 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoPRo: Enhancing Low-Rank Quantization via Permuted Block-Wise Rotation
Jan 27, 2026Post-training quantization (PTQ) enables effective model compression while preserving relatively high accuracy. Current weight-only PTQ methods primarily focus on the challenging sub-3-bit regime, where approaches often suffer significant accuracy degradation, typically requiring fine-tuning to achieve competitive performance. In this work, we revisit the fundamental characteristics of weight quantization and analyze the challenges in quantizing the residual matrix under low-rank approximation. We propose LoPRo, a novel fine-tuning-free PTQ algorithm that enhances residual matrix quantization by applying block-wise permutation and Walsh-Hadamard transformations to rotate columns of similar importance, while explicitly preserving the quantization accuracy of the most salient column blocks. Furthermore, we introduce a mixed-precision fast low-rank decomposition based on rank-1 sketch (R1SVD) to further minimize quantization costs. Experiments demonstrate that LoPRo outperforms existing fine-tuning-free PTQ methods at both 2-bit and 3-bit quantization, achieving accuracy comparable to fine-tuning baselines. Specifically, LoPRo achieves state-of-the-art quantization accuracy on LLaMA-2 and LLaMA-3 series models while delivering up to a 4$\times$ speedup. In the MoE model Mixtral-8x7B, LoPRo completes quantization within 2.5 hours, simultaneously reducing perplexity by 0.4$\downarrow$ and improving accuracy by 8\%$\uparrow$. Moreover, compared to other low-rank quantization methods, LoPRo achieves superior accuracy with a significantly lower rank, while maintaining high inference efficiency and minimal additional latency.
LightEMMA: Lightweight End-to-End Multimodal Model for Autonomous Driving
May 01, 2025Vision-Language Models (VLMs) have demonstrated significant potential for end-to-end autonomous driving. However, fully exploiting their capabilities for safe and reliable vehicle control remains an open research challenge. To systematically examine advances and limitations of VLMs in driving tasks, we introduce LightEMMA, a Lightweight End-to-End Multimodal Model for Autonomous driving. LightEMMA provides a unified, VLM-based autonomous driving framework without ad hoc customizations, enabling easy integration and evaluation of evolving state-of-the-art commercial and open-source models. We construct twelve autonomous driving agents using various VLMs and evaluate their performance on the nuScenes prediction task, comprehensively assessing metrics such as inference time, computational cost, and predictive accuracy. Illustrative examples highlight that, despite their strong scenario interpretation capabilities, VLMs' practical performance in autonomous driving tasks remains concerning, emphasizing the need for further improvements. The code is available at https://github.com/michigan-traffic-lab/LightEMMA.
Towards Ambiguity-Free Spatial Foundation Model: Rethinking and Decoupling Depth Ambiguity
Mar 08, 2025



Depth ambiguity is a fundamental challenge in spatial scene understanding, especially in transparent scenes where single-depth estimates fail to capture full 3D structure. Existing models, limited to deterministic predictions, overlook real-world multi-layer depth. To address this, we introduce a paradigm shift from single-prediction to multi-hypothesis spatial foundation models. We first present \texttt{MD-3k}, a benchmark exposing depth biases in expert and foundational models through multi-layer spatial relationship labels and new metrics. To resolve depth ambiguity, we propose Laplacian Visual Prompting (LVP), a training-free spectral prompting technique that extracts hidden depth from pre-trained models via Laplacian-transformed RGB inputs. By integrating LVP-inferred depth with standard RGB-based estimates, our approach elicits multi-layer depth without model retraining. Extensive experiments validate the effectiveness of LVP in zero-shot multi-layer depth estimation, unlocking more robust and comprehensive geometry-conditioned visual generation, 3D-grounded spatial reasoning, and temporally consistent video-level depth inference. Our benchmark and code will be available at https://github.com/Xiaohao-Xu/Ambiguity-in-Space.
Reducing Spurious Correlation for Federated Domain Generalization
Jul 27, 2024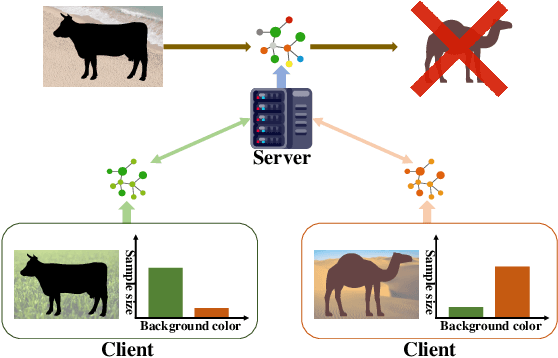
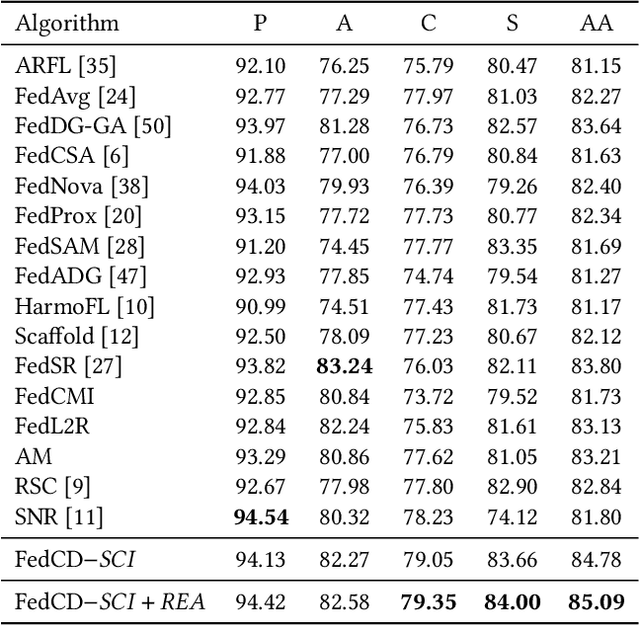
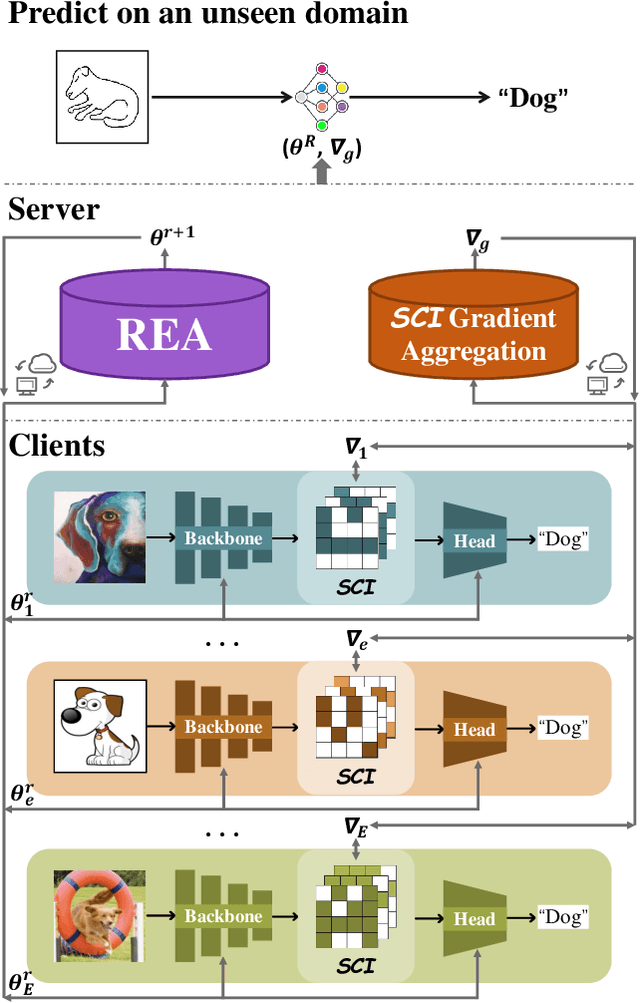
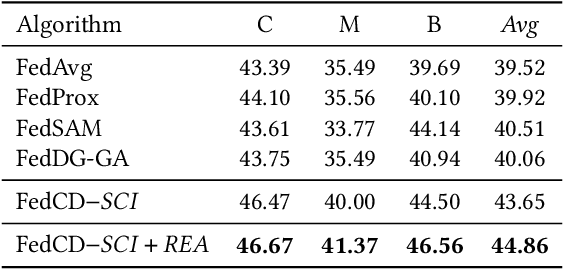
The rapid development of multimedia has provided a large amount of data with different distributions for visual tasks, forming different domains. Federated Learning (FL) can efficiently use this diverse data distributed on different client media in a decentralized manner through model sharing. However, in open-world scenarios, there is a challenge: global models may struggle to predict well on entirely new domain data captured by certain media, which were not encountered during training. Existing methods still rely on strong statistical correlations between samples and labels to address this issue, which can be misleading, as some features may establish spurious short-cut correlations with the predictions. To comprehensively address this challenge, we introduce FedCD (Cross-Domain Invariant Federated Learning), an overall optimization framework at both the local and global levels. We introduce the Spurious Correlation Intervener (SCI), which employs invariance theory to locally generate interventers for features in a self-supervised manner to reduce the model's susceptibility to spurious correlated features. Our approach requires no sharing of data or features, only the gradients related to the model. Additionally, we develop the simple yet effective Risk Extrapolation Aggregation strategy (REA), determining aggregation coefficients through mathematical optimization to facilitate global causal invariant predictions. Extensive experiments and ablation studies highlight the effectiveness of our approach. In both classification and object detection generalization tasks, our method outperforms the baselines by an average of at least 1.45% in Acc, 4.8% and 1.27% in mAP50.
Nearest is Not Dearest: Towards Practical Defense against Quantization-conditioned Backdoor Attacks
May 21, 2024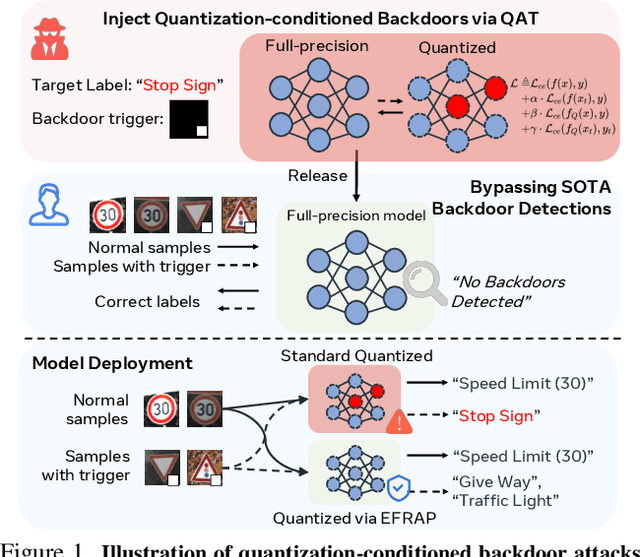
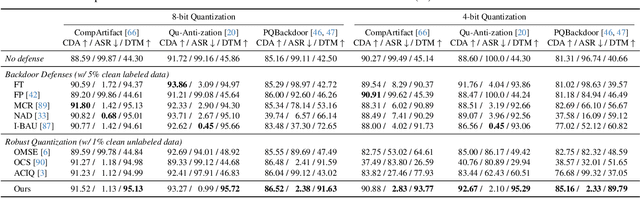
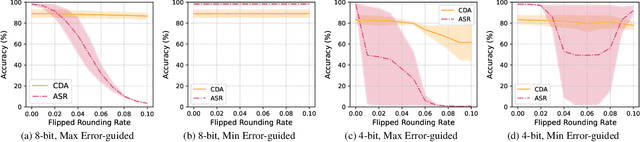
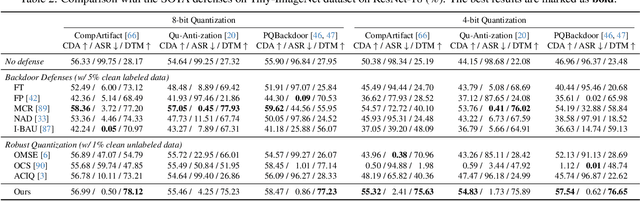
Model quantization is widely used to compress and accelerate deep neural networks. However, recent studies have revealed the feasibility of weaponizing model quantization via implanting quantization-conditioned backdoors (QCBs). These special backdoors stay dormant on released full-precision models but will come into effect after standard quantization. Due to the peculiarity of QCBs, existing defenses have minor effects on reducing their threats or are even infeasible. In this paper, we conduct the first in-depth analysis of QCBs. We reveal that the activation of existing QCBs primarily stems from the nearest rounding operation and is closely related to the norms of neuron-wise truncation errors (i.e., the difference between the continuous full-precision weights and its quantized version). Motivated by these insights, we propose Error-guided Flipped Rounding with Activation Preservation (EFRAP), an effective and practical defense against QCBs. Specifically, EFRAP learns a non-nearest rounding strategy with neuron-wise error norm and layer-wise activation preservation guidance, flipping the rounding strategies of neurons crucial for backdoor effects but with minimal impact on clean accuracy. Extensive evaluations on benchmark datasets demonstrate that our EFRAP can defeat state-of-the-art QCB attacks under various settings. Code is available at https://github.com/AntigoneRandy/QuantBackdoor_EFRAP.
Segment Any Medical Model Extended
Mar 26, 2024The Segment Anything Model (SAM) has drawn significant attention from researchers who work on medical image segmentation because of its generalizability. However, researchers have found that SAM may have limited performance on medical images compared to state-of-the-art non-foundation models. Regardless, the community sees potential in extending, fine-tuning, modifying, and evaluating SAM for analysis of medical imaging. An increasing number of works have been published focusing on the mentioned four directions, where variants of SAM are proposed. To this end, a unified platform helps push the boundary of the foundation model for medical images, facilitating the use, modification, and validation of SAM and its variants in medical image segmentation. In this work, we introduce SAMM Extended (SAMME), a platform that integrates new SAM variant models, adopts faster communication protocols, accommodates new interactive modes, and allows for fine-tuning of subcomponents of the models. These features can expand the potential of foundation models like SAM, and the results can be translated to applications such as image-guided therapy, mixed reality interaction, robotic navigation, and data augmentation.
Navigate Biopsy with Ultrasound under Augmented Reality Device: Towards Higher System Performance
Feb 04, 2024
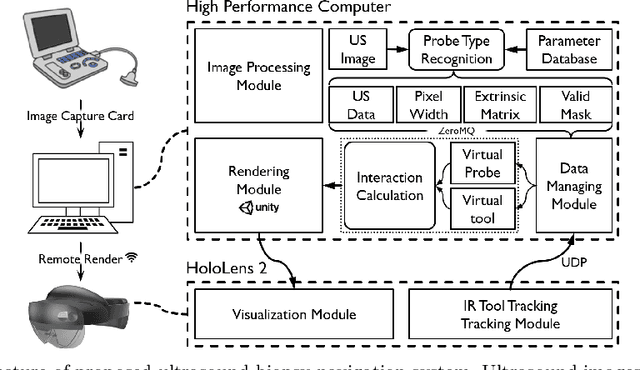
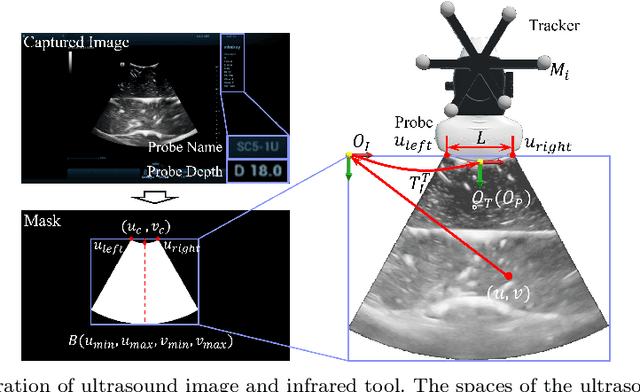
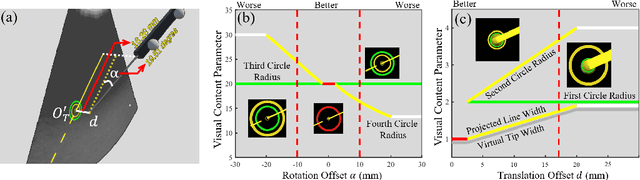
Purpose: Biopsies play a crucial role in determining the classification and staging of tumors. Ultrasound is frequently used in this procedure to provide real-time anatomical information. Using augmented reality (AR), surgeons can visualize ultrasound data and spatial navigation information seamlessly integrated with real tissues. This innovation facilitates faster and more precise biopsy operations. Methods: We developed an AR biopsy navigation system with low display latency and high accuracy. Ultrasound data is initially read by an image capture card and streamed to Unity via net communication. In Unity, navigation information is rendered and transmitted to the HoloLens 2 device using holographic remoting. Retro-reflective tool tracking is implemented on the HoloLens 2, enabling simultaneous tracking of the ultrasound probe and biopsy needle. Distinct navigation information is provided during in-plane and out-of-plane punctuation. To evaluate the effectiveness of our system, we conducted a study involving ten participants, for puncture accuracy and biopsy time, comparing to traditional methods. Results: Our proposed framework enables ultrasound visualization in AR with only $16.22\pm11.45ms$ additional latency. Navigation accuracy reached $1.23\pm 0.68mm$ in the image plane and $0.95\pm 0.70mm$ outside the image plane. Remarkably, the utilization of our system led to $98\%$ and $95\%$ success rate in out-of-plane and in-plane biopsy. Conclusion: To sum up, this paper introduces an AR-based ultrasound biopsy navigation system characterized by high navigation accuracy and minimal latency. The system provides distinct visualization contents during in-plane and out-of-plane operations according to their different characteristics. Use case study in this paper proved that our system can help young surgeons perform biopsy faster and more accurately.
CurriculumLoc: Enhancing Cross-Domain Geolocalization through Multi-Stage Refinement
Nov 20, 2023



Visual geolocalization is a cost-effective and scalable task that involves matching one or more query images, taken at some unknown location, to a set of geo-tagged reference images. Existing methods, devoted to semantic features representation, evolving towards robustness to a wide variety between query and reference, including illumination and viewpoint changes, as well as scale and seasonal variations. However, practical visual geolocalization approaches need to be robust in appearance changing and extreme viewpoint variation conditions, while providing accurate global location estimates. Therefore, inspired by curriculum design, human learn general knowledge first and then delve into professional expertise. We first recognize semantic scene and then measure geometric structure. Our approach, termed CurriculumLoc, involves a delicate design of multi-stage refinement pipeline and a novel keypoint detection and description with global semantic awareness and local geometric verification. We rerank candidates and solve a particular cross-domain perspective-n-point (PnP) problem based on these keypoints and corresponding descriptors, position refinement occurs incrementally. The extensive experimental results on our collected dataset, TerraTrack and a benchmark dataset, ALTO, demonstrate that our approach results in the aforementioned desirable characteristics of a practical visual geolocalization solution. Additionally, we achieve new high recall@1 scores of 62.6% and 94.5% on ALTO, with two different distances metrics, respectively. Dataset, code and trained models are publicly available on https://github.com/npupilab/CurriculumLoc.
EVD Surgical Guidance with Retro-Reflective Tool Tracking and Spatial Reconstruction using Head-Mounted Augmented Reality Device
Jul 03, 2023



Augmented Reality (AR) has been used to facilitate surgical guidance during External Ventricular Drain (EVD) surgery, reducing the risks of misplacement in manual operations. During this procedure, the key challenge is accurately estimating the spatial relationship between pre-operative images and actual patient anatomy in AR environment. This research proposes a novel framework utilizing Time of Flight (ToF) depth sensors integrated in commercially available AR Head Mounted Devices (HMD) for precise EVD surgical guidance. As previous studies have proven depth errors for ToF sensors, we first assessed their properties on AR-HMDs. Subsequently, a depth error model and patient-specific parameter identification method are introduced for accurate surface information. A tracking pipeline combining retro-reflective markers and point clouds is then proposed for accurate head tracking. The head surface is reconstructed using depth data for spatial registration, avoiding fixing tracking targets rigidly on the patient's skull. Firstly, $7.580\pm 1.488 mm$ depth value error was revealed on human skin, indicating the significance of depth correction. Our results showed that the error was reduced by over $85\%$ using proposed depth correction method on head phantoms in different materials. Meanwhile, the head surface reconstructed with corrected depth data achieved sub-millimetre accuracy. An experiment on sheep head revealed $0.79 mm$ reconstruction error. Furthermore, a user study was conducted for the performance in simulated EVD surgery, where five surgeons performed nine k-wire injections on a head phantom with virtual guidance. Results of this study revealed $2.09 \pm 0.16 mm$ translational accuracy and $2.97\pm 0.91$ degree orientational accuracy.
STTAR: Surgical Tool Tracking using off-the-shelf Augmented Reality Head-Mounted Displays
Aug 17, 2022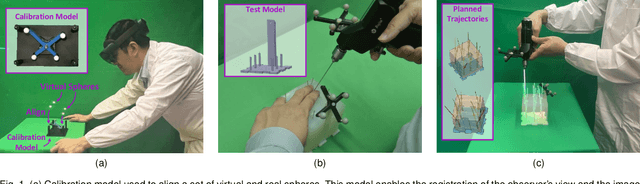

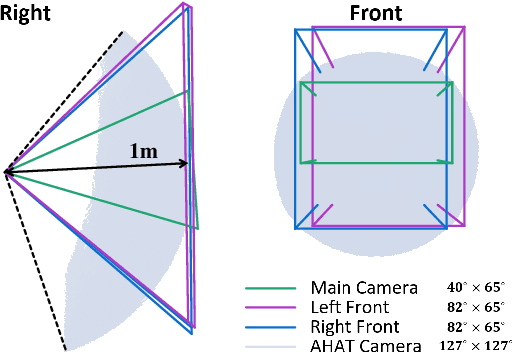
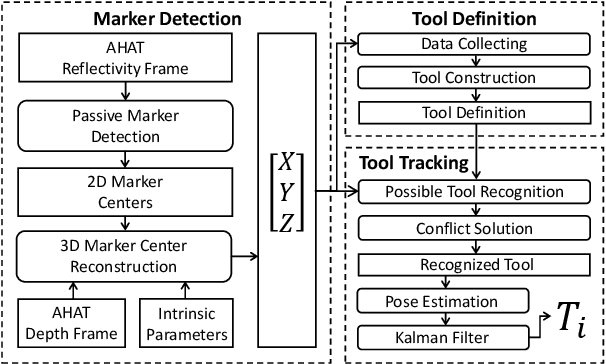
The use of Augmented Reality (AR) for navigation purposes has shown beneficial in assisting physicians during the performance of surgical procedures. These applications commonly require knowing the pose of surgical tools and patients to provide visual information that surgeons can use during the task performance. Existing medical-grade tracking systems use infrared cameras placed inside the Operating Room (OR) to identify retro-reflective markers attached to objects of interest and compute their pose. Some commercially available AR Head-Mounted Displays (HMDs) use similar cameras for self-localization, hand tracking, and estimating the objects' depth. This work presents a framework that uses the built-in cameras of AR HMDs to enable accurate tracking of retro-reflective markers, such as those used in surgical procedures, without the need to integrate any additional components. This framework is also capable of simultaneously tracking multiple tools. Our results show that the tracking and detection of the markers can be achieved with an accuracy of 0.09 +- 0.06 mm on lateral translation, 0.42 +- 0.32 mm on longitudinal translation, and 0.80 +- 0.39 deg for rotations around the vertical axis. Furthermore, to showcase the relevance of the proposed framework, we evaluate the system's performance in the context of surgical procedures. This use case was designed to replicate the scenarios of k-wire insertions in orthopedic procedures. For evaluation, two surgeons and one biomedical researcher were provided with visual navigation, each performing 21 injections. Results from this use case provide comparable accuracy to those reported in the literature for AR-based navigation procedures.