 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyledStreets: Multi-style Street Simulator with Spatial and Temporal Consistency
Mar 27, 2025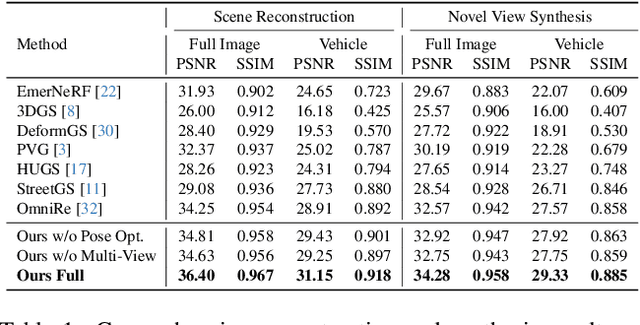

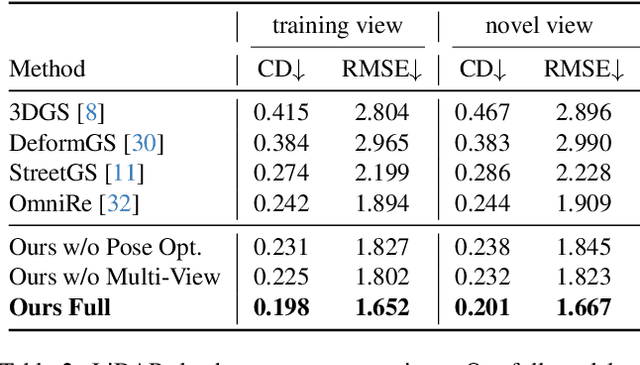
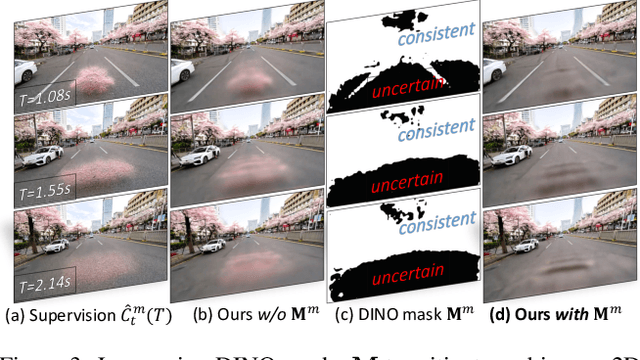
Urban scene reconstruction requires modeling both static infrastructure and dynamic elements while supporting diverse environmental conditions. We present \textbf{StyledStreets}, a multi-style street simulator that achieves instruction-driven scene editing with guaranteed spatial and temporal consistency. Building on a state-of-the-art Gaussian Splatting framework for street scenarios enhanced by our proposed pose optimization and multi-view training, our method enables photorealistic style transfers across seasons, weather conditions, and camera setups through three key innovations: First, a hybrid embedding scheme disentangles persistent scene geometry from transient style attributes, allowing realistic environmental edits while preserving structural integrity. Second, uncertainty-aware rendering mitigates supervision noise from diffusion priors, enabling robust training across extreme style variations. Third, a unified parametric model prevents geometric drift through regularized updates, maintaining multi-view consistency across seven vehicle-mounted cameras. Our framework preserves the original scene's motion patterns and geometric relationships. Qualitative results demonstrate plausible transitions between diverse conditions (snow, sandstorm, night), while quantitative evaluations show state-of-the-art geometric accuracy under style transfers. The approach establishes new capabilities for urban simulation, with applications in autonomous vehicle testing and augmented reality systems requiring reliable environmental consistency. Codes will be publicly available upon publication.
ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration
Nov 29, 2024



Closed-loop simulation is crucial for end-to-end autonomous driving. Existing sensor simulation methods (e.g., NeRF and 3DGS) reconstruct driving scenes based on conditions that closely mirror training data distributions. However, these methods struggle with rendering novel trajectories, such as lane changes. Recent works have demonstrated that integrating world model knowledge alleviates these issues. Despite their efficiency, these approaches still encounter difficulties in the accurate representation of more complex maneuvers, with multi-lane shifts being a notable example. Therefore, we introduce ReconDreamer, which enhances driving scene reconstruction through incremental integration of world model knowledge. Specifically, DriveRestorer is proposed to mitigate artifacts via online restoration. This is complemented by a progressive data update strategy designed to ensure high-quality rendering for more complex maneuvers. To the best of our knowledge, ReconDreamer is the first method to effectively render in large maneuvers. Experimental results demonstrate that ReconDreamer outperforms Street Gaussians in the NTA-IoU, NTL-IoU, and FID, with relative improvements by 24.87%, 6.72%, and 29.97%. Furthermore, ReconDreamer surpasses DriveDreamer4D with PVG during large maneuver rendering, as verified by a relative improvement of 195.87% in the NTA-IoU metric and a comprehensive user study.
GOOD: General Optimization-based Fusion for 3D Object Detection via LiDAR-Camera Object Candidates
Mar 17, 2023



3D object detection serves as the core basis of the perception tasks in autonomous driving. Recent years have seen the rapid progress of multi-modal fusion strategies for more robust and accurate 3D object detection. However, current researches for robust fusion are all learning-based frameworks, which demand a large amount of training data and are inconvenient to implement in new scenes. In this paper, we propose GOOD, a general optimization-based fusion framework that can achieve satisfying detection without training additional models and is available for any combinations of 2D and 3D detectors to improve the accuracy and robustness of 3D detection. First we apply the mutual-sided nearest-neighbor probability model to achieve the 3D-2D data association. Then we design an optimization pipeline that can optimize different kinds of instances separately based on the matching result. Apart from this, the 3D MOT method is also introduced to enhance the performance aided by previous frames. To the best of our knowledge, this is the first optimization-based late fusion framework for multi-modal 3D object detection which can be served as a baseline for subsequent research. Experiments on both nuScenes and KITTI datasets are carried out and the results show that GOOD outperforms by 9.1\% on mAP score compared with PointPillars and achieves competitive results with the learning-based late fusion CLOCs.
EMV-LIO: An Efficient Multiple Vision aided LiDAR-Inertial Odometry
Feb 15, 2023To deal with the degeneration caused by the incomplete constraints of single sensor, multi-sensor fusion strategies especially in LiDAR-vision-inertial fusion area have attracted much interest from both the industry and the research community in recent years. Considering that a monocular camera is vulnerable to the influence of ambient light from a certain direction and fails, which makes the system degrade into a LiDAR-inertial system, multiple cameras are introduced to expand the visual observation so as to improve the accuracy and robustness of the system. Besides, removing LiDAR's noise via range image, setting condition for nearest neighbor search, and replacing kd-Tree with ikd-Tree are also introduced to enhance the efficiency. Based on the above, we propose an Efficient Multiple vision aided LiDAR-inertial odometry system (EMV-LIO), and evaluate its performance on both open datasets and our custom datasets. Experiments show that the algorithm is helpful to improve the accuracy, robustness and efficiency of the whole system compared with LVI-SAM. Our implementation will be available upon acceptance.
Anti-degenerated UWB-LiDAR Localization for Automatic Road Roller in Tunnel
Sep 22, 2021
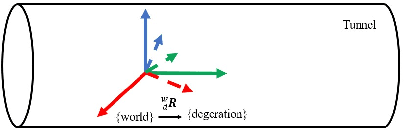


The automatic road roller, as a popular type of construction robot, has attracted much interest from both the industry and the research community in recent years. However, when it comes to tunnels where the degeneration issues are prone to happen, it is still a challenging problem to provide an accurate positioning result for the robot. In this paper, we aim to deal with this problem by fusing LiDAR and UWB measurements based on optimization. In the proposed localization method, the directions of non-degeneration will be constrained and the covariance of UWB reconstruction will be introduced to improve the accuracy of localization. Apart from these, a method that can extract the feature of the inner wall of tunnels to assist positioning is also presented in this paper. To evaluate the effectiveness of the proposed method, three experiments with real road roller were carried out and the results show that our method can achieve better performance than the existing methods and can be applied to automatic road roller working inside tunnels. Finally, we discuss the feasibility of deploying the system in real applications and make several recommendations.