 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCambrian-S: Towards Spatial Supersensing in Video
Nov 06, 2025We argue that progress in true multimodal intelligence calls for a shift from reactive, task-driven systems and brute-force long context towards a broader paradigm of supersensing. We frame spatial supersensing as four stages beyond linguistic-only understanding: semantic perception (naming what is seen), streaming event cognition (maintaining memory across continuous experiences), implicit 3D spatial cognition (inferring the world behind pixels), and predictive world modeling (creating internal models that filter and organize information). Current benchmarks largely test only the early stages, offering narrow coverage of spatial cognition and rarely challenging models in ways that require true world modeling. To drive progress in spatial supersensing, we present VSI-SUPER, a two-part benchmark: VSR (long-horizon visual spatial recall) and VSC (continual visual spatial counting). These tasks require arbitrarily long video inputs yet are resistant to brute-force context expansion. We then test data scaling limits by curating VSI-590K and training Cambrian-S, achieving +30% absolute improvement on VSI-Bench without sacrificing general capabilities. Yet performance on VSI-SUPER remains limited, indicating that scale alone is insufficient for spatial supersensing. We propose predictive sensing as a path forward, presenting a proof-of-concept in which a self-supervised next-latent-frame predictor leverages surprise (prediction error) to drive memory and event segmentation. On VSI-SUPER, this approach substantially outperforms leading proprietary baselines, showing that spatial supersensing requires models that not only see but also anticipate, select, and organize experience.
Benchmark Designers Should "Train on the Test Set" to Expose Exploitable Non-Visual Shortcuts
Nov 06, 2025Robust benchmarks are crucial for evaluating Multimodal Large Language Models (MLLMs). Yet we find that models can ace many multimodal benchmarks without strong visual understanding, instead exploiting biases, linguistic priors, and superficial patterns. This is especially problematic for vision-centric benchmarks that are meant to require visual inputs. We adopt a diagnostic principle for benchmark design: if a benchmark can be gamed, it will be. Designers should therefore try to ``game'' their own benchmarks first, using diagnostic and debiasing procedures to systematically identify and mitigate non-visual biases. Effective diagnosis requires directly ``training on the test set'' -- probing the released test set for its intrinsic, exploitable patterns. We operationalize this standard with two components. First, we diagnose benchmark susceptibility using a ``Test-set Stress-Test'' (TsT) methodology. Our primary diagnostic tool involves fine-tuning a powerful Large Language Model via $k$-fold cross-validation on exclusively the non-visual, textual inputs of the test set to reveal shortcut performance and assign each sample a bias score $s(x)$. We complement this with a lightweight Random Forest-based diagnostic operating on hand-crafted features for fast, interpretable auditing. Second, we debias benchmarks by filtering high-bias samples using an ``Iterative Bias Pruning'' (IBP) procedure. Applying this framework to four benchmarks -- VSI-Bench, CV-Bench, MMMU, and VideoMME -- we uncover pervasive non-visual biases. As a case study, we apply our full framework to create VSI-Bench-Debiased, demonstrating reduced non-visual solvability and a wider vision-blind performance gap than the original.
VideoNSA: Native Sparse Attention Scales Video Understanding
Oct 02, 2025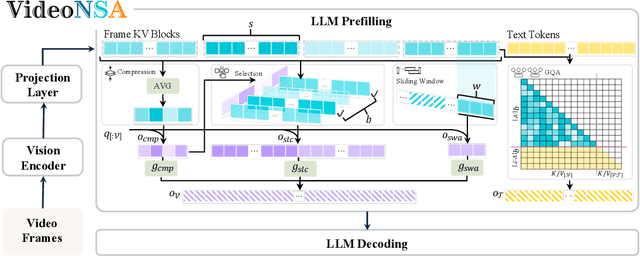
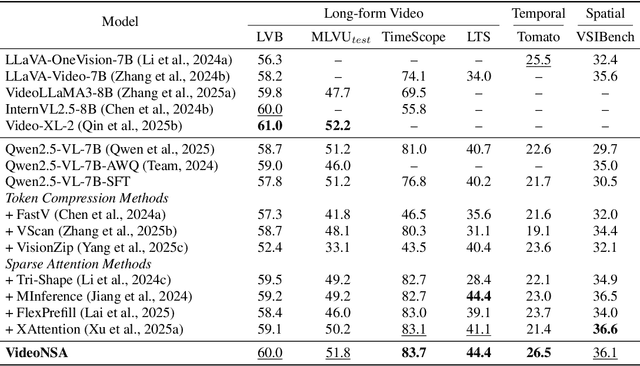
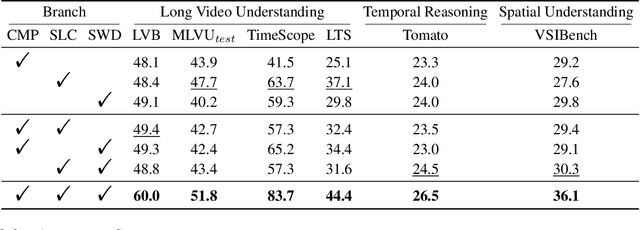
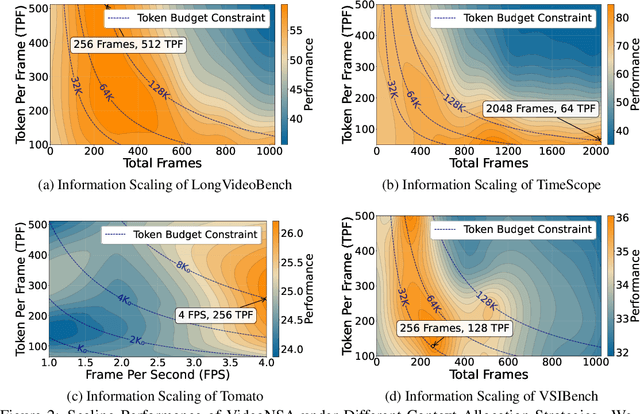
Video understanding in multimodal language models remains limited by context length: models often miss key transition frames and struggle to maintain coherence across long time scales. To address this, we adapt Native Sparse Attention (NSA) to video-language models. Our method, VideoNSA, adapts Qwen2.5-VL through end-to-end training on a 216K video instruction dataset. We employ a hardware-aware hybrid approach to attention, preserving dense attention for text, while employing NSA for video. Compared to token-compression and training-free sparse baselines, VideoNSA achieves improved performance on long-video understanding, temporal reasoning, and spatial benchmarks. Further ablation analysis reveals four key findings: (1) reliable scaling to 128K tokens; (2) an optimal global-local attention allocation at a fixed budget; (3) task-dependent branch usage patterns; and (4) the learnable combined sparse attention help induce dynamic attention sinks.
Towards Ambiguity-Free Spatial Foundation Model: Rethinking and Decoupling Depth Ambiguity
Mar 08, 2025



Depth ambiguity is a fundamental challenge in spatial scene understanding, especially in transparent scenes where single-depth estimates fail to capture full 3D structure. Existing models, limited to deterministic predictions, overlook real-world multi-layer depth. To address this, we introduce a paradigm shift from single-prediction to multi-hypothesis spatial foundation models. We first present \texttt{MD-3k}, a benchmark exposing depth biases in expert and foundational models through multi-layer spatial relationship labels and new metrics. To resolve depth ambiguity, we propose Laplacian Visual Prompting (LVP), a training-free spectral prompting technique that extracts hidden depth from pre-trained models via Laplacian-transformed RGB inputs. By integrating LVP-inferred depth with standard RGB-based estimates, our approach elicits multi-layer depth without model retraining. Extensive experiments validate the effectiveness of LVP in zero-shot multi-layer depth estimation, unlocking more robust and comprehensive geometry-conditioned visual generation, 3D-grounded spatial reasoning, and temporally consistent video-level depth inference. Our benchmark and code will be available at https://github.com/Xiaohao-Xu/Ambiguity-in-Space.
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
Dec 18, 2024



Humans possess the visual-spatial intelligence to remember spaces from sequential visual observations. However, can Multimodal Large Language Models (MLLMs) trained on million-scale video datasets also ``think in space'' from videos? We present a novel video-based visual-spatial intelligence benchmark (VSI-Bench) of over 5,000 question-answer pairs, and find that MLLMs exhibit competitive - though subhuman - visual-spatial intelligence. We probe models to express how they think in space both linguistically and visually and find that while spatial reasoning capabilities remain the primary bottleneck for MLLMs to reach higher benchmark performance, local world models and spatial awareness do emerge within these models. Notably, prevailing linguistic reasoning techniques (e.g., chain-of-thought, self-consistency, tree-of-thoughts) fail to improve performance, whereas explicitly generating cognitive maps during question-answering enhances MLLMs' spatial distance ability.
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Jun 24, 2024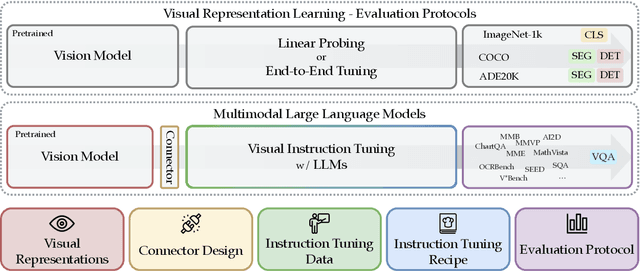


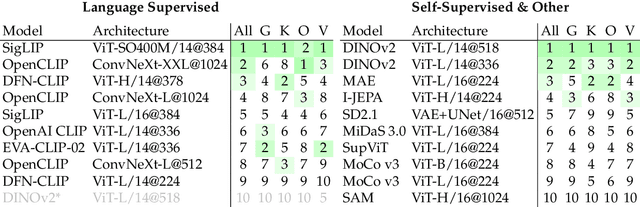
We introduce Cambrian-1, a family of multimodal LLMs (MLLMs) designed with a vision-centric approach. While stronger language models can enhance multimodal capabilities, the design choices for vision components are often insufficiently explored and disconnected from visual representation learning research. This gap hinders accurate sensory grounding in real-world scenarios. Our study uses LLMs and visual instruction tuning as an interface to evaluate various visual representations, offering new insights into different models and architectures -- self-supervised, strongly supervised, or combinations thereof -- based on experiments with over 20 vision encoders. We critically examine existing MLLM benchmarks, addressing the difficulties involved in consolidating and interpreting results from various tasks, and introduce a new vision-centric benchmark, CV-Bench. To further improve visual grounding, we propose the Spatial Vision Aggregator (SVA), a dynamic and spatially-aware connector that integrates high-resolution vision features with LLMs while reducing the number of tokens. Additionally, we discuss the curation of high-quality visual instruction-tuning data from publicly available sources, emphasizing the importance of data source balancing and distribution ratio. Collectively, Cambrian-1 not only achieves state-of-the-art performance but also serves as a comprehensive, open cookbook for instruction-tuned MLLMs. We provide model weights, code, supporting tools, datasets, and detailed instruction-tuning and evaluation recipes. We hope our release will inspire and accelerate advancements in multimodal systems and visual representation learning.
Qwen Technical Report
Sep 28, 2023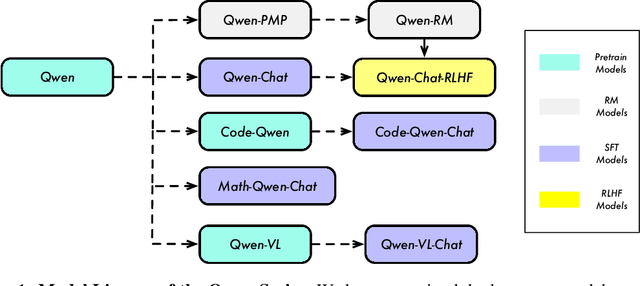

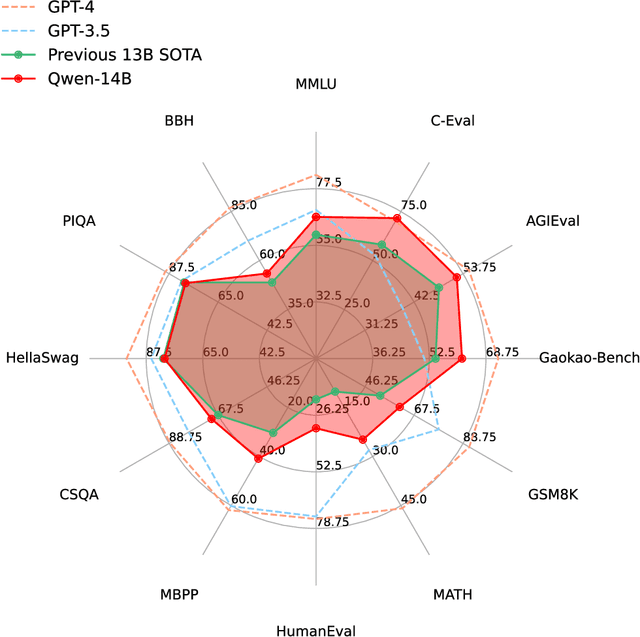
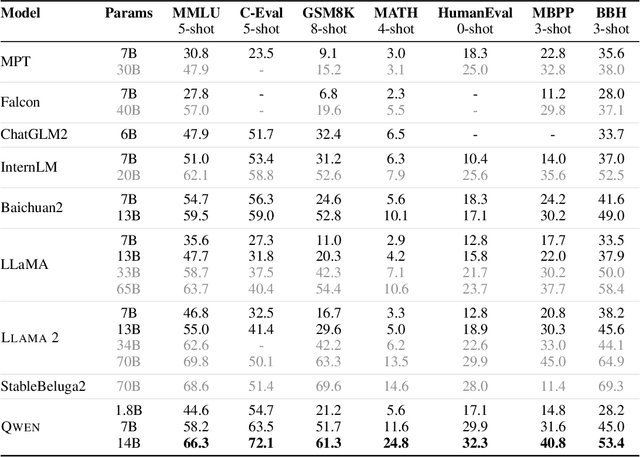
Large language models (LLMs) have revolutionized the field of artificial intelligence, enabling natural language processing tasks that were previously thought to be exclusive to humans. In this work, we introduce Qwen, the first installment of our large language model series. Qwen is a comprehensive language model series that encompasses distinct models with varying parameter counts. It includes Qwen, the base pretrained language models, and Qwen-Chat, the chat models finetuned with human alignment techniques. The base language models consistently demonstrate superior performance across a multitude of downstream tasks, and the chat models, particularly those trained using Reinforcement Learning from Human Feedback (RLHF), are highly competitive. The chat models possess advanced tool-use and planning capabilities for creating agent applications, showcasing impressive performance even when compared to bigger models on complex tasks like utilizing a code interpreter. Furthermore, we have developed coding-specialized models, Code-Qwen and Code-Qwen-Chat, as well as mathematics-focused models, Math-Qwen-Chat, which are built upon base language models. These models demonstrate significantly improved performance in comparison with open-source models, and slightly fall behind the proprietary models.
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
Sep 14, 2023


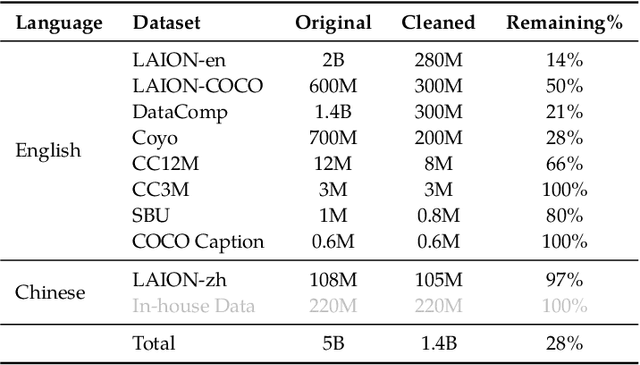
We introduce the Qwen-VL series, a set of large-scale vision-language models (LVLMs) designed to perceive and understand both text and images. Comprising Qwen-VL and Qwen-VL-Chat, these models exhibit remarkable performance in tasks like image captioning, question answering, visual localization, and flexible interaction. The evaluation covers a wide range of tasks including zero-shot captioning, visual or document visual question answering, and grounding. We demonstrate the Qwen-VL outperforms existing LVLMs. We present their architecture, training, capabilities, and performance, highlighting their contributions to advancing multimodal artificial intelligence. Code, demo and models are available at https://github.com/QwenLM/Qwen-VL.
TouchStone: Evaluating Vision-Language Models by Language Models
Sep 04, 2023Large vision-language models (LVLMs) have recently witnessed rapid advancements, exhibiting a remarkable capacity for perceiving, understanding, and processing visual information by connecting visual receptor with large language models (LLMs). However, current assessments mainly focus on recognizing and reasoning abilities, lacking direct evaluation of conversational skills and neglecting visual storytelling abilities. In this paper, we propose an evaluation method that uses strong LLMs as judges to comprehensively evaluate the various abilities of LVLMs. Firstly, we construct a comprehensive visual dialogue dataset TouchStone, consisting of open-world images and questions, covering five major categories of abilities and 27 subtasks. This dataset not only covers fundamental recognition and comprehension but also extends to literary creation. Secondly, by integrating detailed image annotations we effectively transform the multimodal input content into a form understandable by LLMs. This enables us to employ advanced LLMs for directly evaluating the quality of the multimodal dialogue without requiring human intervention. Through validation, we demonstrate that powerful LVLMs, such as GPT-4, can effectively score dialogue quality by leveraging their textual capabilities alone, aligning with human preferences. We hope our work can serve as a touchstone for LVLMs' evaluation and pave the way for building stronger LVLMs. The evaluation code is available at https://github.com/OFA-Sys/TouchStone.
ViTMatte: Boosting Image Matting with Pretrained Plain Vision Transformers
May 24, 2023



Recently, plain vision Transformers (ViTs) have shown impressive performance on various computer vision tasks, thanks to their strong modeling capacity and large-scale pretraining. However, they have not yet conquered the problem of image matting. We hypothesize that image matting could also be boosted by ViTs and present a new efficient and robust ViT-based matting system, named ViTMatte. Our method utilizes (i) a hybrid attention mechanism combined with a convolution neck to help ViTs achieve an excellent performance-computation trade-off in matting tasks. (ii) Additionally, we introduce the detail capture module, which just consists of simple lightweight convolutions to complement the detailed information required by matting. To the best of our knowledge, ViTMatte is the first work to unleash the potential of ViT on image matting with concise adaptation. It inherits many superior properties from ViT to matting, including various pretraining strategies, concise architecture design, and flexible inference strategies. We evaluate ViTMatte on Composition-1k and Distinctions-646, the most commonly used benchmark for image matting, our method achieves state-of-the-art performance and outperforms prior matting works by a large margin.