extract richer features. Here, the MAGFF module comprises local attention modules and global attention modules, which assign different weights to the branches. Then, during the inference phase, the deep feature extraction of the BRAB can be removed to reduce computational complexity and improve detection speed. In loss function, a combined loss of MSE and SSIM is added to the BRAB to restore blurry images. Finally, DREB-Net introduces Fast Fourier Transform in the early stages of feature extraction, via a Learnable Frequency domain Amplitude Modulation Module (LFAMM), to adjust feature amplitude and enhance feature processing capability. Experimental results indicate that DREB-Net can still effectively perform object detection tasks under motion blur in captured images, showcasing excellent performance and broad application prospects. Our source code will be available at https://github.com/EEIC-Lab/DREB-Net.git.
SurANet: Surrounding-Aware Network for Concealed Object Detection via Highly-Efficient Interactive Contrastive Learning Strategy
Oct 09, 2024



Concealed object detection (COD) in cluttered scenes is significant for various image processing applications. However, due to that concealed objects are always similar to their background, it is extremely hard to distinguish them. Here, the major obstacle is the tiny feature differences between the inside and outside object boundary region, which makes it trouble for existing COD methods to achieve accurate results. In this paper, considering that the surrounding environment information can be well utilized to identify the concealed objects, and thus, we propose a novel deep Surrounding-Aware Network, namely SurANet, for COD tasks, which introduces surrounding information into feature extraction and loss function to improve the discrimination. First, we enhance the semantics of feature maps using differential fusion of surrounding features to highlight concealed objects. Next, a Surrounding-Aware Contrastive Loss is applied to identify the concealed object via learning surrounding feature maps contrastively. Then, SurANet can be trained end-to-end with high efficiency via our proposed Spatial-Compressed Correlation Transmission strategy after our investigation of feature dynamics, and extensive experiments improve that such features can be well reserved respectively. Finally, experimental results demonstrate that the proposed SurANet outperforms state-of-the-art COD methods on multiple real datasets. Our source code will be available at https://github.com/kyh433/SurANet.
FusionSAM: Latent Space driven Segment Anything Model for Multimodal Fusion and Segmentation
Aug 26, 2024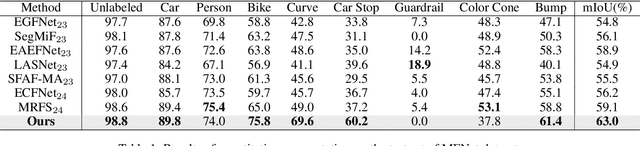
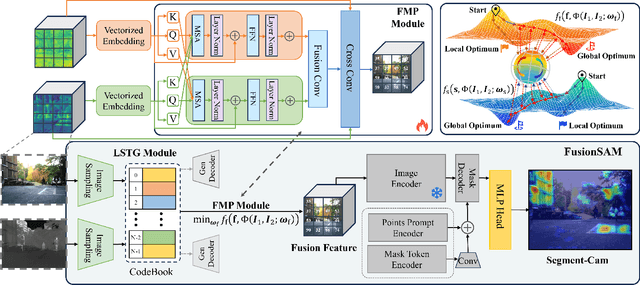
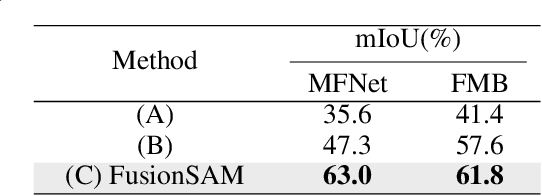

Multimodal image fusion and segmentation enhance scene understanding in autonomous driving by integrating data from various sensors. However, current models struggle to efficiently segment densely packed elements in such scenes, due to the absence of comprehensive fusion features that can guide mid-process fine-tuning and focus attention on relevant areas. The Segment Anything Model (SAM) has emerged as a transformative segmentation method. It provides more effective prompts through its flexible prompt encoder, compared to transformers lacking fine-tuned control. Nevertheless, SAM has not been extensively studied in the domain of multimodal fusion for natural images. In this paper, we introduce SAM into multimodal image segmentation for the first time, proposing a novel framework that combines Latent Space Token Generation (LSTG) and Fusion Mask Prompting (FMP) modules to enhance SAM's multimodal fusion and segmentation capabilities. Specifically, we first obtain latent space features of the two modalities through vector quantization and embed them into a cross-attention-based inter-domain fusion module to establish long-range dependencies between modalities. Then, we use these comprehensive fusion features as prompts to guide precise pixel-level segmentation. Extensive experiments on several public datasets demonstrate that the proposed method significantly outperforms SAM and SAM2 in multimodal autonomous driving scenarios, achieving at least 3.9$\%$ higher segmentation mIoU than the state-of-the-art approaches.
GraphMamba: An Efficient Graph Structure Learning Vision Mamba for Hyperspectral Image Classification
Jul 11, 2024



Efficient extraction of spectral sequences and geospatial information has always been a hot topic in hyperspectral image classification. In terms of spectral sequence feature capture, RNN and Transformer have become mainstream classification frameworks due to their long-range feature capture capabilities. In terms of spatial information aggregation, CNN enhances the receptive field to retain integrated spatial information as much as possible. However, the spectral feature-capturing architectures exhibit low computational efficiency, and CNNs lack the flexibility to perceive spatial contextual information. To address these issues, this paper proposes GraphMamba--an efficient graph structure learning vision Mamba classification framework that fully considers HSI characteristics to achieve deep spatial-spectral information mining. Specifically, we propose a novel hyperspectral visual GraphMamba processing paradigm (HVGM) that preserves spatial-spectral features by constructing spatial-spectral cubes and utilizes linear spectral encoding to enhance the operability of subsequent tasks. The core components of GraphMamba include the HyperMamba module for improving computational efficiency and the SpectralGCN module for adaptive spatial context awareness. The HyperMamba mitigates clutter interference by employing the global mask (GM) and introduces a parallel training inference architecture to alleviate computational bottlenecks. The SpatialGCN incorporates weighted multi-hop aggregation (WMA) spatial encoding to focus on highly correlated spatial structural features, thus flexibly aggregating contextual information while mitigating spatial noise interference. Extensive experiments were conducted on three different scales of real HSI datasets, and compared with the state-of-the-art classification frameworks, GraphMamba achieved optimal performance.
Hyperspectral Anomaly Detection with Self-Supervised Anomaly Prior
Apr 20, 2024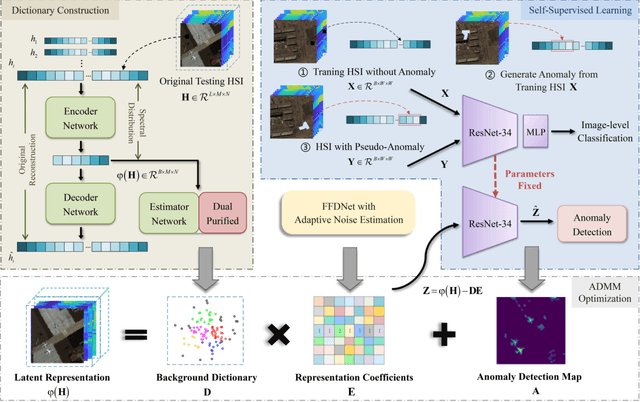


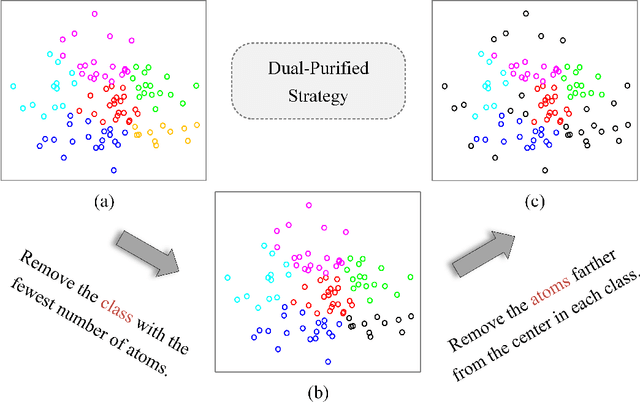
The majority of existing hyperspectral anomaly detection (HAD) methods use the low-rank representation (LRR) model to separate the background and anomaly components, where the anomaly component is optimized by handcrafted sparse priors (e.g., $\ell_{2,1}$-norm). However, this may not be ideal since they overlook the spatial structure present in anomalies and make the detection result largely dependent on manually set sparsity. To tackle these problems, we redefine the optimization criterion for the anomaly component in the LRR model with a self-supervised network called self-supervised anomaly prior (SAP). This prior is obtained by the pretext task of self-supervised learning, which is customized to learn the characteristics of hyperspectral anomalies. Specifically, this pretext task is a classification task to distinguish the original hyperspectral image (HSI) and the pseudo-anomaly HSI, where the pseudo-anomaly is generated from the original HSI and designed as a prism with arbitrary polygon bases and arbitrary spectral bands. In addition, a dual-purified strategy is proposed to provide a more refined background representation with an enriched background dictionary, facilitating the separation of anomalies from complex backgrounds. Extensive experiments on various hyperspectral datasets demonstrate that the proposed SAP offers a more accurate and interpretable solution than other advanced HAD methods.