 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision Foundation Models as Generalist Tokenizers for Image Generation
May 18, 2026In this work, we explore the largely unexplored direction of building a generalist image tokenizer directly on top of a frozen vision foundation model (VFM). To build this tokenizer, we utilize a frozen VFM as the encoder and introduce two key innovations: (1) a region-adaptive quantization framework to eliminate spatial redundancy in standard 2D grid features, and (2) a semantic reconstruction objective that aligns the decoded outputs with the VFM's representations to preserve semantic fidelity. Grounded in these designs, we propose VFMTok, a generalist visual tokenizer capable of operating seamlessly in both discrete and continuous latent spaces. VFMTok achieves substantial improvements in synthesis quality while drastically enhancing token efficiency. For discrete autoregressive (AR) generation, it accelerates model convergence by \textbf{3 times} and achieves a state-of-the-art gFID of \textbf{1.36} on ImageNet class-conditional synthesis. Similarly, for continuous-space generation, integrating VFMTok with a denoising model yields an exceptional gFID of \textbf{1.25}. Furthermore, because the latent space inherently captures rich spatial semantics, VFMTok enables high-fidelity class-conditional synthesis without classifier-free guidance (\textbf{w/o CFG}) across both generative paradigms, significantly accelerating inference speed. Beyond these remarkable empirical results, we systematically investigate the underlying mechanisms of our approach. We discover that the specific self-supervised learning objectives utilized during VFM pre-training dictate its effectiveness as a tokenizer. Specifically, a VFM jointly optimized with global contrastive learning and latent masked image modeling provides the optimal representations for image tokenization. These insights establish a strong foundation and offer valuable guidance for the design of future image tokenizers.
Cubic Discrete Diffusion: Discrete Visual Generation on High-Dimensional Representation Tokens
Mar 19, 2026Visual generation with discrete tokens has gained significant attention as it enables a unified token prediction paradigm shared with language models, promising seamless multimodal architectures. However, current discrete generation methods remain limited to low-dimensional latent tokens (typically 8-32 dims), sacrificing the semantic richness essential for understanding. While high-dimensional pretrained representations (768-1024 dims) could bridge this gap, their discrete generation poses fundamental challenges. In this paper, we present Cubic Discrete Diffusion (CubiD), the first discrete generation model for high-dimensional representations. CubiD performs fine-grained masking throughout the high-dimensional discrete representation -- any dimension at any position can be masked and predicted from partial observations. This enables the model to learn rich correlations both within and across spatial positions, with the number of generation steps fixed at $T$ regardless of feature dimensionality, where $T \ll hwd$. On ImageNet-256, CubiD achieves state-of-the-art discrete generation with strong scaling behavior from 900M to 3.7B parameters. Crucially, we validate that these discretized tokens preserve original representation capabilities, demonstrating that the same discrete tokens can effectively serve both understanding and generation tasks. We hope this work will inspire future research toward unified multimodal architectures. Code is available at: https://github.com/YuqingWang1029/CubiD.
UniTok: A Unified Tokenizer for Visual Generation and Understanding
Feb 27, 2025



The representation disparity between visual generation and understanding imposes a critical gap in integrating these capabilities into a single framework. To bridge this gap, we introduce UniTok, a discrete visual tokenizer that encodes fine-grained details for generation while also capturing high-level semantics for understanding. Despite recent studies have shown that these objectives could induce loss conflicts in training, we reveal that the underlying bottleneck stems from limited representational capacity of discrete tokens. We address this by introducing multi-codebook quantization, which divides vector quantization with several independent sub-codebooks to expand the latent feature space, while avoiding training instability caused by overlarge codebooks. Our method significantly raises the upper limit of unified discrete tokenizers to match or even surpass domain-specific continuous tokenizers. For instance, UniTok achieves a remarkable rFID of 0.38 (versus 0.87 for SD-VAE) and a zero-shot accuracy of 78.6% (versus 76.2% for CLIP) on ImageNet. Our code is available at https://github.com/FoundationVision/UniTok.
Liquid: Language Models are Scalable Multi-modal Generators
Dec 05, 2024
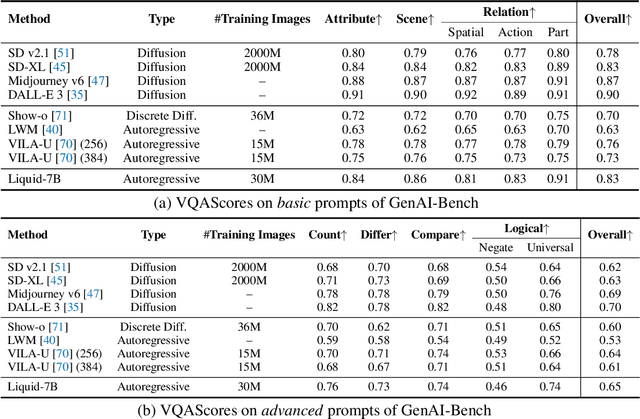

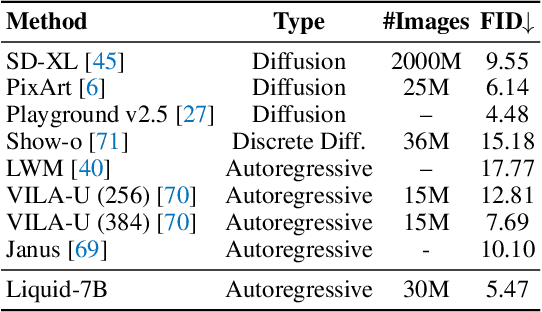
We present Liquid, an auto-regressive generation paradigm that seamlessly integrates visual comprehension and generation by tokenizing images into discrete codes and learning these code embeddings alongside text tokens within a shared feature space for both vision and language. Unlike previous multimodal large language model (MLLM), Liquid achieves this integration using a single large language model (LLM), eliminating the need for external pretrained visual embeddings such as CLIP. For the first time, Liquid uncovers a scaling law that performance drop unavoidably brought by the unified training of visual and language tasks diminishes as the model size increases. Furthermore, the unified token space enables visual generation and comprehension tasks to mutually enhance each other, effectively removing the typical interference seen in earlier models. We show that existing LLMs can serve as strong foundations for Liquid, saving 100x in training costs while outperforming Chameleon in multimodal capabilities and maintaining language performance comparable to mainstream LLMs like LLAMA2. Liquid also outperforms models like SD v2.1 and SD-XL (FID of 5.47 on MJHQ-30K), excelling in both vision-language and text-only tasks. This work demonstrates that LLMs such as LLAMA3.2 and GEMMA2 are powerful multimodal generators, offering a scalable solution for enhancing both vision-language understanding and generation. The code and models will be released.
Granularity Matters in Long-Tail Learning
Oct 21, 2024



Balancing training on long-tail data distributions remains a long-standing challenge in deep learning. While methods such as re-weighting and re-sampling help alleviate the imbalance issue, limited sample diversity continues to hinder models from learning robust and generalizable feature representations, particularly for tail classes. In contrast to existing methods, we offer a novel perspective on long-tail learning, inspired by an observation: datasets with finer granularity tend to be less affected by data imbalance. In this paper, we investigate this phenomenon through both quantitative and qualitative studies, showing that increased granularity enhances the generalization of learned features in tail categories. Motivated by these findings, we propose a method to increase dataset granularity through category extrapolation. Specifically, we introduce open-set auxiliary classes that are visually similar to existing ones, aiming to enhance representation learning for both head and tail classes. This forms the core contribution and insight of our approach. To automate the curation of auxiliary data, we leverage large language models (LLMs) as knowledge bases to search for auxiliary categories and retrieve relevant images through web crawling. To prevent the overwhelming presence of auxiliary classes from disrupting training, we introduce a neighbor-silencing loss that encourages the model to focus on class discrimination within the target dataset. During inference, the classifier weights for auxiliary categories are masked out, leaving only the target class weights for use. Extensive experiments and ablation studies on three standard long-tail benchmarks demonstrate the effectiveness of our approach, notably outperforming strong baseline methods that use the same amount of data. The code will be made publicly available.
Groma: Localized Visual Tokenization for Grounding Multimodal Large Language Models
Apr 19, 2024We introduce Groma, a Multimodal Large Language Model (MLLM) with grounded and fine-grained visual perception ability. Beyond holistic image understanding, Groma is adept at region-level tasks such as region captioning and visual grounding. Such capabilities are built upon a localized visual tokenization mechanism, where an image input is decomposed into regions of interest and subsequently encoded into region tokens. By integrating region tokens into user instructions and model responses, we seamlessly enable Groma to understand user-specified region inputs and ground its textual output to images. Besides, to enhance the grounded chat ability of Groma, we curate a visually grounded instruction dataset by leveraging the powerful GPT-4V and visual prompting techniques. Compared with MLLMs that rely on the language model or external module for localization, Groma consistently demonstrates superior performances in standard referring and grounding benchmarks, highlighting the advantages of embedding localization into image tokenization. Project page: https://groma-mllm.github.io/.
Recognize Any Regions
Nov 02, 2023Understanding the semantics of individual regions or patches within unconstrained images, such as in open-world object detection, represents a critical yet challenging task in computer vision. Building on the success of powerful image-level vision-language (ViL) foundation models like CLIP, recent efforts have sought to harness their capabilities by either training a contrastive model from scratch with an extensive collection of region-label pairs or aligning the outputs of a detection model with image-level representations of region proposals. Despite notable progress, these approaches are plagued by computationally intensive training requirements, susceptibility to data noise, and deficiency in contextual information. To address these limitations, we explore the synergistic potential of off-the-shelf foundation models, leveraging their respective strengths in localization and semantics. We introduce a novel, generic, and efficient region recognition architecture, named RegionSpot, designed to integrate position-aware localization knowledge from a localization foundation model (e.g., SAM) with semantic information extracted from a ViL model (e.g., CLIP). To fully exploit pretrained knowledge while minimizing training overhead, we keep both foundation models frozen, focusing optimization efforts solely on a lightweight attention-based knowledge integration module. Through extensive experiments in the context of open-world object recognition, our RegionSpot demonstrates significant performance improvements over prior alternatives, while also providing substantial computational savings. For instance, training our model with 3 million data in a single day using 8 V100 GPUs. Our model outperforms GLIP by 6.5 % in mean average precision (mAP), with an even larger margin by 14.8 % for more challenging and rare categories.
CoDet: Co-Occurrence Guided Region-Word Alignment for Open-Vocabulary Object Detection
Oct 25, 2023
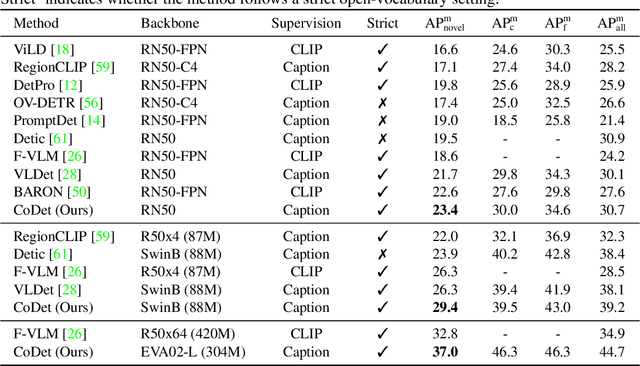
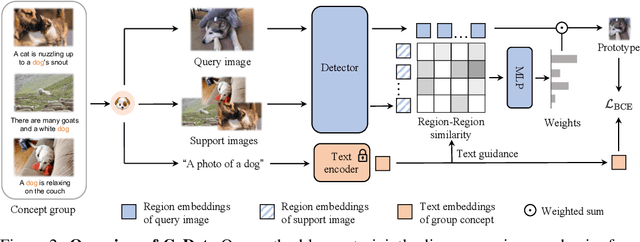
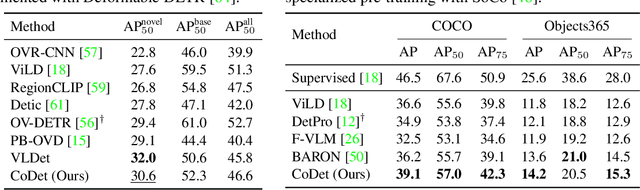
Deriving reliable region-word alignment from image-text pairs is critical to learn object-level vision-language representations for open-vocabulary object detection. Existing methods typically rely on pre-trained or self-trained vision-language models for alignment, which are prone to limitations in localization accuracy or generalization capabilities. In this paper, we propose CoDet, a novel approach that overcomes the reliance on pre-aligned vision-language space by reformulating region-word alignment as a co-occurring object discovery problem. Intuitively, by grouping images that mention a shared concept in their captions, objects corresponding to the shared concept shall exhibit high co-occurrence among the group. CoDet then leverages visual similarities to discover the co-occurring objects and align them with the shared concept. Extensive experiments demonstrate that CoDet has superior performances and compelling scalability in open-vocabulary detection, e.g., by scaling up the visual backbone, CoDet achieves 37.0 $\text{AP}^m_{novel}$ and 44.7 $\text{AP}^m_{all}$ on OV-LVIS, surpassing the previous SoTA by 4.2 $\text{AP}^m_{novel}$ and 9.8 $\text{AP}^m_{all}$. Code is available at https://github.com/CVMI-Lab/CoDet.
EGC: Image Generation and Classification via a Diffusion Energy-Based Model
Apr 13, 2023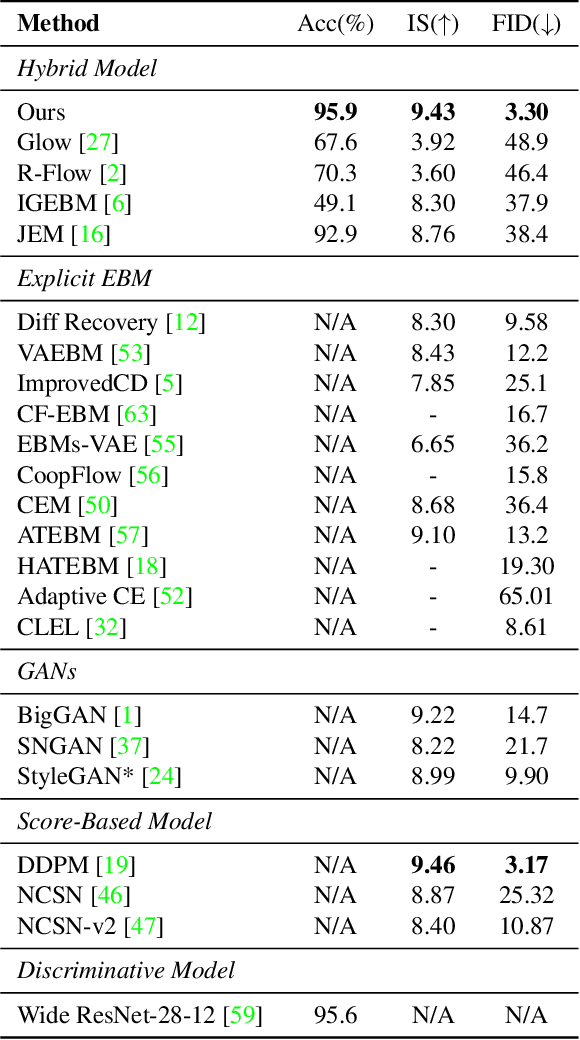



Learning image classification and image generation using the same set of network parameters is a challenging problem. Recent advanced approaches perform well in one task often exhibit poor performance in the other. This work introduces an energy-based classifier and generator, namely EGC, which can achieve superior performance in both tasks using a single neural network. Unlike a conventional classifier that outputs a label given an image (i.e., a conditional distribution $p(y|\mathbf{x})$), the forward pass in EGC is a classifier that outputs a joint distribution $p(\mathbf{x},y)$, enabling an image generator in its backward pass by marginalizing out the label $y$. This is done by estimating the energy and classification probability given a noisy image in the forward pass, while denoising it using the score function estimated in the backward pass. EGC achieves competitive generation results compared with state-of-the-art approaches on ImageNet-1k, CelebA-HQ and LSUN Church, while achieving superior classification accuracy and robustness against adversarial attacks on CIFAR-10. This work represents the first successful attempt to simultaneously excel in both tasks using a single set of network parameters. We believe that EGC bridges the gap between discriminative and generative learning.
Rethinking Resolution in the Context of Efficient Video Recognition
Sep 26, 2022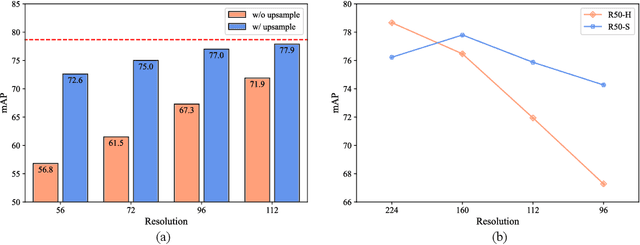
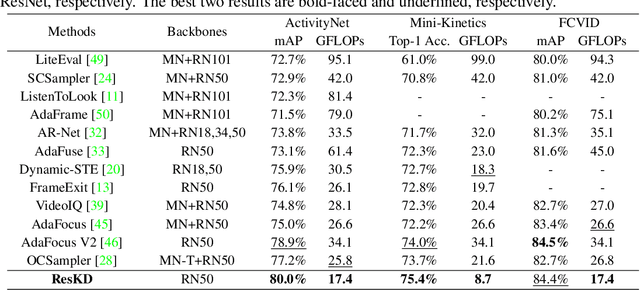
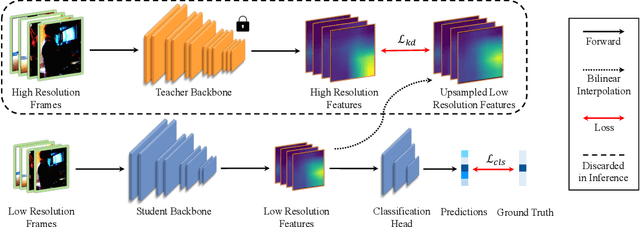
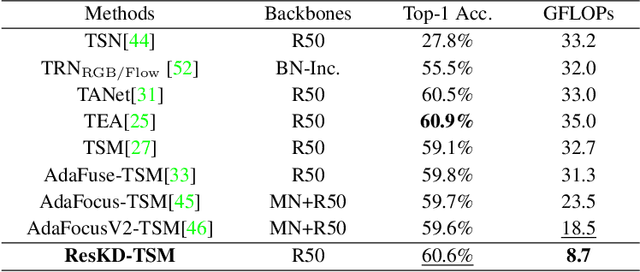
In this paper, we empirically study how to make the most of low-resolution frames for efficient video recognition. Existing methods mainly focus on developing compact networks or alleviating temporal redundancy of video inputs to increase efficiency, whereas compressing frame resolution has rarely been considered a promising solution. A major concern is the poor recognition accuracy on low-resolution frames. We thus start by analyzing the underlying causes of performance degradation on low-resolution frames. Our key finding is that the major cause of degradation is not information loss in the down-sampling process, but rather the mismatch between network architecture and input scale. Motivated by the success of knowledge distillation (KD), we propose to bridge the gap between network and input size via cross-resolution KD (ResKD). Our work shows that ResKD is a simple but effective method to boost recognition accuracy on low-resolution frames. Without bells and whistles, ResKD considerably surpasses all competitive methods in terms of efficiency and accuracy on four large-scale benchmark datasets, i.e., ActivityNet, FCVID, Mini-Kinetics, Something-Something V2. In addition, we extensively demonstrate its effectiveness over state-of-the-art architectures, i.e., 3D-CNNs and Video Transformers, and scalability towards super low-resolution frames. The results suggest ResKD can serve as a general inference acceleration method for state-of-the-art video recognition. Our code will be available at https://github.com/CVMI-Lab/ResKD.