 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniDriveDreamer: A Single-Stage Multimodal World Model for Autonomous Driving
Feb 02, 2026World models have demonstrated significant promise for data synthesis in autonomous driving. However, existing methods predominantly concentrate on single-modality generation, typically focusing on either multi-camera video or LiDAR sequence synthesis. In this paper, we propose UniDriveDreamer, a single-stage unified multimodal world model for autonomous driving, which directly generates multimodal future observations without relying on intermediate representations or cascaded modules. Our framework introduces a LiDAR-specific variational autoencoder (VAE) designed to encode input LiDAR sequences, alongside a video VAE for multi-camera images. To ensure cross-modal compatibility and training stability, we propose Unified Latent Anchoring (ULA), which explicitly aligns the latent distributions of the two modalities. The aligned features are fused and processed by a diffusion transformer that jointly models their geometric correspondence and temporal evolution. Additionally, structured scene layout information is projected per modality as a conditioning signal to guide the synthesis. Extensive experiments demonstrate that UniDriveDreamer outperforms previous state-of-the-art methods in both video and LiDAR generation, while also yielding measurable improvements in downstream
MrRoPE: Mixed-radix Rotary Position Embedding
Jan 28, 2026Rotary Position Embedding (RoPE)-extension refers to modifying or generalizing the Rotary Position Embedding scheme to handle longer sequences than those encountered during pre-training. However, current extension strategies are highly diverse and lack a unified theoretical foundation. In this paper, we propose MrRoPE (Mixed-radix RoPE), a generalized encoding formulation based on a radix system conversion perspective, which elegantly unifies various RoPE-extension approaches as distinct radix conversion strategies. Based on this theory, we introduce two training-free extensions, MrRoPE-Uni and MrRoPE-Pro, which leverage uniform and progressive radix conversion strategies, respectively, to achieve 'train short, test long' generalization. Without fine-tuning, MrRoPE-Pro sustains over 85% recall in the 128K-context Needle-in-a-Haystack test and achieves more than double YaRN's accuracy on Infinite-Bench retrieval and dialogue subsets. Theoretical analysis confirms that MrRoPE-Pro effectively raises the upper bound of RoPE's attainable encoding length, which further validates the reliability and utility of our theory and methodology.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
RobustMask: Certified Robustness against Adversarial Neural Ranking Attack via Randomized Masking
Dec 29, 2025Neural ranking models have achieved remarkable progress and are now widely deployed in real-world applications such as Retrieval-Augmented Generation (RAG). However, like other neural architectures, they remain vulnerable to adversarial manipulations: subtle character-, word-, or phrase-level perturbations can poison retrieval results and artificially promote targeted candidates, undermining the integrity of search engines and downstream systems. Existing defenses either rely on heuristics with poor generalization or on certified methods that assume overly strong adversarial knowledge, limiting their practical use. To address these challenges, we propose RobustMask, a novel defense that combines the context-prediction capability of pretrained language models with a randomized masking-based smoothing mechanism. Our approach strengthens neural ranking models against adversarial perturbations at the character, word, and phrase levels. Leveraging both the pairwise comparison ability of ranking models and probabilistic statistical analysis, we provide a theoretical proof of RobustMask's certified top-K robustness. Extensive experiments further demonstrate that RobustMask successfully certifies over 20% of candidate documents within the top-10 ranking positions against adversarial perturbations affecting up to 30% of their content. These results highlight the effectiveness of RobustMask in enhancing the adversarial robustness of neural ranking models, marking a significant step toward providing stronger security guarantees for real-world retrieval systems.
Design and Experimental Validation of Closed-Form CBF-Based Safe Control for Stewart Platform Under Multiple Constraints
Dec 11, 2025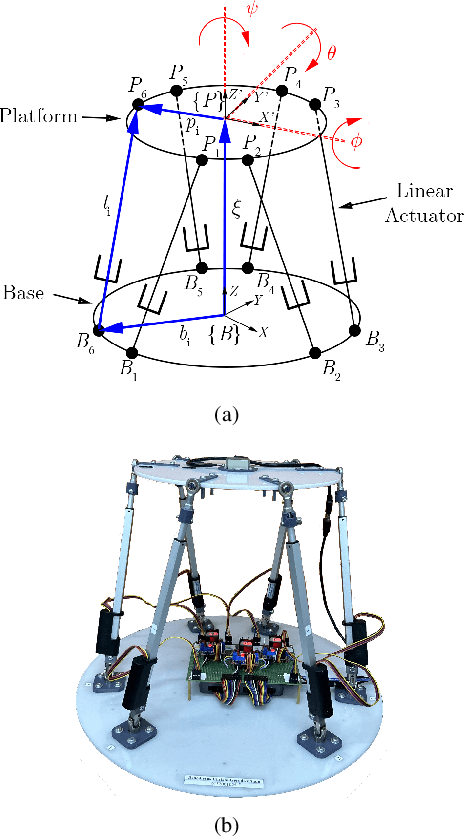
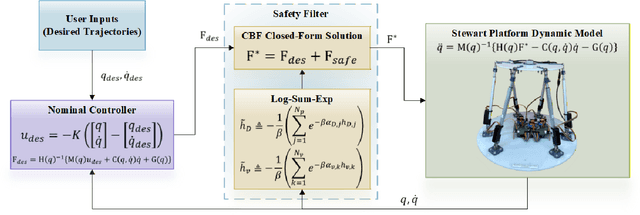
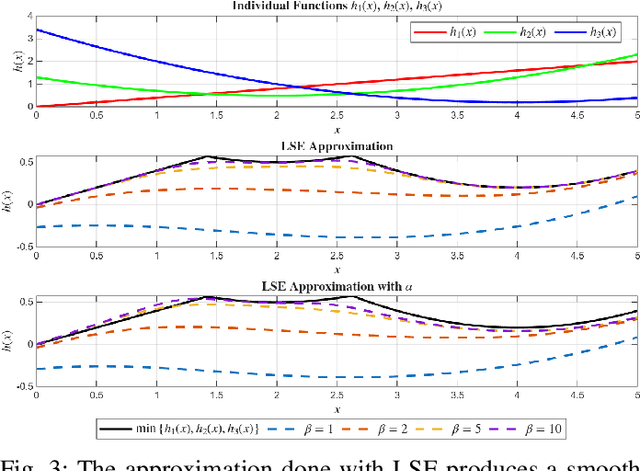
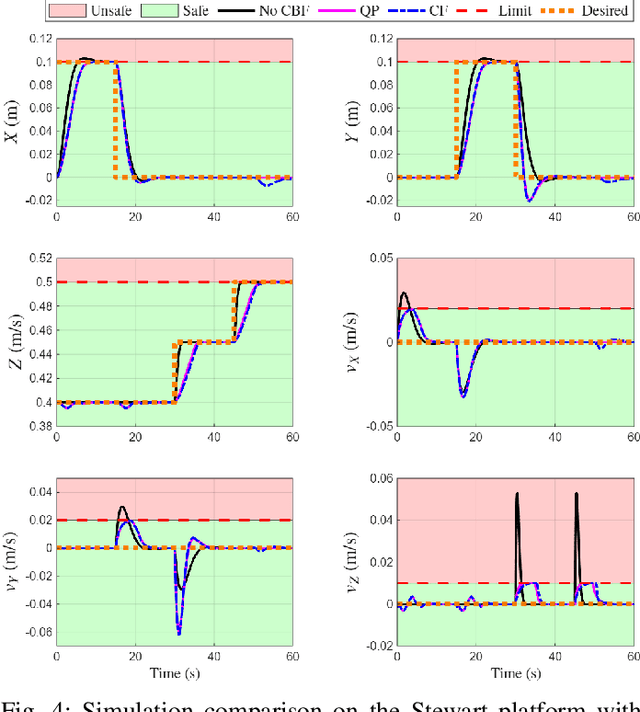
This letter presents a closed-form solution of Control Barrier Function (CBF) framework for enforcing safety constraints on a Stewart robotic platform. The proposed method simultaneously handles multiple position and velocity constraints through an explicit closed-form control law, eliminating the need to solve a Quadratic Program (QP) at every control step and enabling efficient real-time implementation. This letter derives necessary and sufficient conditions under which the closed-form expression remains non-singular, thereby ensuring well-posedness of the CBF solution to multi-constraint problem. The controller is validated in both simulation and hardware experiments on a custom-built Stewart platform prototype, demonstrating safetyguaranteed performance that is comparable to the QP-based formulation, while reducing computation time by more than an order of magnitude. The results confirm that the proposed approach provides a reliable and computationally lightweight framework for real-time safe control of parallel robotic systems. The experimental videos are available on the project website. (https://nail-uh.github.io/StewartPlatformSafeControl.github.io/)
EnchTable: Unified Safety Alignment Transfer in Fine-tuned Large Language Models
Nov 13, 2025Many machine learning models are fine-tuned from large language models (LLMs) to achieve high performance in specialized domains like code generation, biomedical analysis, and mathematical problem solving. However, this fine-tuning process often introduces a critical vulnerability: the systematic degradation of safety alignment, undermining ethical guidelines and increasing the risk of harmful outputs. Addressing this challenge, we introduce EnchTable, a novel framework designed to transfer and maintain safety alignment in downstream LLMs without requiring extensive retraining. EnchTable leverages a Neural Tangent Kernel (NTK)-based safety vector distillation method to decouple safety constraints from task-specific reasoning, ensuring compatibility across diverse model architectures and sizes. Additionally, our interference-aware merging technique effectively balances safety and utility, minimizing performance compromises across various task domains. We implemented a fully functional prototype of EnchTable on three different task domains and three distinct LLM architectures, and evaluated its performance through extensive experiments on eleven diverse datasets, assessing both utility and model safety. Our evaluations include LLMs from different vendors, demonstrating EnchTable's generalization capability. Furthermore, EnchTable exhibits robust resistance to static and dynamic jailbreaking attacks, outperforming vendor-released safety models in mitigating adversarial prompts. Comparative analyses with six parameter modification methods and two inference-time alignment baselines reveal that EnchTable achieves a significantly lower unsafe rate, higher utility score, and universal applicability across different task domains. Additionally, we validate EnchTable can be seamlessly integrated into various deployment pipelines without significant overhead.
End-to-End Design and Validation of a Low-Cost Stewart Platform with Nonlinear Estimation and Control
Oct 27, 2025This paper presents the complete design, control, and experimental validation of a low-cost Stewart platform prototype developed as an affordable yet capable robotic testbed for research and education. The platform combines off the shelf components with 3D printed and custom fabricated parts to deliver full six degrees of freedom motions using six linear actuators connecting a moving platform to a fixed base. The system software integrates dynamic modeling, data acquisition, and real time control within a unified framework. A robust trajectory tracking controller based on feedback linearization, augmented with an LQR scheme, compensates for the platform's nonlinear dynamics to achieve precise motion control. In parallel, an Extended Kalman Filter fuses IMU and actuator encoder feedback to provide accurate and reliable state estimation under sensor noise and external disturbances. Unlike prior efforts that emphasize only isolated aspects such as modeling or control, this work delivers a complete hardware-software platform validated through both simulation and experiments on static and dynamic trajectories. Results demonstrate effective trajectory tracking and real-time state estimation, highlighting the platform's potential as a cost effective and versatile tool for advanced research and educational applications.
VLA-R1: Enhancing Reasoning in Vision-Language-Action Models
Oct 02, 2025Vision-Language-Action (VLA) models aim to unify perception, language understanding, and action generation, offering strong cross-task and cross-scene generalization with broad impact on embodied AI. However, current VLA models often lack explicit step-by-step reasoning, instead emitting final actions without considering affordance constraints or geometric relations. Their post-training pipelines also rarely reinforce reasoning quality, relying primarily on supervised fine-tuning with weak reward design. To address these challenges, we present VLA-R1, a reasoning-enhanced VLA that integrates Reinforcement Learning from Verifiable Rewards (RLVR) with Group Relative Policy Optimization (GRPO) to systematically optimize both reasoning and execution. Specifically, we design an RLVR-based post-training strategy with verifiable rewards for region alignment, trajectory consistency, and output formatting, thereby strengthening reasoning robustness and execution accuracy. Moreover, we develop VLA-CoT-13K, a high-quality dataset that provides chain-of-thought supervision explicitly aligned with affordance and trajectory annotations. Furthermore, extensive evaluations on in-domain, out-of-domain, simulation, and real-robot platforms demonstrate that VLA-R1 achieves superior generalization and real-world performance compared to prior VLA methods. We plan to release the model, code, and dataset following the publication of this work. Code: https://github.com/GigaAI-research/VLA-R1. Website: https://gigaai-research.github.io/VLA-R1.
EgoDemoGen: Novel Egocentric Demonstration Generation Enables Viewpoint-Robust Manipulation
Sep 26, 2025


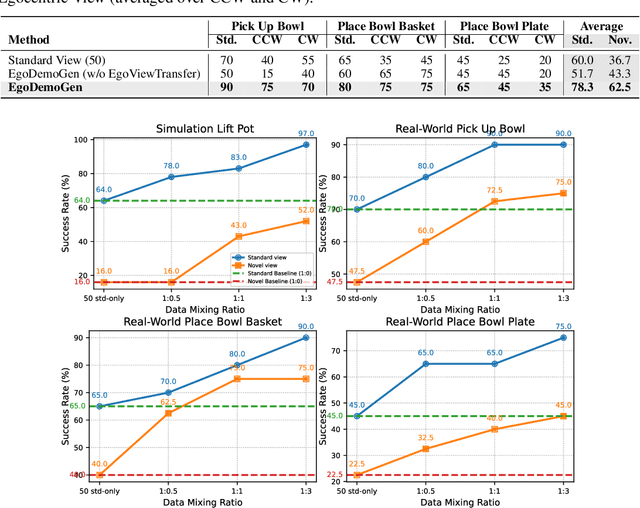
Imitation learning based policies perform well in robotic manipulation, but they often degrade under *egocentric viewpoint shifts* when trained from a single egocentric viewpoint. To address this issue, we present **EgoDemoGen**, a framework that generates *paired* novel egocentric demonstrations by retargeting actions in the novel egocentric frame and synthesizing the corresponding egocentric observation videos with proposed generative video repair model **EgoViewTransfer**, which is conditioned by a novel-viewpoint reprojected scene video and a robot-only video rendered from the retargeted joint actions. EgoViewTransfer is finetuned from a pretrained video generation model using self-supervised double reprojection strategy. We evaluate EgoDemoGen on both simulation (RoboTwin2.0) and real-world robot. After training with a mixture of EgoDemoGen-generated novel egocentric demonstrations and original standard egocentric demonstrations, policy success rate improves **absolutely** by **+17.0%** for standard egocentric viewpoint and by **+17.7%** for novel egocentric viewpoints in simulation. On real-world robot, the **absolute** improvements are **+18.3%** and **+25.8%**. Moreover, performance continues to improve as the proportion of EgoDemoGen-generated demonstrations increases, with diminishing returns. These results demonstrate that EgoDemoGen provides a practical route to egocentric viewpoint-robust robotic manipulation.
MimicDreamer: Aligning Human and Robot Demonstrations for Scalable VLA Training
Sep 26, 2025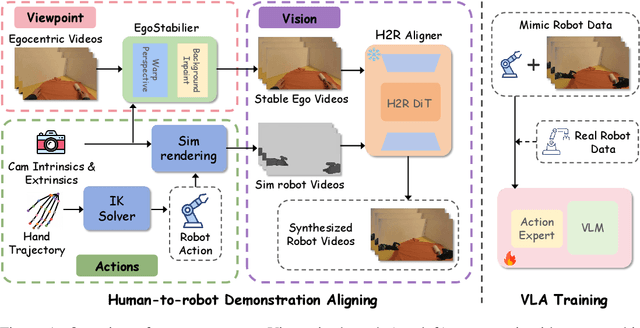

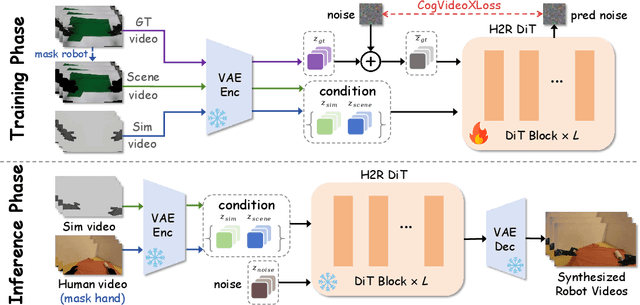
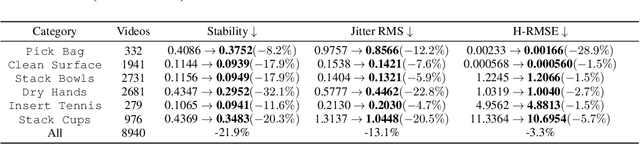
Vision Language Action (VLA) models derive their generalization capability from diverse training data, yet collecting embodied robot interaction data remains prohibitively expensive. In contrast, human demonstration videos are far more scalable and cost-efficient to collect, and recent studies confirm their effectiveness in training VLA models. However, a significant domain gap persists between human videos and robot-executed videos, including unstable camera viewpoints, visual discrepancies between human hands and robotic arms, and differences in motion dynamics. To bridge this gap, we propose MimicDreamer, a framework that turns fast, low-cost human demonstrations into robot-usable supervision by jointly aligning vision, viewpoint, and actions to directly support policy training. For visual alignment, we propose H2R Aligner, a video diffusion model that generates high-fidelity robot demonstration videos by transferring motion from human manipulation footage. For viewpoint stabilization, EgoStabilizer is proposed, which canonicalizes egocentric videos via homography and inpaints occlusions and distortions caused by warping. For action alignment, we map human hand trajectories to the robot frame and apply a constrained inverse kinematics solver to produce feasible, low-jitter joint commands with accurate pose tracking. Empirically, VLA models trained purely on our synthesized human-to-robot videos achieve few-shot execution on real robots. Moreover, scaling training with human data significantly boosts performance compared to models trained solely on real robot data; our approach improves the average success rate by 14.7\% across six representative manipulation tasks.