 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Energy Concentration for Federated Learning in Frequency Domain
Sep 16, 2025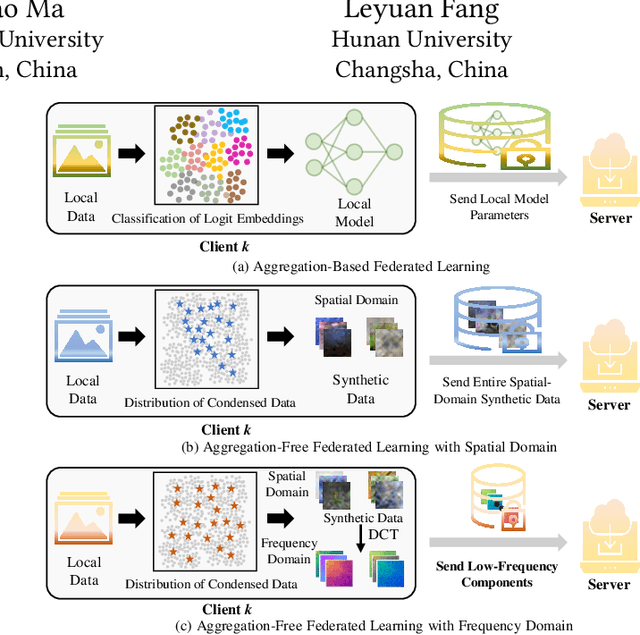
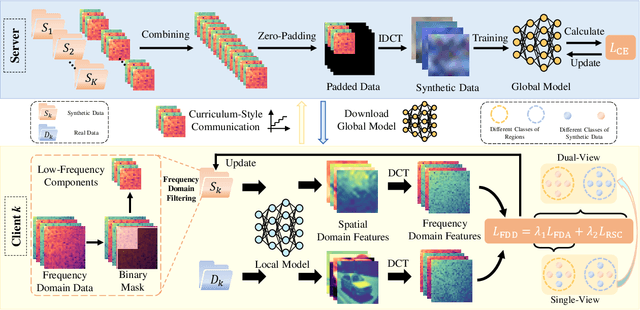
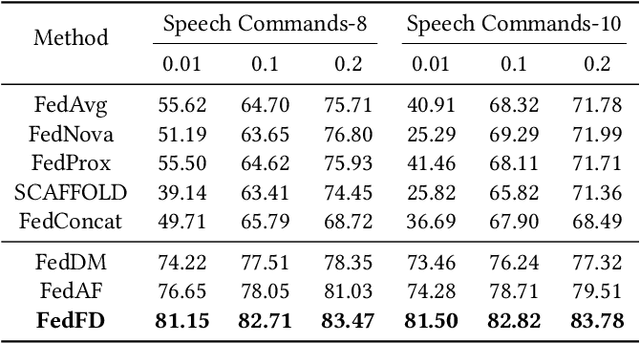
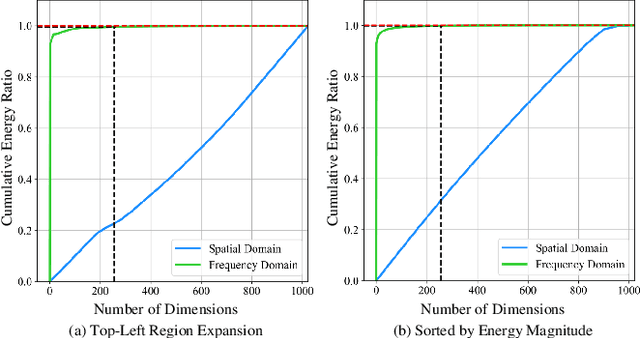
Federated Learning (FL) presents significant potential for collaborative optimization without data sharing. Since synthetic data is sent to the server, leveraging the popular concept of dataset distillation, this FL framework protects real data privacy while alleviating data heterogeneity. However, such methods are still challenged by the redundant information and noise in entire spatial-domain designs, which inevitably increases the communication burden. In this paper, we propose a novel Frequency-Domain aware FL method with high-energy concentration (FedFD) to address this problem. Our FedFD is inspired by the discovery that the discrete cosine transform predominantly distributes energy to specific regions, referred to as high-energy concentration. The principle behind FedFD is that low-energy like high-frequency components usually contain redundant information and noise, thus filtering them helps reduce communication costs and optimize performance. Our FedFD is mathematically formulated to preserve the low-frequency components using a binary mask, facilitating an optimal solution through frequency-domain distribution alignment. In particular, real data-driven synthetic classification is imposed into the loss to enhance the quality of the low-frequency components. On five image and speech datasets, FedFD achieves superior performance than state-of-the-art methods while reducing communication costs. For example, on the CIFAR-10 dataset with Dirichlet coefficient $\alpha = 0.01$, FedFD achieves a minimum reduction of 37.78\% in the communication cost, while attaining a 10.88\% performance gain.
FusionSAM: Latent Space driven Segment Anything Model for Multimodal Fusion and Segmentation
Aug 26, 2024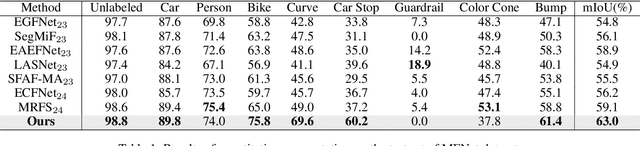
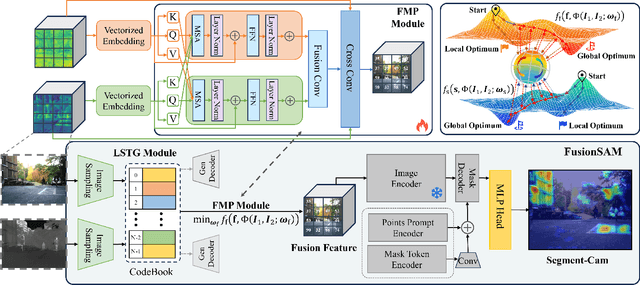
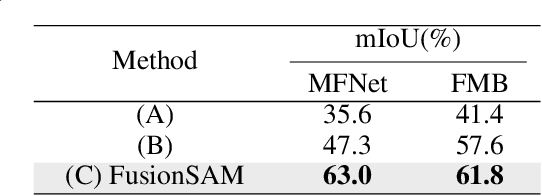

Multimodal image fusion and segmentation enhance scene understanding in autonomous driving by integrating data from various sensors. However, current models struggle to efficiently segment densely packed elements in such scenes, due to the absence of comprehensive fusion features that can guide mid-process fine-tuning and focus attention on relevant areas. The Segment Anything Model (SAM) has emerged as a transformative segmentation method. It provides more effective prompts through its flexible prompt encoder, compared to transformers lacking fine-tuned control. Nevertheless, SAM has not been extensively studied in the domain of multimodal fusion for natural images. In this paper, we introduce SAM into multimodal image segmentation for the first time, proposing a novel framework that combines Latent Space Token Generation (LSTG) and Fusion Mask Prompting (FMP) modules to enhance SAM's multimodal fusion and segmentation capabilities. Specifically, we first obtain latent space features of the two modalities through vector quantization and embed them into a cross-attention-based inter-domain fusion module to establish long-range dependencies between modalities. Then, we use these comprehensive fusion features as prompts to guide precise pixel-level segmentation. Extensive experiments on several public datasets demonstrate that the proposed method significantly outperforms SAM and SAM2 in multimodal autonomous driving scenarios, achieving at least 3.9$\%$ higher segmentation mIoU than the state-of-the-art approaches.
Reducing Spurious Correlation for Federated Domain Generalization
Jul 27, 2024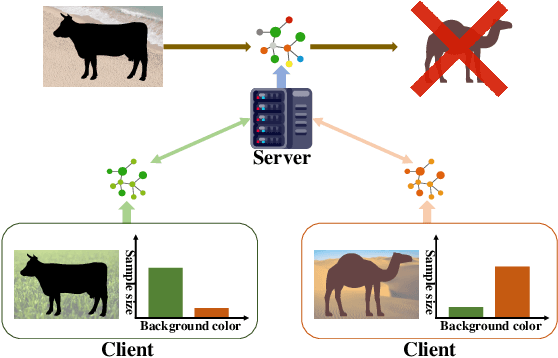
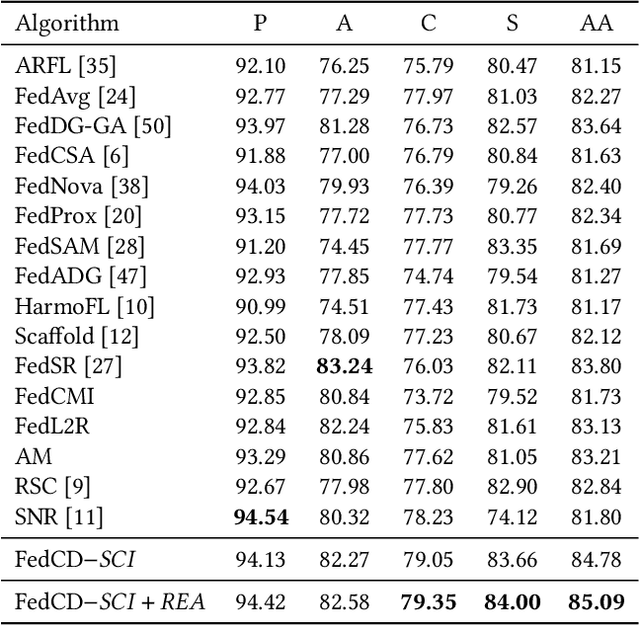
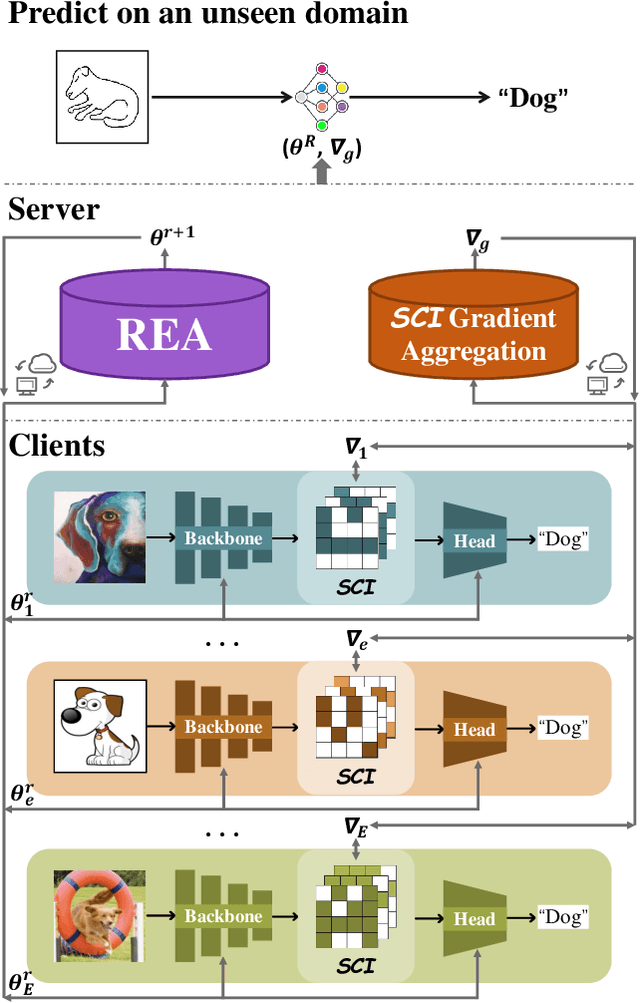
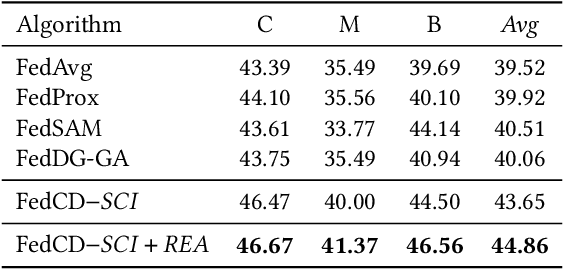
The rapid development of multimedia has provided a large amount of data with different distributions for visual tasks, forming different domains. Federated Learning (FL) can efficiently use this diverse data distributed on different client media in a decentralized manner through model sharing. However, in open-world scenarios, there is a challenge: global models may struggle to predict well on entirely new domain data captured by certain media, which were not encountered during training. Existing methods still rely on strong statistical correlations between samples and labels to address this issue, which can be misleading, as some features may establish spurious short-cut correlations with the predictions. To comprehensively address this challenge, we introduce FedCD (Cross-Domain Invariant Federated Learning), an overall optimization framework at both the local and global levels. We introduce the Spurious Correlation Intervener (SCI), which employs invariance theory to locally generate interventers for features in a self-supervised manner to reduce the model's susceptibility to spurious correlated features. Our approach requires no sharing of data or features, only the gradients related to the model. Additionally, we develop the simple yet effective Risk Extrapolation Aggregation strategy (REA), determining aggregation coefficients through mathematical optimization to facilitate global causal invariant predictions. Extensive experiments and ablation studies highlight the effectiveness of our approach. In both classification and object detection generalization tasks, our method outperforms the baselines by an average of at least 1.45% in Acc, 4.8% and 1.27% in mAP50.
EfficientMFD: Towards More Efficient Multimodal Synchronous Fusion Detection
Mar 14, 2024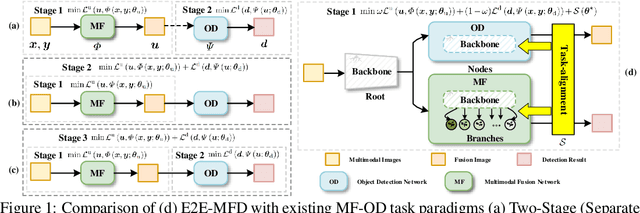
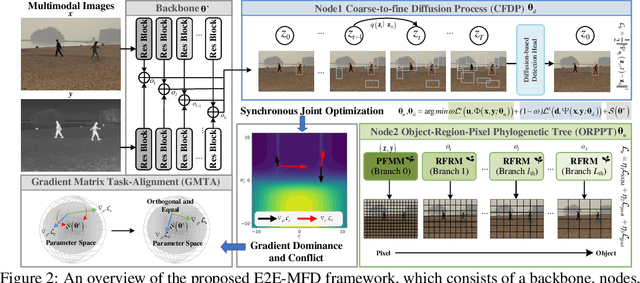
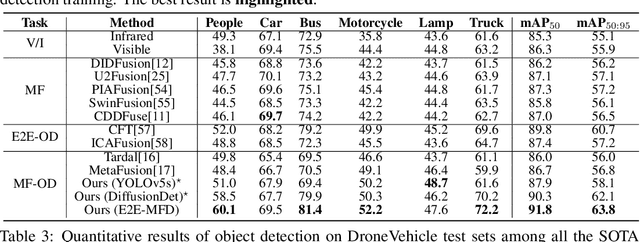

Multimodal image fusion and object detection play a vital role in autonomous driving. Current joint learning methods have made significant progress in the multimodal fusion detection task combining the texture detail and objective semantic information. However, the tedious training steps have limited its applications to wider real-world industrial deployment. To address this limitation, we propose a novel end-to-end multimodal fusion detection algorithm, named EfficientMFD, to simplify models that exhibit decent performance with only one training step. Synchronous joint optimization is utilized in an end-to-end manner between two components, thus not being affected by the local optimal solution of the individual task. Besides, a comprehensive optimization is established in the gradient matrix between the shared parameters for both tasks. It can converge to an optimal point with fusion detection weights. We extensively test it on several public datasets, demonstrating superior performance on not only visually appealing fusion but also favorable detection performance (e.g., 6.6% mAP50:95) over other state-of-the-art approaches.
Multimodal Informative ViT: Information Aggregation and Distribution for Hyperspectral and LiDAR Classification
Jan 06, 2024In multimodal land cover classification (MLCC), a common challenge is the redundancy in data distribution, where irrelevant information from multiple modalities can hinder the effective integration of their unique features. To tackle this, we introduce the Multimodal Informative Vit (MIVit), a system with an innovative information aggregate-distributing mechanism. This approach redefines redundancy levels and integrates performance-aware elements into the fused representation, facilitating the learning of semantics in both forward and backward directions. MIVit stands out by significantly reducing redundancy in the empirical distribution of each modality's separate and fused features. It employs oriented attention fusion (OAF) for extracting shallow local features across modalities in horizontal and vertical dimensions, and a Transformer feature extractor for extracting deep global features through long-range attention. We also propose an information aggregation constraint (IAC) based on mutual information, designed to remove redundant information and preserve complementary information within embedded features. Additionally, the information distribution flow (IDF) in MIVit enhances performance-awareness by distributing global classification information across different modalities' feature maps. This architecture also addresses missing modality challenges with lightweight independent modality classifiers, reducing the computational load typically associated with Transformers. Our results show that MIVit's bidirectional aggregate-distributing mechanism between modalities is highly effective, achieving an average overall accuracy of 95.56% across three multimodal datasets. This performance surpasses current state-of-the-art methods in MLCC. The code for MIVit is accessible at https://github.com/icey-zhang/MIViT.
RS-DGC: Exploring Neighborhood Statistics for Dynamic Gradient Compression on Remote Sensing Image Interpretation
Dec 29, 2023Distributed deep learning has recently been attracting more attention in remote sensing (RS) applications due to the challenges posed by the increased amount of open data that are produced daily by Earth observation programs. However, the high communication costs of sending model updates among multiple nodes are a significant bottleneck for scalable distributed learning. Gradient sparsification has been validated as an effective gradient compression (GC) technique for reducing communication costs and thus accelerating the training speed. Existing state-of-the-art gradient sparsification methods are mostly based on the "larger-absolute-more-important" criterion, ignoring the importance of small gradients, which is generally observed to affect the performance. Inspired by informative representation of manifold structures from neighborhood information, we propose a simple yet effective dynamic gradient compression scheme leveraging neighborhood statistics indicator for RS image interpretation, termed RS-DGC. We first enhance the interdependence between gradients by introducing the gradient neighborhood to reduce the effect of random noise. The key component of RS-DGC is a Neighborhood Statistical Indicator (NSI), which can quantify the importance of gradients within a specified neighborhood on each node to sparsify the local gradients before gradient transmission in each iteration. Further, a layer-wise dynamic compression scheme is proposed to track the importance changes of each layer in real time. Extensive downstream tasks validate the superiority of our method in terms of intelligent interpretation of RS images. For example, we achieve an accuracy improvement of 0.51% with more than 50 times communication compression on the NWPU-RESISC45 dataset using VGG-19 network.
SAR-Net: Multi-scale Direction-aware SAR Network via Global Information Fusion
Dec 28, 2023



Deep learning has driven significant progress in object detection using Synthetic Aperture Radar (SAR) imagery. Existing methods, while achieving promising results, often struggle to effectively integrate local and global information, particularly direction-aware features. This paper proposes SAR-Net, a novel framework specifically designed for global fusion of direction-aware information in SAR object detection. SAR-Net leverages two key innovations: the Unity Compensation Mechanism (UCM) and the Direction-aware Attention Module (DAM). UCM facilitates the establishment of complementary relationships among features across different scales, enabling efficient global information fusion. Among them, Multi-scale Alignment Module (MAM) and distinct Multi-level Fusion Module (MFM) enhance feature integration by capturing both texture detail and semantic information. Then, Multi-feature Embedding Module (MEM) feeds back global features into the primary branches, further improving information transmission. Additionally, DAM, through bidirectional attention polymerization, captures direction-aware information, effectively eliminating background interference. Extensive experiments demonstrate the effectiveness of SAR-Net, achieving state-of-the-art results on aircraft (SAR-AIRcraft-1.0) and ship datasets (SSDD, HRSID), confirming its generalization capability and robustness.
MDFL: Multi-domain Diffusion-driven Feature Learning
Nov 16, 2023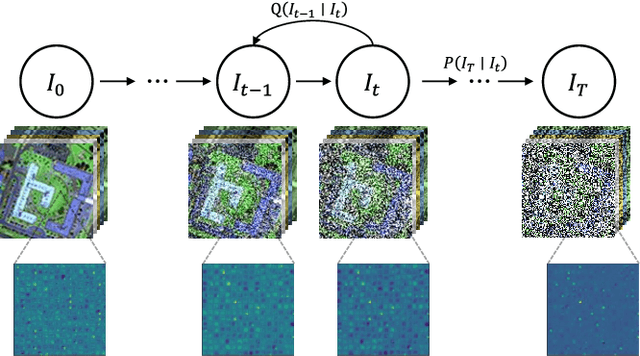
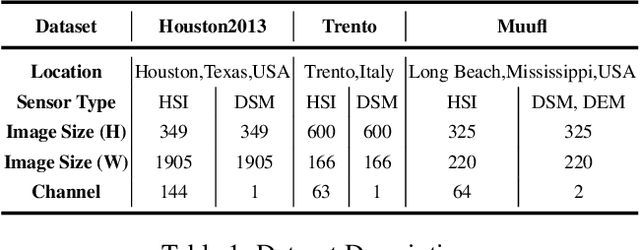
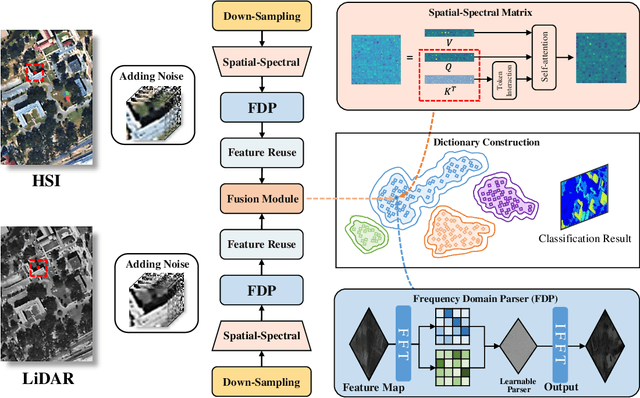
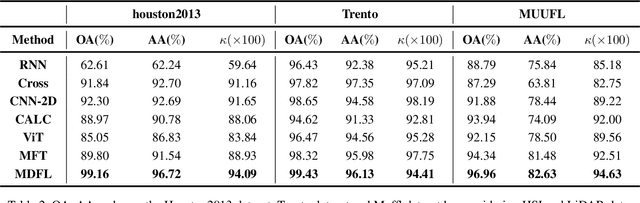
High-dimensional images, known for their rich semantic information, are widely applied in remote sensing and other fields. The spatial information in these images reflects the object's texture features, while the spectral information reveals the potential spectral representations across different bands. Currently, the understanding of high-dimensional images remains limited to a single-domain perspective with performance degradation. Motivated by the masking texture effect observed in the human visual system, we present a multi-domain diffusion-driven feature learning network (MDFL) , a scheme to redefine the effective information domain that the model really focuses on. This method employs diffusion-based posterior sampling to explicitly consider joint information interactions between the high-dimensional manifold structures in the spectral, spatial, and frequency domains, thereby eliminating the influence of masking texture effects in visual models. Additionally, we introduce a feature reuse mechanism to gather deep and raw features of high-dimensional data. We demonstrate that MDFL significantly improves the feature extraction performance of high-dimensional data, thereby providing a powerful aid for revealing the intrinsic patterns and structures of such data. The experimental results on three multi-modal remote sensing datasets show that MDFL reaches an average overall accuracy of 98.25%, outperforming various state-of-the-art baseline schemes. The code will be released, contributing to the computer vision community.