 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAIR: Cost-Efficient Multi-Stage ML Pipeline Autoscaling via In-Context Reinforcement Learning
Jan 29, 2026Multi-stage ML inference pipelines are difficult to autoscale due to heterogeneous resources, cross-stage coupling, and dynamic bottleneck migration. We present SAIR, an autoscaling framework that uses an LLM as an in-context reinforcement learning controller, improving its policy online from reward-labeled interaction histories without gradient updates. SAIR combines Pareto-dominance reward shaping with a provable separation margin, surprisal-guided experience retrieval for context efficiency, and fine-grained GPU rate control via user-space CUDA interception. We provide regret analysis decomposing error into retrieval coverage and LLM selection components. On four ML serving pipelines under three workload patterns, SAIR achieves the best or tied-best P99 latency and effective resource cost among deployed baselines, improving P99 by up to 50% and reducing effective cost by up to 97% (under GPU rate-control assumptions), with 86% bottleneck detection accuracy and no offline training.
ASSIST-3D: Adapted Scene Synthesis for Class-Agnostic 3D Instance Segmentation
Dec 10, 2025Class-agnostic 3D instance segmentation tackles the challenging task of segmenting all object instances, including previously unseen ones, without semantic class reliance. Current methods struggle with generalization due to the scarce annotated 3D scene data or noisy 2D segmentations. While synthetic data generation offers a promising solution, existing 3D scene synthesis methods fail to simultaneously satisfy geometry diversity, context complexity, and layout reasonability, each essential for this task. To address these needs, we propose an Adapted 3D Scene Synthesis pipeline for class-agnostic 3D Instance SegmenTation, termed as ASSIST-3D, to synthesize proper data for model generalization enhancement. Specifically, ASSIST-3D features three key innovations, including 1) Heterogeneous Object Selection from extensive 3D CAD asset collections, incorporating randomness in object sampling to maximize geometric and contextual diversity; 2) Scene Layout Generation through LLM-guided spatial reasoning combined with depth-first search for reasonable object placements; and 3) Realistic Point Cloud Construction via multi-view RGB-D image rendering and fusion from the synthetic scenes, closely mimicking real-world sensor data acquisition. Experiments on ScanNetV2, ScanNet++, and S3DIS benchmarks demonstrate that models trained with ASSIST-3D-generated data significantly outperform existing methods. Further comparisons underscore the superiority of our purpose-built pipeline over existing 3D scene synthesis approaches.
Aligning Effective Tokens with Video Anomaly in Large Language Models
Aug 08, 2025Understanding abnormal events in videos is a vital and challenging task that has garnered significant attention in a wide range of applications. Although current video understanding Multi-modal Large Language Models (MLLMs) are capable of analyzing general videos, they often struggle to handle anomalies due to the spatial and temporal sparsity of abnormal events, where the redundant information always leads to suboptimal outcomes. To address these challenges, exploiting the representation and generalization capabilities of Vison Language Models (VLMs) and Large Language Models (LLMs), we propose VA-GPT, a novel MLLM designed for summarizing and localizing abnormal events in various videos. Our approach efficiently aligns effective tokens between visual encoders and LLMs through two key proposed modules: Spatial Effective Token Selection (SETS) and Temporal Effective Token Generation (TETG). These modules enable our model to effectively capture and analyze both spatial and temporal information associated with abnormal events, resulting in more accurate responses and interactions. Furthermore, we construct an instruction-following dataset specifically for fine-tuning video-anomaly-aware MLLMs, and introduce a cross-domain evaluation benchmark based on XD-Violence dataset. Our proposed method outperforms existing state-of-the-art methods on various benchmarks.
Granularity Matters in Long-Tail Learning
Oct 21, 2024



Balancing training on long-tail data distributions remains a long-standing challenge in deep learning. While methods such as re-weighting and re-sampling help alleviate the imbalance issue, limited sample diversity continues to hinder models from learning robust and generalizable feature representations, particularly for tail classes. In contrast to existing methods, we offer a novel perspective on long-tail learning, inspired by an observation: datasets with finer granularity tend to be less affected by data imbalance. In this paper, we investigate this phenomenon through both quantitative and qualitative studies, showing that increased granularity enhances the generalization of learned features in tail categories. Motivated by these findings, we propose a method to increase dataset granularity through category extrapolation. Specifically, we introduce open-set auxiliary classes that are visually similar to existing ones, aiming to enhance representation learning for both head and tail classes. This forms the core contribution and insight of our approach. To automate the curation of auxiliary data, we leverage large language models (LLMs) as knowledge bases to search for auxiliary categories and retrieve relevant images through web crawling. To prevent the overwhelming presence of auxiliary classes from disrupting training, we introduce a neighbor-silencing loss that encourages the model to focus on class discrimination within the target dataset. During inference, the classifier weights for auxiliary categories are masked out, leaving only the target class weights for use. Extensive experiments and ablation studies on three standard long-tail benchmarks demonstrate the effectiveness of our approach, notably outperforming strong baseline methods that use the same amount of data. The code will be made publicly available.
Can OOD Object Detectors Learn from Foundation Models?
Sep 08, 2024



Out-of-distribution (OOD) object detection is a challenging task due to the absence of open-set OOD data. Inspired by recent advancements in text-to-image generative models, such as Stable Diffusion, we study the potential of generative models trained on large-scale open-set data to synthesize OOD samples, thereby enhancing OOD object detection. We introduce SyncOOD, a simple data curation method that capitalizes on the capabilities of large foundation models to automatically extract meaningful OOD data from text-to-image generative models. This offers the model access to open-world knowledge encapsulated within off-the-shelf foundation models. The synthetic OOD samples are then employed to augment the training of a lightweight, plug-and-play OOD detector, thus effectively optimizing the in-distribution (ID)/OOD decision boundaries. Extensive experiments across multiple benchmarks demonstrate that SyncOOD significantly outperforms existing methods, establishing new state-of-the-art performance with minimal synthetic data usage.
* 19 pages, 4 figures
Prototypical VoteNet for Few-Shot 3D Point Cloud Object Detection
Oct 11, 2022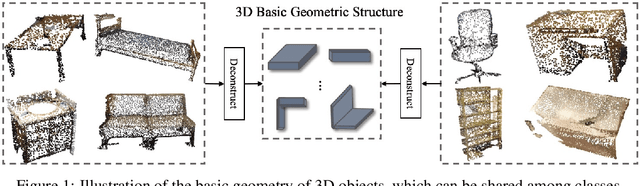
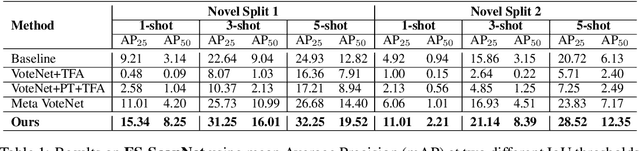
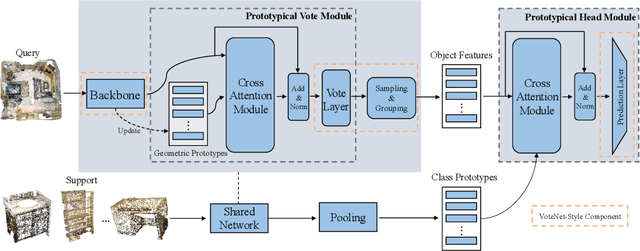
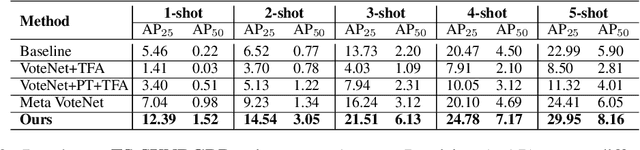
Most existing 3D point cloud object detection approaches heavily rely on large amounts of labeled training data. However, the labeling process is costly and time-consuming. This paper considers few-shot 3D point cloud object detection, where only a few annotated samples of novel classes are needed with abundant samples of base classes. To this end, we propose Prototypical VoteNet to recognize and localize novel instances, which incorporates two new modules: Prototypical Vote Module (PVM) and Prototypical Head Module (PHM). Specifically, as the 3D basic geometric structures can be shared among categories, PVM is designed to leverage class-agnostic geometric prototypes, which are learned from base classes, to refine local features of novel categories.Then PHM is proposed to utilize class prototypes to enhance the global feature of each object, facilitating subsequent object localization and classification, which is trained by the episodic training strategy. To evaluate the model in this new setting, we contribute two new benchmark datasets, FS-ScanNet and FS-SUNRGBD. We conduct extensive experiments to demonstrate the effectiveness of Prototypical VoteNet, and our proposed method shows significant and consistent improvements compared to baselines on two benchmark datasets.
Devil's in the Detail: Graph-based Key-point Alignment and Embedding for Person Re-ID
Sep 11, 2020

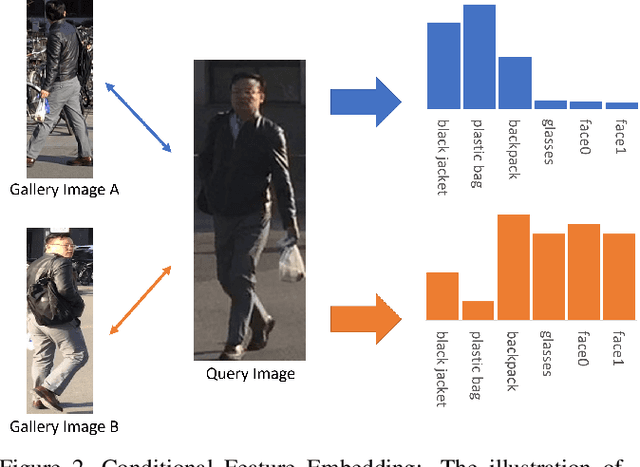
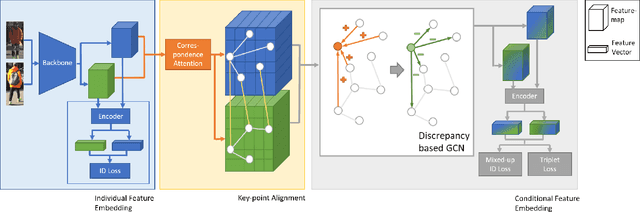
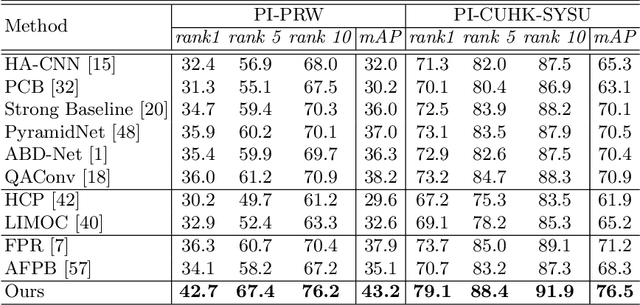
Although Person Re-Identification has made impressive progress, difficult cases like occlusion, change of view-point and similar clothing still bring great challenges. Besides overall visual features, matching and comparing detailed local information is also essential for tackling these challenges. This paper proposes two key recognition patterns to better utilize the local information of pedestrian images. From the spatial perspective, the model should be able to select and align key-points from the image pairs for comparison (i.e. key-points alignment). From the perspective of feature channels, the feature of a query image should be dynamically adjusted based on the gallery image it needs to match (i.e. conditional feature embedding). Most of the existing methods are unable to satisfy both key-point alignment and conditional feature embedding. By introducing novel techniques including correspondence attention module and discrepancy-based GCN, we propose an end-to-end ReID method that integrates both patterns into a unified framework, called Siamese-GCN. The experiments show that Siamese-GCN achieves state-of-the-art performance on three public datasets.
Do Not Disturb Me: Person Re-identification Under the Interference of Other Pedestrians
Aug 16, 2020
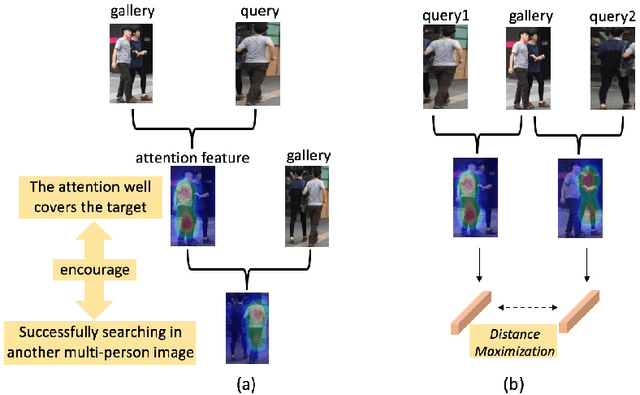
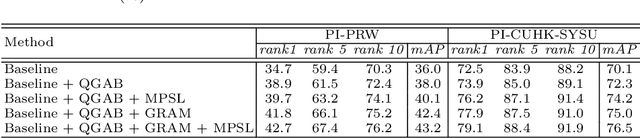
In the conventional person Re-ID setting, it is widely assumed that cropped person images are for each individual. However, in a crowded scene, off-shelf-detectors may generate bounding boxes involving multiple people, where the large proportion of background pedestrians or human occlusion exists. The representation extracted from such cropped images, which contain both the target and the interference pedestrians, might include distractive information. This will lead to wrong retrieval results. To address this problem, this paper presents a novel deep network termed Pedestrian-Interference Suppression Network (PISNet). PISNet leverages a Query-Guided Attention Block (QGAB) to enhance the feature of the target in the gallery, under the guidance of the query. Furthermore, the involving Guidance Reversed Attention Module and the Multi-Person Separation Loss promote QGAB to suppress the interference of other pedestrians. Our method is evaluated on two new pedestrian-interference datasets and the results show that the proposed method performs favorably against existing Re-ID methods.
GTNet: Generative Transfer Network for Zero-Shot Object Detection
Jan 24, 2020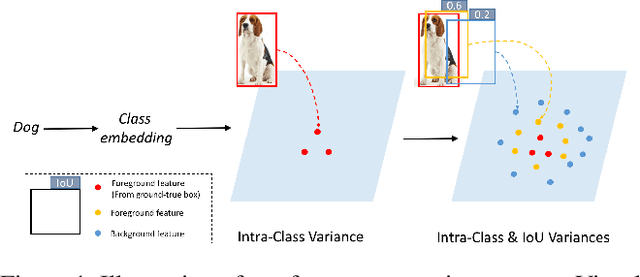
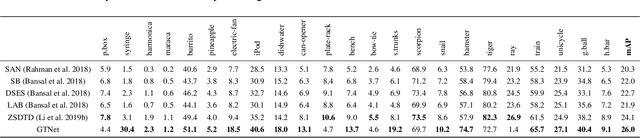
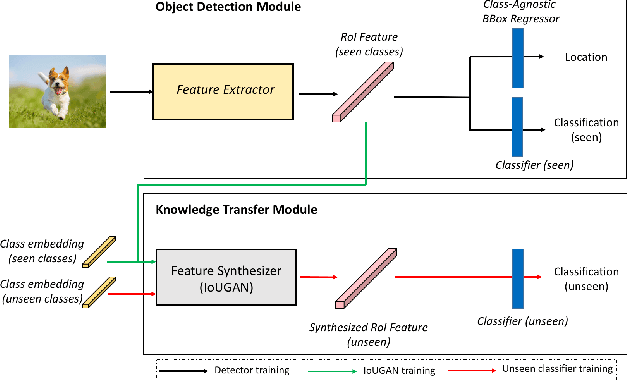
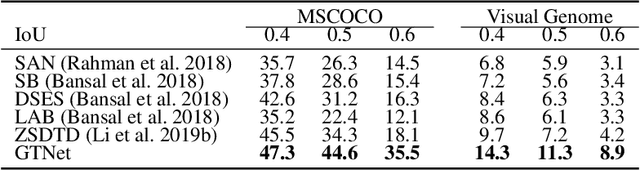
We propose a Generative Transfer Network (GTNet) for zero shot object detection (ZSD). GTNet consists of an Object Detection Module and a Knowledge Transfer Module. The Object Detection Module can learn large-scale seen domain knowledge. The Knowledge Transfer Module leverages a feature synthesizer to generate unseen class features, which are applied to train a new classification layer for the Object Detection Module. In order to synthesize features for each unseen class with both the intra-class variance and the IoU variance, we design an IoU-Aware Generative Adversarial Network (IoUGAN) as the feature synthesizer, which can be easily integrated into GTNet. Specifically, IoUGAN consists of three unit models: Class Feature Generating Unit (CFU), Foreground Feature Generating Unit (FFU), and Background Feature Generating Unit (BFU). CFU generates unseen features with the intra-class variance conditioned on the class semantic embeddings. FFU and BFU add the IoU variance to the results of CFU, yielding class-specific foreground and background features, respectively. We evaluate our method on three public datasets and the results demonstrate that our method performs favorably against the state-of-the-art ZSD approaches.