 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Spurious Correlation for Federated Domain Generalization
Paper and Code
Jul 27, 2024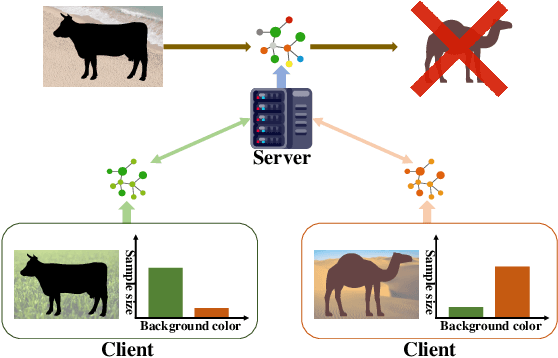
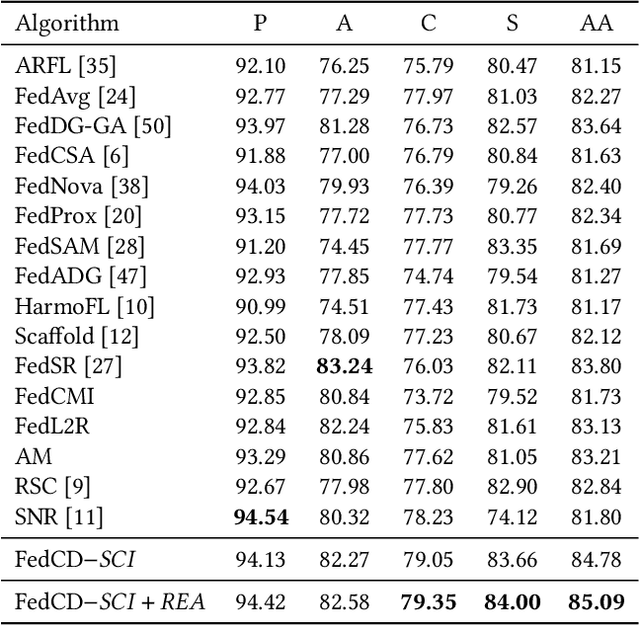
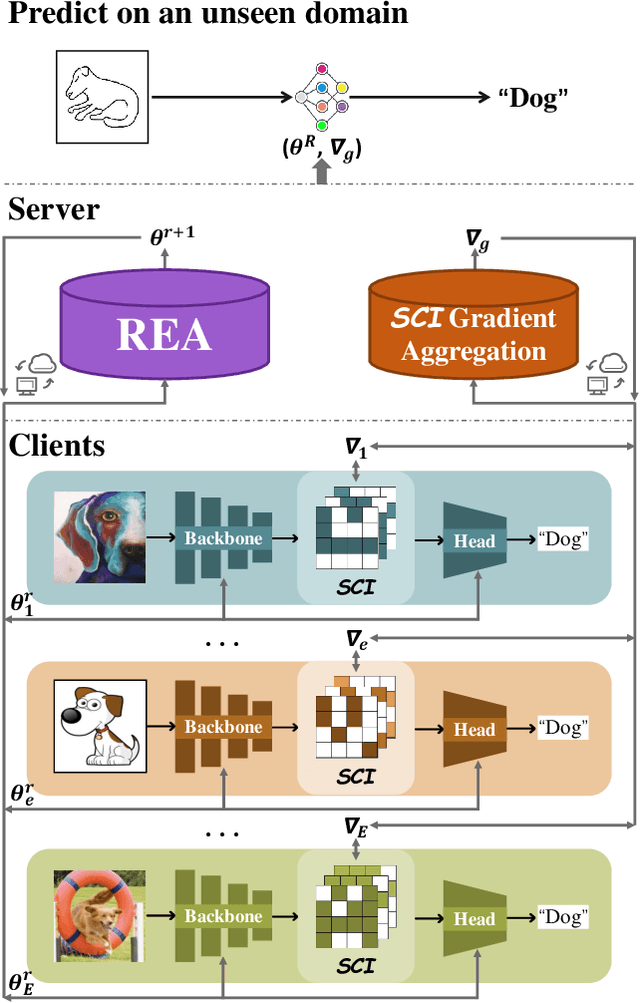
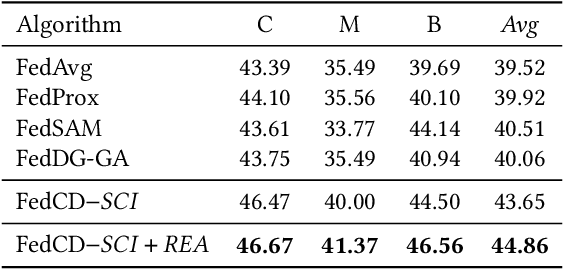
The rapid development of multimedia has provided a large amount of data with different distributions for visual tasks, forming different domains. Federated Learning (FL) can efficiently use this diverse data distributed on different client media in a decentralized manner through model sharing. However, in open-world scenarios, there is a challenge: global models may struggle to predict well on entirely new domain data captured by certain media, which were not encountered during training. Existing methods still rely on strong statistical correlations between samples and labels to address this issue, which can be misleading, as some features may establish spurious short-cut correlations with the predictions. To comprehensively address this challenge, we introduce FedCD (Cross-Domain Invariant Federated Learning), an overall optimization framework at both the local and global levels. We introduce the Spurious Correlation Intervener (SCI), which employs invariance theory to locally generate interventers for features in a self-supervised manner to reduce the model's susceptibility to spurious correlated features. Our approach requires no sharing of data or features, only the gradients related to the model. Additionally, we develop the simple yet effective Risk Extrapolation Aggregation strategy (REA), determining aggregation coefficients through mathematical optimization to facilitate global causal invariant predictions. Extensive experiments and ablation studies highlight the effectiveness of our approach. In both classification and object detection generalization tasks, our method outperforms the baselines by an average of at least 1.45% in Acc, 4.8% and 1.27% in mAP50.