 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to See through Illumination Extremes with Event Streaming in Multimodal Large Language Models
Mar 29, 2026Multimodal Large Language Models (MLLMs) perform strong vision-language reasoning under standard conditions but fail in extreme illumination, where RGB inputs lose irrevocable structure and semantics. We propose Event-MLLM, an event-enhanced model that performs all-light visual reasoning by dynamically fusing event streams with RGB frames. Two key components drive our approach: an Illumination Indicator - a learnable signal derived from a DINOv2 branch that represents exposure degradation and adaptively modulates event-RGB fusion - and an Illumination Correction Loss that aligns fused features with non-degraded (normal-light) semantics in the latent space, compensating for information lost in extreme lighting. We curate the first multi-illumination event-instruction corpus for MLLMs, with 2,241 event-RGB samples (around 6 QA pairs each) across diverse scenes and 17 brightness rates (0.05x - 20x), plus an instruct-following benchmark for reasoning, counting, and fine-grained recognition under extreme lighting. Experiments show that Event-MLLM markedly outperforms general-purpose, illumination-adaptive, and event-only baselines, setting a new state of the art in robust multimodal perception and reasoning under challenging illumination.
Aligning Effective Tokens with Video Anomaly in Large Language Models
Aug 08, 2025Understanding abnormal events in videos is a vital and challenging task that has garnered significant attention in a wide range of applications. Although current video understanding Multi-modal Large Language Models (MLLMs) are capable of analyzing general videos, they often struggle to handle anomalies due to the spatial and temporal sparsity of abnormal events, where the redundant information always leads to suboptimal outcomes. To address these challenges, exploiting the representation and generalization capabilities of Vison Language Models (VLMs) and Large Language Models (LLMs), we propose VA-GPT, a novel MLLM designed for summarizing and localizing abnormal events in various videos. Our approach efficiently aligns effective tokens between visual encoders and LLMs through two key proposed modules: Spatial Effective Token Selection (SETS) and Temporal Effective Token Generation (TETG). These modules enable our model to effectively capture and analyze both spatial and temporal information associated with abnormal events, resulting in more accurate responses and interactions. Furthermore, we construct an instruction-following dataset specifically for fine-tuning video-anomaly-aware MLLMs, and introduce a cross-domain evaluation benchmark based on XD-Violence dataset. Our proposed method outperforms existing state-of-the-art methods on various benchmarks.
Can OOD Object Detectors Learn from Foundation Models?
Sep 08, 2024



Out-of-distribution (OOD) object detection is a challenging task due to the absence of open-set OOD data. Inspired by recent advancements in text-to-image generative models, such as Stable Diffusion, we study the potential of generative models trained on large-scale open-set data to synthesize OOD samples, thereby enhancing OOD object detection. We introduce SyncOOD, a simple data curation method that capitalizes on the capabilities of large foundation models to automatically extract meaningful OOD data from text-to-image generative models. This offers the model access to open-world knowledge encapsulated within off-the-shelf foundation models. The synthetic OOD samples are then employed to augment the training of a lightweight, plug-and-play OOD detector, thus effectively optimizing the in-distribution (ID)/OOD decision boundaries. Extensive experiments across multiple benchmarks demonstrate that SyncOOD significantly outperforms existing methods, establishing new state-of-the-art performance with minimal synthetic data usage.
* 19 pages, 4 figures
Detection of Children Abuse by Voice and Audio Classification by Short-Time Fourier Transform Machine Learning implemented on Nvidia Edge GPU device
Jul 27, 2023
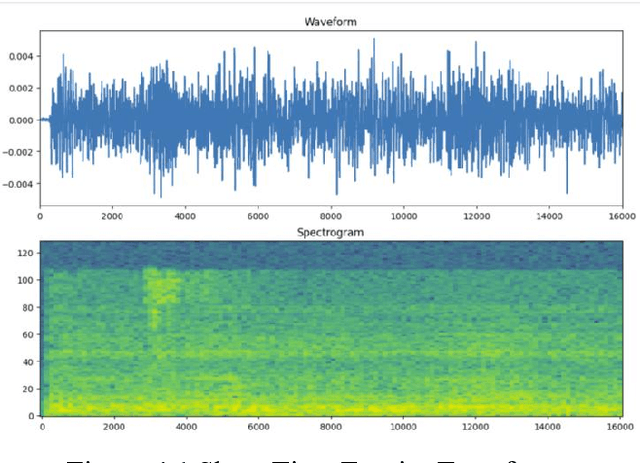
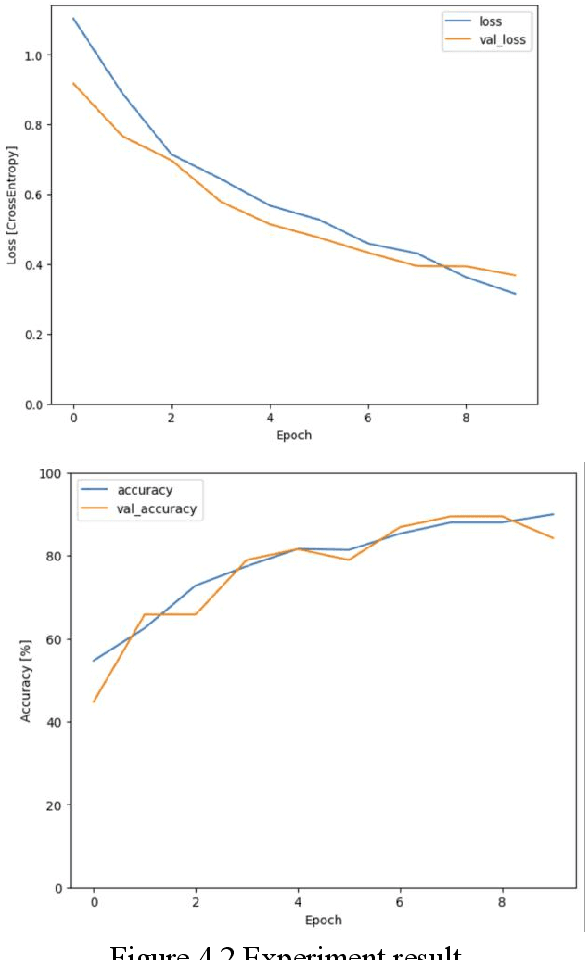
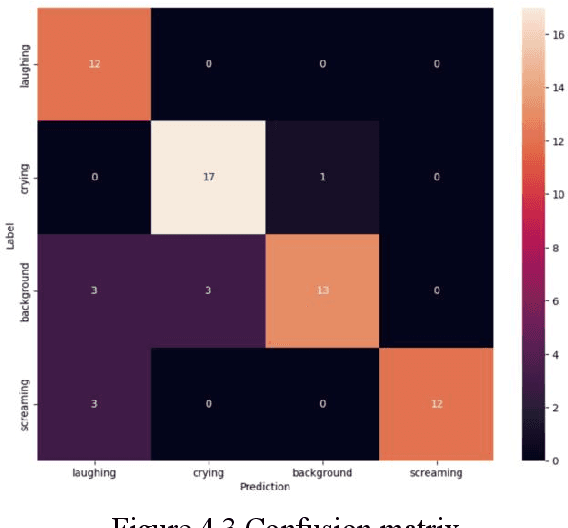
The safety of children in children home has become an increasing social concern, and the purpose of this experiment is to use machine learning applied to detect the scenarios of child abuse to increase the safety of children. This experiment uses machine learning to classify and recognize a child's voice and predict whether the current sound made by the child is crying, screaming or laughing. If a child is found to be crying or screaming, an alert is immediately sent to the relevant personnel so that they can perceive what the child may be experiencing in a surveillance blind spot and respond in a timely manner. Together with a hybrid use of video image classification, the accuracy of child abuse detection can be significantly increased. This greatly reduces the likelihood that a child will receive violent abuse in the nursery and allows personnel to stop an imminent or incipient child abuse incident in time. The datasets collected from this experiment is entirely from sounds recorded on site at the children home, including crying, laughing, screaming sound and background noises. These sound files are transformed into spectrograms using Short-Time Fourier Transform, and then these image data are imported into a CNN neural network for classification, and the final trained model can achieve an accuracy of about 92% for sound detection.
Communication Resources Constrained Hierarchical Federated Learning for End-to-End Autonomous Driving
Jun 28, 2023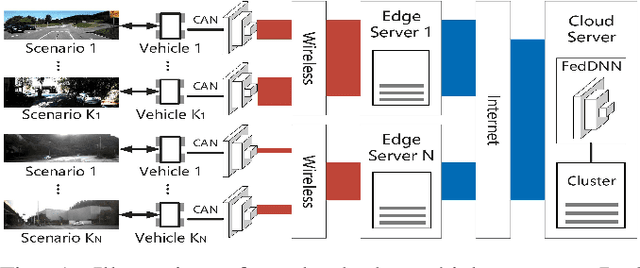
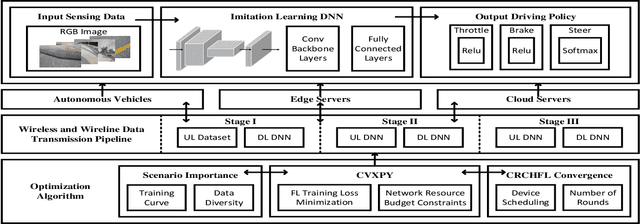
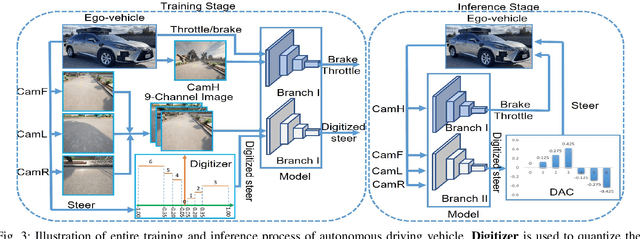

While federated learning (FL) improves the generalization of end-to-end autonomous driving by model aggregation, the conventional single-hop FL (SFL) suffers from slow convergence rate due to long-range communications among vehicles and cloud server. Hierarchical federated learning (HFL) overcomes such drawbacks via introduction of mid-point edge servers. However, the orchestration between constrained communication resources and HFL performance becomes an urgent problem. This paper proposes an optimization-based Communication Resource Constrained Hierarchical Federated Learning (CRCHFL) framework to minimize the generalization error of the autonomous driving model using hybrid data and model aggregation. The effectiveness of the proposed CRCHFL is evaluated in the Car Learning to Act (CARLA) simulation platform. Results show that the proposed CRCHFL both accelerates the convergence rate and enhances the generalization of federated learning autonomous driving model. Moreover, under the same communication resource budget, it outperforms the HFL by 10.33% and the SFL by 12.44%.
MGFN: Magnitude-Contrastive Glance-and-Focus Network for Weakly-Supervised Video Anomaly Detection
Nov 28, 2022



Weakly supervised detection of anomalies in surveillance videos is a challenging task. Going beyond existing works that have deficient capabilities to localize anomalies in long videos, we propose a novel glance and focus network to effectively integrate spatial-temporal information for accurate anomaly detection. In addition, we empirically found that existing approaches that use feature magnitudes to represent the degree of anomalies typically ignore the effects of scene variations, and hence result in sub-optimal performance due to the inconsistency of feature magnitudes across scenes. To address this issue, we propose the Feature Amplification Mechanism and a Magnitude Contrastive Loss to enhance the discriminativeness of feature magnitudes for detecting anomalies. Experimental results on two large-scale benchmarks UCF-Crime and XD-Violence manifest that our method outperforms state-of-the-art approaches.