 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDTalk: Structured Facial Priors and Dual-Branch Motion Fields for Generalizable Gaussian Talking Head Synthesis
May 11, 2026High-quality, real-time talking head synthesis remains a fundamental challenge in computer vision. Existing reconstruction- and rendering-based methods typically rely on identity-specific models, limiting cross-identity generalization. To address this issue, we propose SDTalk, a one-shot 3D Gaussian Splatting (3DGS)-based framework that generalizes to unseen identities without personalized training or fine-tuning. Our framework comprises two modules with a two-stage training strategy. In the first stage, we incorporate structured facial priors into the reconstruction module and separately predict 3DGS parameters for visible and occluded regions, enabling complete head reconstruction from a single image. In the second stage, we introduce a dual-branch motion field to model coarse and fine facial dynamics, improving detail fidelity and lip synchronization. Experiments demonstrate that SDTalk surpasses existing methods in both visual quality and inference efficiency.
HarmoWAM: Harmonizing Generalizable and Precise Manipulation via Adaptive World Action Models
May 11, 2026World Action Models (WAMs) have emerged as a promising paradigm for robot control by modeling physical dynamics. Current WAMs generally follow two paradigms: the "Imagine-then-Execute" approach, which uses video prediction to infer actions via inverse dynamics, and the "Joint Modeling" approach, which jointly models actions and video representations. Based on systematic experiments, we observe a fundamental trade-off between these paradigms: the former explicitly leverages world models for generalizable transit but lacks interaction precision, whereas the latter enables fine-grained, temporally coherent action generation but is constrained by the exploration space of the training distribution. Motivated by these findings, we propose HarmoWAM, an end-to-end WAM that fully leverages a world model to unify predictive and reactive control, enabling both generalizable transit and precise manipulation. Specifically, the world model provides spatio-temporal physical priors that condition two complementary action experts: a predictive expert that leverages latent dynamics for iterative action generation, and a reactive expert that directly infers actions from predicted visual evolution. To enable adaptive coordination, a Process-Adaptive Gating Mechanism is proposed to automatically determine the timing and location of switching between them. This allows the world model to drive the reactive expert to expand the exploration space and the predictive expert to perform precise interactions across different stages of a task. For evaluation, we construct three training-unseen test environments across six real-world robotic tasks, covering variations in background, position, and object semantics. Notably, HarmoWAM achieves strong zero-shot generalization across these scenarios, significantly outperforming prior state-of-the-art VLA models and WAMs by margins of 33% and 29%, respectively.
Look Before Acting: Enhancing Vision Foundation Representations for Vision-Language-Action Models
Mar 17, 2026Vision-Language-Action (VLA) models have recently emerged as a promising paradigm for robotic manipulation, in which reliable action prediction critically depends on accurately interpreting and integrating visual observations conditioned on language instructions. Although recent works have sought to enhance the visual capabilities of VLA models, most approaches treat the LLM backbone as a black box, providing limited insight into how visual information is grounded into action generation. Therefore, we perform a systematic analysis of multiple VLA models across different action-generation paradigms and observe that sensitivity to visual tokens progressively decreases in deeper layers during action generation. Motivated by this observation, we propose \textbf{DeepVision-VLA}, built on a \textbf{Vision-Language Mixture-of-Transformers (VL-MoT)} framework. This framework enables shared attention between the vision foundation model and the VLA backbone, injecting multi-level visual features from the vision expert into deeper layers of the VLA backbone to enhance visual representations for precise and complex manipulation. In addition, we introduce \textbf{Action-Guided Visual Pruning (AGVP)}, which leverages shallow-layer attention to prune irrelevant visual tokens while preserving task-relevant ones, reinforcing critical visual cues for manipulation with minimal computational overhead. DeepVision-VLA outperforms prior state-of-the-art methods by 9.0\% and 7.5\% on simulated and real-world tasks, respectively, providing new insights for the design of visually enhanced VLA models.
TwinRL-VLA: Digital Twin-Driven Reinforcement Learning for Real-World Robotic Manipulation
Feb 09, 2026Despite strong generalization capabilities, Vision-Language-Action (VLA) models remain constrained by the high cost of expert demonstrations and insufficient real-world interaction. While online reinforcement learning (RL) has shown promise in improving general foundation models, applying RL to VLA manipulation in real-world settings is still hindered by low exploration efficiency and a restricted exploration space. Through systematic real-world experiments, we observe that the effective exploration space of online RL is closely tied to the data distribution of supervised fine-tuning (SFT). Motivated by this observation, we propose TwinRL, a digital twin-real-world collaborative RL framework designed to scale and guide exploration for VLA models. First, a high-fidelity digital twin is efficiently reconstructed from smartphone-captured scenes, enabling realistic bidirectional transfer between real and simulated environments. During the SFT warm-up stage, we introduce an exploration space expansion strategy using digital twins to broaden the support of the data trajectory distribution. Building on this enhanced initialization, we propose a sim-to-real guided exploration strategy to further accelerate online RL. Specifically, TwinRL performs efficient and parallel online RL in the digital twin prior to deployment, effectively bridging the gap between offline and online training stages. Subsequently, we exploit efficient digital twin sampling to identify failure-prone yet informative configurations, which are used to guide targeted human-in-the-loop rollouts on the real robot. In our experiments, TwinRL approaches 100% success in both in-distribution regions covered by real-world demonstrations and out-of-distribution regions, delivering at least a 30% speedup over prior real-world RL methods and requiring only about 20 minutes on average across four tasks.
TLDiffGAN: A Latent Diffusion-GAN Framework with Temporal Information Fusion for Anomalous Sound Detection
Feb 01, 2026Existing generative models for unsupervised anomalous sound detection are limited by their inability to fully capture the complex feature distribution of normal sounds, while the potential of powerful diffusion models in this domain remains largely unexplored. To address this challenge, we propose a novel framework, TLDiffGAN, which consists of two complementary branches. One branch incorporates a latent diffusion model into the GAN generator for adversarial training, thereby making the discriminator's task more challenging and improving the quality of generated samples. The other branch leverages pretrained audio model encoders to extract features directly from raw audio waveforms for auxiliary discrimination. This framework effectively captures feature representations of normal sounds from both raw audio and Mel spectrograms. Moreover, we introduce a TMixup spectrogram augmentation technique to enhance sensitivity to subtle and localized temporal patterns that are often overlooked. Extensive experiments on the DCASE 2020 Challenge Task 2 dataset demonstrate the superior detection performance of TLDiffGAN, as well as its strong capability in anomalous time-frequency localization.
PortAgent: LLM-driven Vehicle Dispatching Agent for Port Terminals
Dec 16, 2025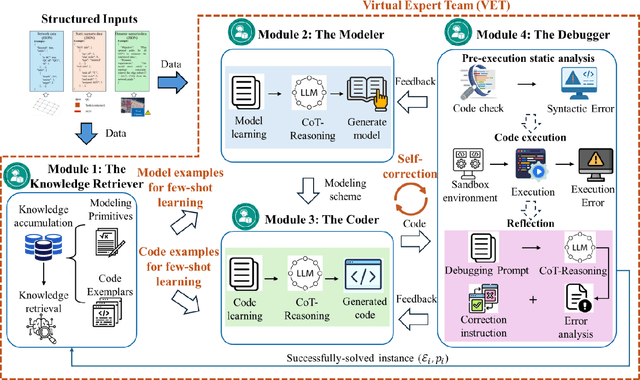
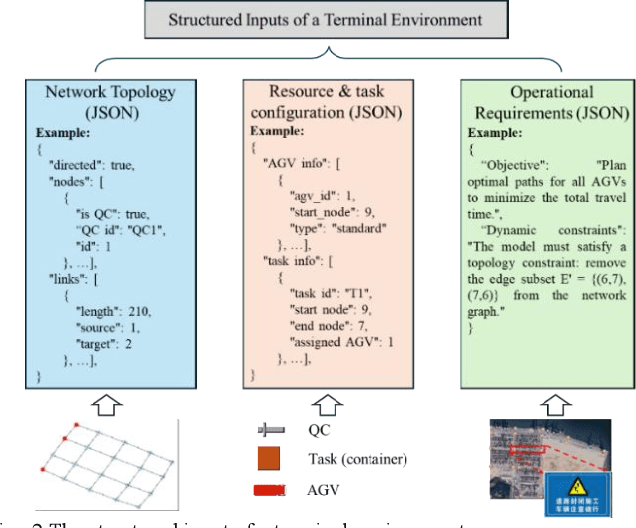
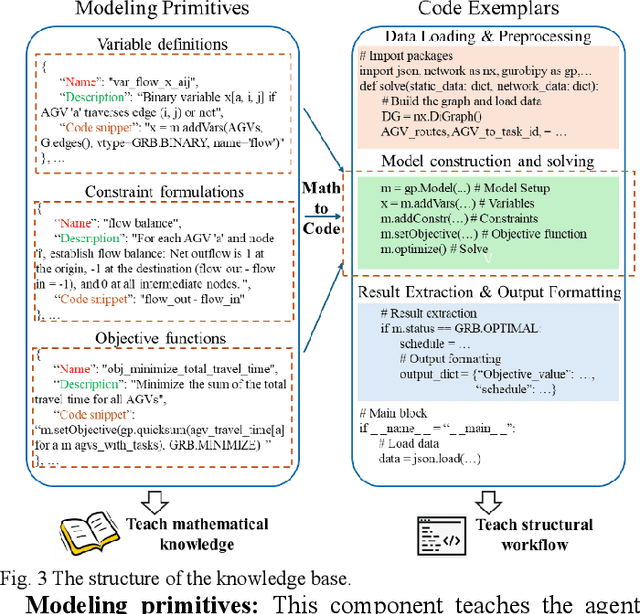
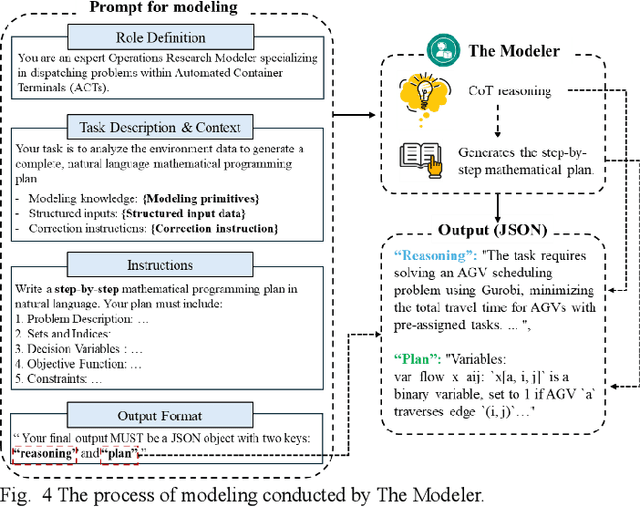
Vehicle Dispatching Systems (VDSs) are critical to the operational efficiency of Automated Container Terminals (ACTs). However, their widespread commercialization is hindered due to their low transferability across diverse terminals. This transferability challenge stems from three limitations: high reliance on port operational specialists, a high demand for terminal-specific data, and time-consuming manual deployment processes. Leveraging the emergence of Large Language Models (LLMs), this paper proposes PortAgent, an LLM-driven vehicle dispatching agent that fully automates the VDS transferring workflow. It bears three features: (1) no need for port operations specialists; (2) low need of data; and (3) fast deployment. Specifically, specialist dependency is eliminated by the Virtual Expert Team (VET). The VET collaborates with four virtual experts, including a Knowledge Retriever, Modeler, Coder, and Debugger, to emulate a human expert team for the VDS transferring workflow. These experts specialize in the domain of terminal VDS via a few-shot example learning approach. Through this approach, the experts are able to learn VDS-domain knowledge from a few VDS examples. These examples are retrieved via a Retrieval-Augmented Generation (RAG) mechanism, mitigating the high demand for terminal-specific data. Furthermore, an automatic VDS design workflow is established among these experts to avoid extra manual interventions. In this workflow, a self-correction loop inspired by the LLM Reflexion framework is created
OmniGen: Unified Multimodal Sensor Generation for Autonomous Driving
Dec 16, 2025Autonomous driving has seen remarkable advancements, largely driven by extensive real-world data collection. However, acquiring diverse and corner-case data remains costly and inefficient. Generative models have emerged as a promising solution by synthesizing realistic sensor data. However, existing approaches primarily focus on single-modality generation, leading to inefficiencies and misalignment in multimodal sensor data. To address these challenges, we propose OminiGen, which generates aligned multimodal sensor data in a unified framework. Our approach leverages a shared Bird\u2019s Eye View (BEV) space to unify multimodal features and designs a novel generalizable multimodal reconstruction method, UAE, to jointly decode LiDAR and multi-view camera data. UAE achieves multimodal sensor decoding through volume rendering, enabling accurate and flexible reconstruction. Furthermore, we incorporate a Diffusion Transformer (DiT) with a ControlNet branch to enable controllable multimodal sensor generation. Our comprehensive experiments demonstrate that OminiGen achieves desired performances in unified multimodal sensor data generation with multimodal consistency and flexible sensor adjustments.
The Better You Learn, The Smarter You Prune: Towards Efficient Vision-language-action Models via Differentiable Token Pruning
Sep 16, 2025We present LightVLA, a simple yet effective differentiable token pruning framework for vision-language-action (VLA) models. While VLA models have shown impressive capability in executing real-world robotic tasks, their deployment on resource-constrained platforms is often bottlenecked by the heavy attention-based computation over large sets of visual tokens. LightVLA addresses this challenge through adaptive, performance-driven pruning of visual tokens: It generates dynamic queries to evaluate visual token importance, and adopts Gumbel softmax to enable differentiable token selection. Through fine-tuning, LightVLA learns to preserve the most informative visual tokens while pruning tokens which do not contribute to task execution, thereby improving efficiency and performance simultaneously. Notably, LightVLA requires no heuristic magic numbers and introduces no additional trainable parameters, making it compatible with modern inference frameworks. Experimental results demonstrate that LightVLA outperforms different VLA models and existing token pruning methods across diverse tasks on the LIBERO benchmark, achieving higher success rates with substantially reduced computational overhead. Specifically, LightVLA reduces FLOPs and latency by 59.1% and 38.2% respectively, with a 2.9% improvement in task success rate. Meanwhile, we also investigate the learnable query-based token pruning method LightVLA* with additional trainable parameters, which also achieves satisfactory performance. Our work reveals that as VLA pursues optimal performance, LightVLA spontaneously learns to prune tokens from a performance-driven perspective. To the best of our knowledge, LightVLA is the first work to apply adaptive visual token pruning to VLA tasks with the collateral goals of efficiency and performance, marking a significant step toward more efficient, powerful and practical real-time robotic systems.
Generalizable Engagement Estimation in Conversation via Domain Prompting and Parallel Attention
Aug 20, 2025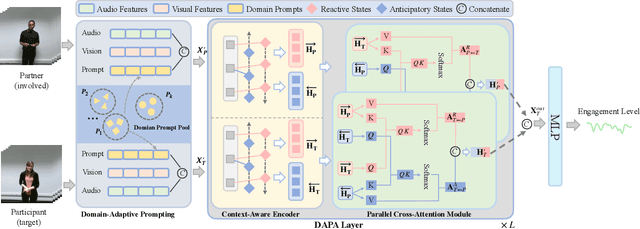

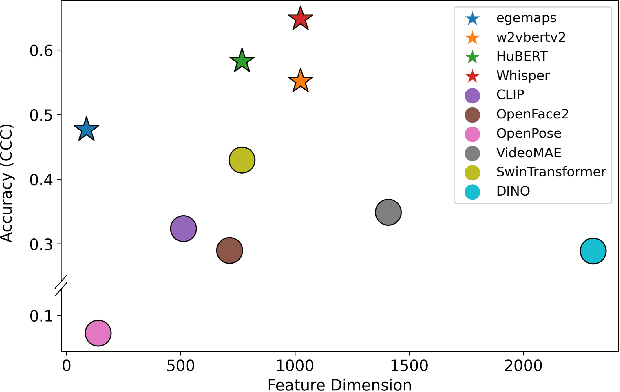
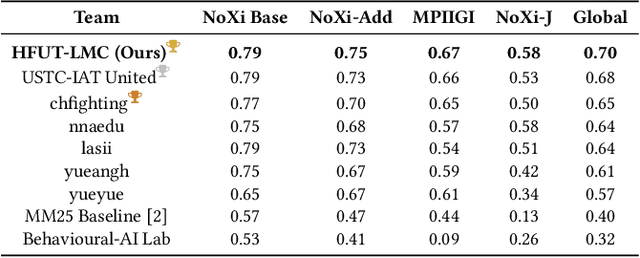
Accurate engagement estimation is essential for adaptive human-computer interaction systems, yet robust deployment is hindered by poor generalizability across diverse domains and challenges in modeling complex interaction dynamics.To tackle these issues, we propose DAPA (Domain-Adaptive Parallel Attention), a novel framework for generalizable conversational engagement modeling. DAPA introduces a Domain Prompting mechanism by prepending learnable domain-specific vectors to the input, explicitly conditioning the model on the data's origin to facilitate domain-aware adaptation while preserving generalizable engagement representations. To capture interactional synchrony, the framework also incorporates a Parallel Cross-Attention module that explicitly aligns reactive (forward BiLSTM) and anticipatory (backward BiLSTM) states between participants.Extensive experiments demonstrate that DAPA establishes a new state-of-the-art performance on several cross-cultural and cross-linguistic benchmarks, notably achieving an absolute improvement of 0.45 in Concordance Correlation Coefficient (CCC) over a strong baseline on the NoXi-J test set. The superiority of our method was also confirmed by winning the first place in the Multi-Domain Engagement Estimation Challenge at MultiMediate'25.
DriveAction: A Benchmark for Exploring Human-like Driving Decisions in VLA Models
Jun 06, 2025Vision-Language-Action (VLA) models have advanced autonomous driving, but existing benchmarks still lack scenario diversity, reliable action-level annotation, and evaluation protocols aligned with human preferences. To address these limitations, we introduce DriveAction, the first action-driven benchmark specifically designed for VLA models, comprising 16,185 QA pairs generated from 2,610 driving scenarios. DriveAction leverages real-world driving data proactively collected by users of production-level autonomous vehicles to ensure broad and representative scenario coverage, offers high-level discrete action labels collected directly from users' actual driving operations, and implements an action-rooted tree-structured evaluation framework that explicitly links vision, language, and action tasks, supporting both comprehensive and task-specific assessment. Our experiments demonstrate that state-of-the-art vision-language models (VLMs) require both vision and language guidance for accurate action prediction: on average, accuracy drops by 3.3% without vision input, by 4.1% without language input, and by 8.0% without either. Our evaluation supports precise identification of model bottlenecks with robust and consistent results, thus providing new insights and a rigorous foundation for advancing human-like decisions in autonomous driving.