 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCambrian-P: Pose-Grounded Video Understanding
May 21, 2026Camera pose matters. The position and orientation of each viewpoint define a shared spatial coordinate frame that relates observations across video frames. Yet this signal is largely absent from multimodal LLMs (MLLMs) for video understanding, which process frames as isolated 2D snapshots, instead of the persistent scene humans perceive. We revisit pose as a lightweight supervisory signal and introduce Cambrian-P, a video MLLM augmented with per-frame learnable camera tokens and a pose regression head. With a carefully designed sampling scheme, the model achieves substantial gains of 4.5-6.5% on spatial reasoning benchmarks such as VSI-Bench, generalizes across eight additional spatial and general video QA benchmarks, and, as a byproduct, achieves state of the art streaming pose estimation on ScanNet. Surprisingly, training on pseudo-annotated poses from in-the-wild video further improves general video QA benchmarks, showing pose helps beyond spatial reasoning. Together, these results position camera pose as a fundamental signal for video models that reason about the physical world.
From Where Things Are to What They Are For: Benchmarking Spatial-Functional Intelligence in Multimodal LLMs
May 04, 2026Human-level agentic intelligence extends beyond low-level geometric perception, evolving from recognizing where things are to understanding what they are for. While existing benchmarks effectively evaluate the geometric perception capabilities of multimodal large language models (MLLMs), they fall short of probing the higher-order cognitive abilities required for grounded intelligence. To address this gap, we introduce the Spatial-Functional Intelligence Benchmark (SFI-Bench), a video-based benchmark with over 1,500 expert-annotated questions derived from diverse egocentric indoor video scans. SFI-Bench systematically evaluates two complementary dimensions of advanced reasoning: (1) Structured Spatial Reasoning, which requires understanding complex layouts and forming coherent spatial representations, and (2) Functional Reasoning, which involves inferring object affordances and their context-dependent utility. The benchmark includes tasks such as conditional counting, multi-hop relational reasoning, functional pairing, and knowledge-grounded troubleshooting, directly challenging models to integrate perception, memory, and inference. Our experiments reveal that current MLLMs consistently struggle to combine spatial memory with functional reasoning and external knowledge, highlighting a critical bottleneck in achieving grounded intelligence. SFI-Bench therefore provides a diagnostic tool for measuring progress toward more cognitively capable and truly grounded multimodal agents.
Scaling Text-to-Image Diffusion Transformers with Representation Autoencoders
Jan 22, 2026Representation Autoencoders (RAEs) have shown distinct advantages in diffusion modeling on ImageNet by training in high-dimensional semantic latent spaces. In this work, we investigate whether this framework can scale to large-scale, freeform text-to-image (T2I) generation. We first scale RAE decoders on the frozen representation encoder (SigLIP-2) beyond ImageNet by training on web, synthetic, and text-rendering data, finding that while scale improves general fidelity, targeted data composition is essential for specific domains like text. We then rigorously stress-test the RAE design choices originally proposed for ImageNet. Our analysis reveals that scaling simplifies the framework: while dimension-dependent noise scheduling remains critical, architectural complexities such as wide diffusion heads and noise-augmented decoding offer negligible benefits at scale Building on this simplified framework, we conduct a controlled comparison of RAE against the state-of-the-art FLUX VAE across diffusion transformer scales from 0.5B to 9.8B parameters. RAEs consistently outperform VAEs during pretraining across all model scales. Further, during finetuning on high-quality datasets, VAE-based models catastrophically overfit after 64 epochs, while RAE models remain stable through 256 epochs and achieve consistently better performance. Across all experiments, RAE-based diffusion models demonstrate faster convergence and better generation quality, establishing RAEs as a simpler and stronger foundation than VAEs for large-scale T2I generation. Additionally, because both visual understanding and generation can operate in a shared representation space, the multimodal model can directly reason over generated latents, opening new possibilities for unified models.
Cambrian-S: Towards Spatial Supersensing in Video
Nov 06, 2025We argue that progress in true multimodal intelligence calls for a shift from reactive, task-driven systems and brute-force long context towards a broader paradigm of supersensing. We frame spatial supersensing as four stages beyond linguistic-only understanding: semantic perception (naming what is seen), streaming event cognition (maintaining memory across continuous experiences), implicit 3D spatial cognition (inferring the world behind pixels), and predictive world modeling (creating internal models that filter and organize information). Current benchmarks largely test only the early stages, offering narrow coverage of spatial cognition and rarely challenging models in ways that require true world modeling. To drive progress in spatial supersensing, we present VSI-SUPER, a two-part benchmark: VSR (long-horizon visual spatial recall) and VSC (continual visual spatial counting). These tasks require arbitrarily long video inputs yet are resistant to brute-force context expansion. We then test data scaling limits by curating VSI-590K and training Cambrian-S, achieving +30% absolute improvement on VSI-Bench without sacrificing general capabilities. Yet performance on VSI-SUPER remains limited, indicating that scale alone is insufficient for spatial supersensing. We propose predictive sensing as a path forward, presenting a proof-of-concept in which a self-supervised next-latent-frame predictor leverages surprise (prediction error) to drive memory and event segmentation. On VSI-SUPER, this approach substantially outperforms leading proprietary baselines, showing that spatial supersensing requires models that not only see but also anticipate, select, and organize experience.
Benchmark Designers Should "Train on the Test Set" to Expose Exploitable Non-Visual Shortcuts
Nov 06, 2025Robust benchmarks are crucial for evaluating Multimodal Large Language Models (MLLMs). Yet we find that models can ace many multimodal benchmarks without strong visual understanding, instead exploiting biases, linguistic priors, and superficial patterns. This is especially problematic for vision-centric benchmarks that are meant to require visual inputs. We adopt a diagnostic principle for benchmark design: if a benchmark can be gamed, it will be. Designers should therefore try to ``game'' their own benchmarks first, using diagnostic and debiasing procedures to systematically identify and mitigate non-visual biases. Effective diagnosis requires directly ``training on the test set'' -- probing the released test set for its intrinsic, exploitable patterns. We operationalize this standard with two components. First, we diagnose benchmark susceptibility using a ``Test-set Stress-Test'' (TsT) methodology. Our primary diagnostic tool involves fine-tuning a powerful Large Language Model via $k$-fold cross-validation on exclusively the non-visual, textual inputs of the test set to reveal shortcut performance and assign each sample a bias score $s(x)$. We complement this with a lightweight Random Forest-based diagnostic operating on hand-crafted features for fast, interpretable auditing. Second, we debias benchmarks by filtering high-bias samples using an ``Iterative Bias Pruning'' (IBP) procedure. Applying this framework to four benchmarks -- VSI-Bench, CV-Bench, MMMU, and VideoMME -- we uncover pervasive non-visual biases. As a case study, we apply our full framework to create VSI-Bench-Debiased, demonstrating reduced non-visual solvability and a wider vision-blind performance gap than the original.
Traveling Across Languages: Benchmarking Cross-Lingual Consistency in Multimodal LLMs
May 21, 2025



The rapid evolution of multimodal large language models (MLLMs) has significantly enhanced their real-world applications. However, achieving consistent performance across languages, especially when integrating cultural knowledge, remains a significant challenge. To better assess this issue, we introduce two new benchmarks: KnowRecall and VisRecall, which evaluate cross-lingual consistency in MLLMs. KnowRecall is a visual question answering benchmark designed to measure factual knowledge consistency in 15 languages, focusing on cultural and historical questions about global landmarks. VisRecall assesses visual memory consistency by asking models to describe landmark appearances in 9 languages without access to images. Experimental results reveal that state-of-the-art MLLMs, including proprietary ones, still struggle to achieve cross-lingual consistency. This underscores the need for more robust approaches that produce truly multilingual and culturally aware models.
UniTok: A Unified Tokenizer for Visual Generation and Understanding
Feb 27, 2025



The representation disparity between visual generation and understanding imposes a critical gap in integrating these capabilities into a single framework. To bridge this gap, we introduce UniTok, a discrete visual tokenizer that encodes fine-grained details for generation while also capturing high-level semantics for understanding. Despite recent studies have shown that these objectives could induce loss conflicts in training, we reveal that the underlying bottleneck stems from limited representational capacity of discrete tokens. We address this by introducing multi-codebook quantization, which divides vector quantization with several independent sub-codebooks to expand the latent feature space, while avoiding training instability caused by overlarge codebooks. Our method significantly raises the upper limit of unified discrete tokenizers to match or even surpass domain-specific continuous tokenizers. For instance, UniTok achieves a remarkable rFID of 0.38 (versus 0.87 for SD-VAE) and a zero-shot accuracy of 78.6% (versus 76.2% for CLIP) on ImageNet. Our code is available at https://github.com/FoundationVision/UniTok.
SFT Memorizes, RL Generalizes: A Comparative Study of Foundation Model Post-training
Jan 28, 2025



Supervised fine-tuning (SFT) and reinforcement learning (RL) are widely used post-training techniques for foundation models. However, their roles in enhancing model generalization capabilities remain unclear. This paper studies the difference between SFT and RL on generalization and memorization, focusing on text-based rule variants and visual variants. We introduce GeneralPoints, an arithmetic reasoning card game, and adopt V-IRL, a real-world navigation environment, to assess how models trained with SFT and RL generalize to unseen variants in both textual and visual domains. We show that RL, especially when trained with an outcome-based reward, generalizes across both rule-based textual and visual variants. SFT, in contrast, tends to memorize training data and struggles to generalize out-of-distribution scenarios. Further analysis reveals that RL improves the model's underlying visual recognition capabilities, contributing to its enhanced generalization in the visual domain. Despite RL's superior generalization, we show that SFT remains essential for effective RL training; SFT stabilizes the model's output format, enabling subsequent RL to achieve its performance gains. These findings demonstrates the capability of RL for acquiring generalizable knowledge in complex, multi-modal tasks.
Thinking in Space: How Multimodal Large Language Models See, Remember, and Recall Spaces
Dec 18, 2024



Humans possess the visual-spatial intelligence to remember spaces from sequential visual observations. However, can Multimodal Large Language Models (MLLMs) trained on million-scale video datasets also ``think in space'' from videos? We present a novel video-based visual-spatial intelligence benchmark (VSI-Bench) of over 5,000 question-answer pairs, and find that MLLMs exhibit competitive - though subhuman - visual-spatial intelligence. We probe models to express how they think in space both linguistically and visually and find that while spatial reasoning capabilities remain the primary bottleneck for MLLMs to reach higher benchmark performance, local world models and spatial awareness do emerge within these models. Notably, prevailing linguistic reasoning techniques (e.g., chain-of-thought, self-consistency, tree-of-thoughts) fail to improve performance, whereas explicitly generating cognitive maps during question-answering enhances MLLMs' spatial distance ability.
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs
Jun 24, 2024


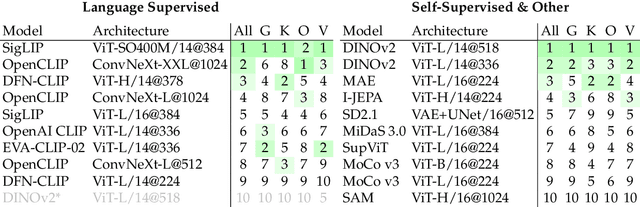
We introduce Cambrian-1, a family of multimodal LLMs (MLLMs) designed with a vision-centric approach. While stronger language models can enhance multimodal capabilities, the design choices for vision components are often insufficiently explored and disconnected from visual representation learning research. This gap hinders accurate sensory grounding in real-world scenarios. Our study uses LLMs and visual instruction tuning as an interface to evaluate various visual representations, offering new insights into different models and architectures -- self-supervised, strongly supervised, or combinations thereof -- based on experiments with over 20 vision encoders. We critically examine existing MLLM benchmarks, addressing the difficulties involved in consolidating and interpreting results from various tasks, and introduce a new vision-centric benchmark, CV-Bench. To further improve visual grounding, we propose the Spatial Vision Aggregator (SVA), a dynamic and spatially-aware connector that integrates high-resolution vision features with LLMs while reducing the number of tokens. Additionally, we discuss the curation of high-quality visual instruction-tuning data from publicly available sources, emphasizing the importance of data source balancing and distribution ratio. Collectively, Cambrian-1 not only achieves state-of-the-art performance but also serves as a comprehensive, open cookbook for instruction-tuned MLLMs. We provide model weights, code, supporting tools, datasets, and detailed instruction-tuning and evaluation recipes. We hope our release will inspire and accelerate advancements in multimodal systems and visual representation learning.