 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTouchGuide: Inference-Time Steering of Visuomotor Policies via Touch Guidance
Jan 28, 2026Fine-grained and contact-rich manipulation remain challenging for robots, largely due to the underutilization of tactile feedback. To address this, we introduce TouchGuide, a novel cross-policy visuo-tactile fusion paradigm that fuses modalities within a low-dimensional action space. Specifically, TouchGuide operates in two stages to guide a pre-trained diffusion or flow-matching visuomotor policy at inference time. First, the policy produces a coarse, visually-plausible action using only visual inputs during early sampling. Second, a task-specific Contact Physical Model (CPM) provides tactile guidance to steer and refine the action, ensuring it aligns with realistic physical contact conditions. Trained through contrastive learning on limited expert demonstrations, the CPM provides a tactile-informed feasibility score to steer the sampling process toward refined actions that satisfy physical contact constraints. Furthermore, to facilitate TouchGuide training with high-quality and cost-effective data, we introduce TacUMI, a data collection system. TacUMI achieves a favorable trade-off between precision and affordability; by leveraging rigid fingertips, it obtains direct tactile feedback, thereby enabling the collection of reliable tactile data. Extensive experiments on five challenging contact-rich tasks, such as shoe lacing and chip handover, show that TouchGuide consistently and significantly outperforms state-of-the-art visuo-tactile policies.
A Trajectory-free Crash Detection Framework with Generative Approach and Segment Map Diffusion
Nov 17, 2025Real-time crash detection is essential for developing proactive safety management strategy and enhancing overall traffic efficiency. To address the limitations associated with trajectory acquisition and vehicle tracking, road segment maps recording the individual-level traffic dynamic data were directly served in crash detection. A novel two-stage trajectory-free crash detection framework, was present to generate the rational future road segment map and identify crashes. The first-stage diffusion-based segment map generation model, Mapfusion, conducts a noisy-to-normal process that progressively adds noise to the road segment map until the map is corrupted to pure Gaussian noise. The denoising process is guided by sequential embedding components capturing the temporal dynamics of segment map sequences. Furthermore, the generation model is designed to incorporate background context through ControlNet to enhance generation control. Crash detection is achieved by comparing the monitored segment map with the generations from diffusion model in second stage. Trained on non-crash vehicle motion data, Mapfusion successfully generates realistic road segment evolution maps based on learned motion patterns and remains robust across different sampling intervals. Experiments on real-world crashes indicate the effectiveness of the proposed two-stage method in accurately detecting crashes.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
Angio-Diff: Learning a Self-Supervised Adversarial Diffusion Model for Angiographic Geometry Generation
Jun 24, 2025Vascular diseases pose a significant threat to human health, with X-ray angiography established as the gold standard for diagnosis, allowing for detailed observation of blood vessels. However, angiographic X-rays expose personnel and patients to higher radiation levels than non-angiographic X-rays, which are unwanted. Thus, modality translation from non-angiographic to angiographic X-rays is desirable. Data-driven deep approaches are hindered by the lack of paired large-scale X-ray angiography datasets. While making high-quality vascular angiography synthesis crucial, it remains challenging. We find that current medical image synthesis primarily operates at pixel level and struggles to adapt to the complex geometric structure of blood vessels, resulting in unsatisfactory quality of blood vessel image synthesis, such as disconnections or unnatural curvatures. To overcome this issue, we propose a self-supervised method via diffusion models to transform non-angiographic X-rays into angiographic X-rays, mitigating data shortages for data-driven approaches. Our model comprises a diffusion model that learns the distribution of vascular data from diffusion latent, a generator for vessel synthesis, and a mask-based adversarial module. To enhance geometric accuracy, we propose a parametric vascular model to fit the shape and distribution of blood vessels. The proposed method contributes a pipeline and a synthetic dataset for X-ray angiography. We conducted extensive comparative and ablation experiments to evaluate the Angio-Diff. The results demonstrate that our method achieves state-of-the-art performance in synthetic angiography image quality and more accurately synthesizes the geometric structure of blood vessels. The code is available at https://github.com/zfw-cv/AngioDiff.
TransDiffuser: End-to-end Trajectory Generation with Decorrelated Multi-modal Representation for Autonomous Driving
May 14, 2025In recent years, diffusion model has shown its potential across diverse domains from vision generation to language modeling. Transferring its capabilities to modern autonomous driving systems has also emerged as a promising direction.In this work, we propose TransDiffuser, an encoder-decoder based generative trajectory planning model for end-to-end autonomous driving. The encoded scene information serves as the multi-modal conditional input of the denoising decoder. To tackle the mode collapse dilemma in generating high-quality diverse trajectories, we introduce a simple yet effective multi-modal representation decorrelation optimization mechanism during the training process.TransDiffuser achieves PDMS of 94.85 on the NAVSIM benchmark, surpassing previous state-of-the-art methods without any anchor-based prior trajectories.
Comorbidity-Informed Transfer Learning for Neuro-developmental Disorder Diagnosis
Apr 13, 2025



Neuro-developmental disorders are manifested as dysfunctions in cognition, communication, behaviour and adaptability, and deep learning-based computer-aided diagnosis (CAD) can alleviate the increasingly strained healthcare resources on neuroimaging. However, neuroimaging such as fMRI contains complex spatio-temporal features, which makes the corresponding representations susceptible to a variety of distractions, thus leading to less effective in CAD. For the first time, we present a Comorbidity-Informed Transfer Learning(CITL) framework for diagnosing neuro-developmental disorders using fMRI. In CITL, a new reinforced representation generation network is proposed, which first combines transfer learning with pseudo-labelling to remove interfering patterns from the temporal domain of fMRI and generates new representations using encoder-decoder architecture. The new representations are then trained in an architecturally simple classification network to obtain CAD model. In particular, the framework fully considers the comorbidity mechanisms of neuro-developmental disorders and effectively integrates them with semi-supervised learning and transfer learning, providing new perspectives on interdisciplinary. Experimental results demonstrate that CITL achieves competitive accuracies of 76.32% and 73.15% for detecting autism spectrum disorder and attention deficit hyperactivity disorder, respectively, which outperforms existing related transfer learning work for 7.2% and 0.5% respectively.
A Confounding Factors-Inhibition Adversarial Learning Framework for Multi-site fMRI Mental Disorder Identification
Apr 12, 2025In open data sets of functional magnetic resonance imaging (fMRI), the heterogeneity of the data is typically attributed to a combination of factors, including differences in scanning procedures, the presence of confounding effects, and population diversities between multiple sites. These factors contribute to the diminished effectiveness of representation learning, which in turn affects the overall efficacy of subsequent classification procedures. To address these limitations, we propose a novel multi-site adversarial learning network (MSalNET) for fMRI-based mental disorder detection. Firstly, a representation learning module is introduced with a node information assembly (NIA) mechanism to better extract features from functional connectivity (FC). This mechanism aggregates edge information from both horizontal and vertical directions, effectively assembling node information. Secondly, to generalize the feature across sites, we proposed a site-level feature extraction module that can learn from individual FC data, which circumvents additional prior information. Lastly, an adversarial learning network is proposed as a means of balancing the trade-off between individual classification and site regression tasks, with the introduction of a novel loss function. The proposed method was evaluated on two multi-site fMRI datasets, i.e., Autism Brain Imaging Data Exchange (ABIDE) and ADHD-200. The results indicate that the proposed method achieves a better performance than other related algorithms with the accuracy of 75.56 and 68.92 in ABIDE and ADHD-200 datasets, respectively. Furthermore, the result of the site regression indicates that the proposed method reduces site variability from a data-driven perspective. The most discriminative brain regions revealed by NIA are consistent with statistical findings, uncovering the "black box" of deep learning to a certain extent.
VasTSD: Learning 3D Vascular Tree-state Space Diffusion Model for Angiography Synthesis
Mar 17, 2025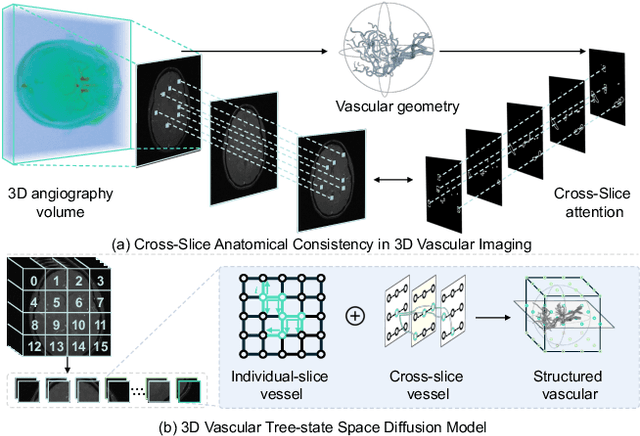



Angiography imaging is a medical imaging technique that enhances the visibility of blood vessels within the body by using contrast agents. Angiographic images can effectively assist in the diagnosis of vascular diseases. However, contrast agents may bring extra radiation exposure which is harmful to patients with health risks. To mitigate these concerns, in this paper, we aim to automatically generate angiography from non-angiographic inputs, by leveraging and enhancing the inherent physical properties of vascular structures. Previous methods relying on 2D slice-based angiography synthesis struggle with maintaining continuity in 3D vascular structures and exhibit limited effectiveness across different imaging modalities. We propose VasTSD, a 3D vascular tree-state space diffusion model to synthesize angiography from 3D non-angiographic volumes, with a novel state space serialization approach that dynamically constructs vascular tree topologies, integrating these with a diffusion-based generative model to ensure the generation of anatomically continuous vasculature in 3D volumes. A pre-trained vision embedder is employed to construct vascular state space representations, enabling consistent modeling of vascular structures across multiple modalities. Extensive experiments on various angiographic datasets demonstrate the superiority of VasTSD over prior works, achieving enhanced continuity of blood vessels in synthesized angiographic synthesis for multiple modalities and anatomical regions.
Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback
Mar 13, 2025


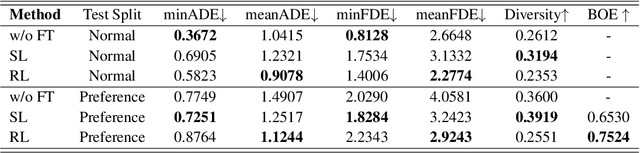
Generating human-like and adaptive trajectories is essential for autonomous driving in dynamic environments. While generative models have shown promise in synthesizing feasible trajectories, they often fail to capture the nuanced variability of human driving styles due to dataset biases and distributional shifts. To address this, we introduce TrajHF, a human feedback-driven finetuning framework for generative trajectory models, designed to align motion planning with diverse driving preferences. TrajHF incorporates multi-conditional denoiser and reinforcement learning with human feedback to refine multi-modal trajectory generation beyond conventional imitation learning. This enables better alignment with human driving preferences while maintaining safety and feasibility constraints. TrajHF achieves PDMS of 93.95 on NavSim benchmark, significantly exceeding other methods. TrajHF sets a new paradigm for personalized and adaptable trajectory generation in autonomous driving.
"Principal Components" Enable A New Language of Images
Mar 11, 2025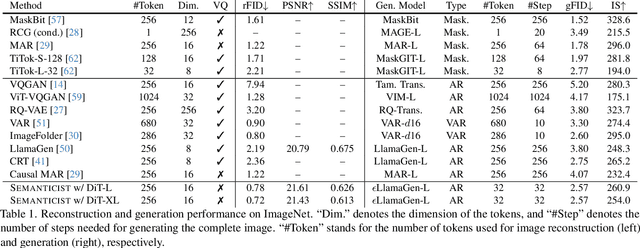
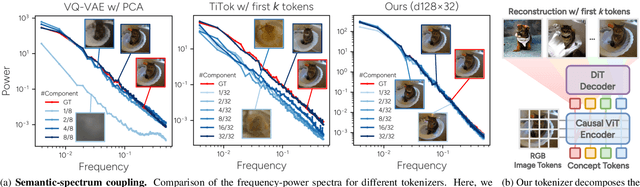
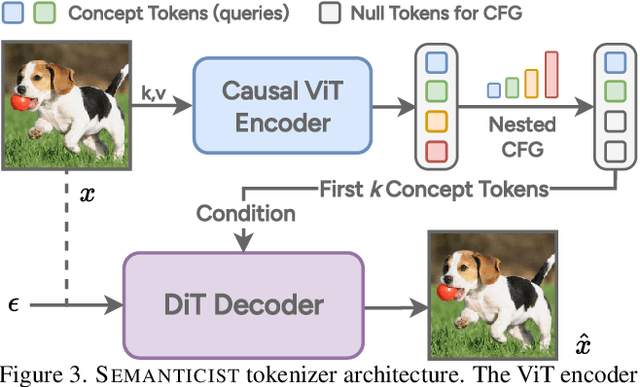
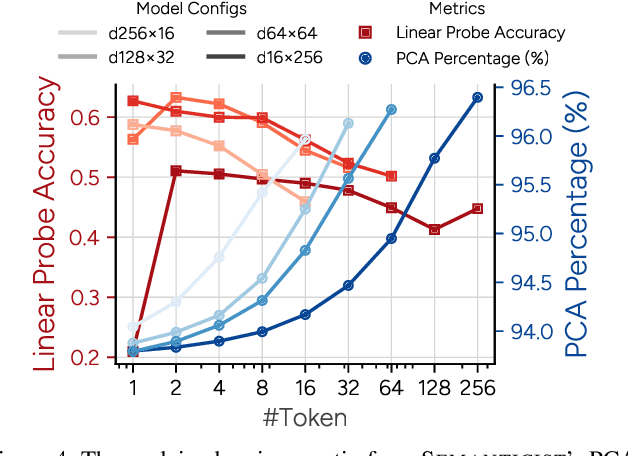
We introduce a novel visual tokenization framework that embeds a provable PCA-like structure into the latent token space. While existing visual tokenizers primarily optimize for reconstruction fidelity, they often neglect the structural properties of the latent space -- a critical factor for both interpretability and downstream tasks. Our method generates a 1D causal token sequence for images, where each successive token contributes non-overlapping information with mathematically guaranteed decreasing explained variance, analogous to principal component analysis. This structural constraint ensures the tokenizer extracts the most salient visual features first, with each subsequent token adding diminishing yet complementary information. Additionally, we identified and resolved a semantic-spectrum coupling effect that causes the unwanted entanglement of high-level semantic content and low-level spectral details in the tokens by leveraging a diffusion decoder. Experiments demonstrate that our approach achieves state-of-the-art reconstruction performance and enables better interpretability to align with the human vision system. Moreover, auto-regressive models trained on our token sequences achieve performance comparable to current state-of-the-art methods while requiring fewer tokens for training and inference.