 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Lanes and Points in Complex Scenarios for Monocular 3D Lane Detection
Mar 08, 2025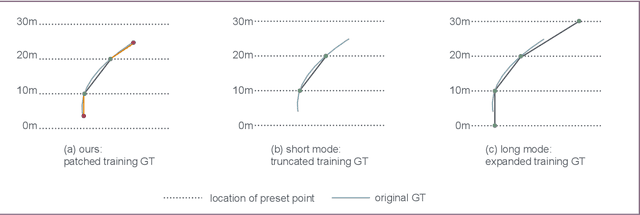
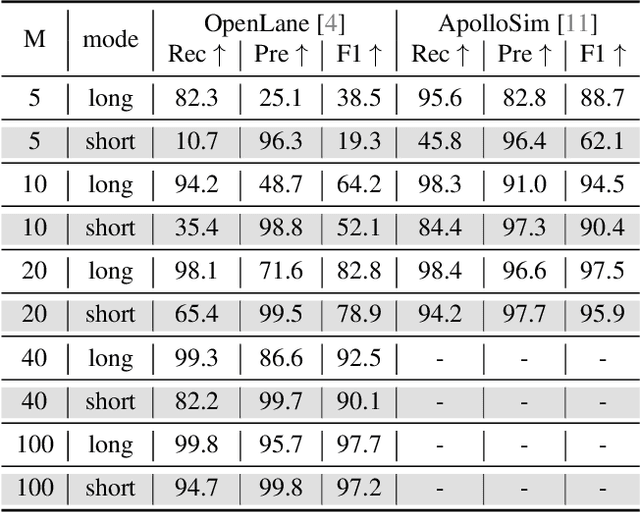
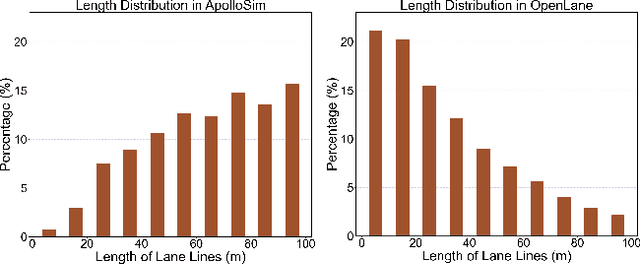
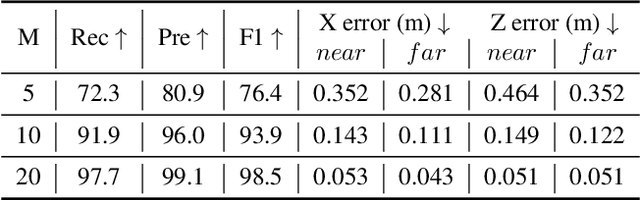
Monocular 3D lane detection is a fundamental task in autonomous driving. Although sparse-point methods lower computational load and maintain high accuracy in complex lane geometries, current methods fail to fully leverage the geometric structure of lanes in both lane geometry representations and model design. In lane geometry representations, we present a theoretical analysis alongside experimental validation to verify that current sparse lane representation methods contain inherent flaws, resulting in potential errors of up to 20 m, which raise significant safety concerns for driving. To address this issue, we propose a novel patching strategy to completely represent the full lane structure. To enable existing models to match this strategy, we introduce the EndPoint head (EP-head), which adds a patching distance to endpoints. The EP-head enables the model to predict more complete lane representations even with fewer preset points, effectively addressing existing limitations and paving the way for models that are faster and require fewer parameters in the future. In model design, to enhance the model's perception of lane structures, we propose the PointLane attention (PL-attention), which incorporates prior geometric knowledge into the attention mechanism. Extensive experiments demonstrate the effectiveness of the proposed methods on various state-of-the-art models. For instance, in terms of the overall F1-score, our methods improve Persformer by 4.4 points, Anchor3DLane by 3.2 points, and LATR by 2.8 points. The code will be available soon.
Hierarchical Temporal Context Learning for Camera-based Semantic Scene Completion
Jul 02, 2024Camera-based 3D semantic scene completion (SSC) is pivotal for predicting complicated 3D layouts with limited 2D image observations. The existing mainstream solutions generally leverage temporal information by roughly stacking history frames to supplement the current frame, such straightforward temporal modeling inevitably diminishes valid clues and increases learning difficulty. To address this problem, we present HTCL, a novel Hierarchical Temporal Context Learning paradigm for improving camera-based semantic scene completion. The primary innovation of this work involves decomposing temporal context learning into two hierarchical steps: (a) cross-frame affinity measurement and (b) affinity-based dynamic refinement. Firstly, to separate critical relevant context from redundant information, we introduce the pattern affinity with scale-aware isolation and multiple independent learners for fine-grained contextual correspondence modeling. Subsequently, to dynamically compensate for incomplete observations, we adaptively refine the feature sampling locations based on initially identified locations with high affinity and their neighboring relevant regions. Our method ranks $1^{st}$ on the SemanticKITTI benchmark and even surpasses LiDAR-based methods in terms of mIoU on the OpenOccupancy benchmark. Our code is available on https://github.com/Arlo0o/HTCL.
NeuroGauss4D-PCI: 4D Neural Fields and Gaussian Deformation Fields for Point Cloud Interpolation
May 23, 2024Point Cloud Interpolation confronts challenges from point sparsity, complex spatiotemporal dynamics, and the difficulty of deriving complete 3D point clouds from sparse temporal information. This paper presents NeuroGauss4D-PCI, which excels at modeling complex non-rigid deformations across varied dynamic scenes. The method begins with an iterative Gaussian cloud soft clustering module, offering structured temporal point cloud representations. The proposed temporal radial basis function Gaussian residual utilizes Gaussian parameter interpolation over time, enabling smooth parameter transitions and capturing temporal residuals of Gaussian distributions. Additionally, a 4D Gaussian deformation field tracks the evolution of these parameters, creating continuous spatiotemporal deformation fields. A 4D neural field transforms low-dimensional spatiotemporal coordinates ($x,y,z,t$) into a high-dimensional latent space. Finally, we adaptively and efficiently fuse the latent features from neural fields and the geometric features from Gaussian deformation fields. NeuroGauss4D-PCI outperforms existing methods in point cloud frame interpolation, delivering leading performance on both object-level (DHB) and large-scale autonomous driving datasets (NL-Drive), with scalability to auto-labeling and point cloud densification tasks. The source code is released at https://github.com/jiangchaokang/NeuroGauss4D-PCI.
GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
Apr 07, 2024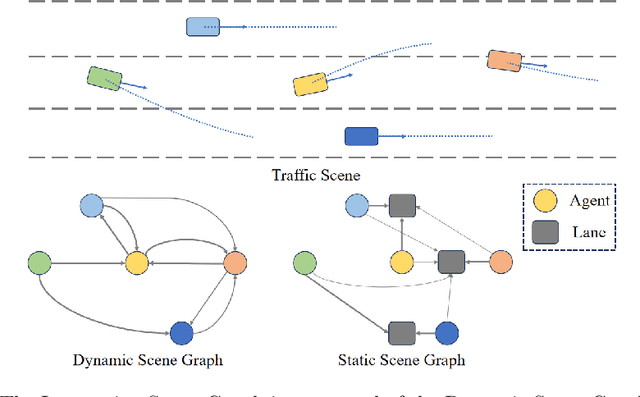
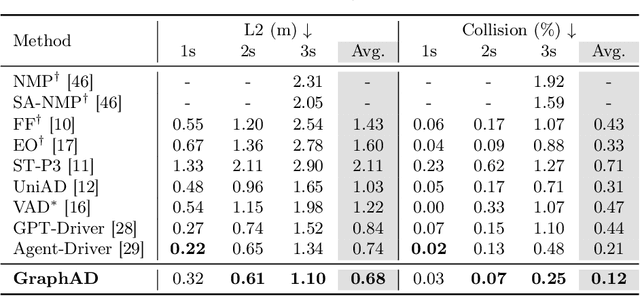
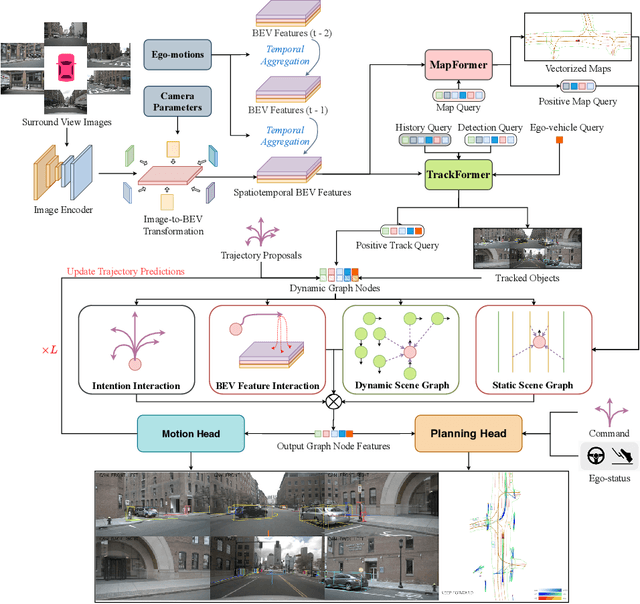
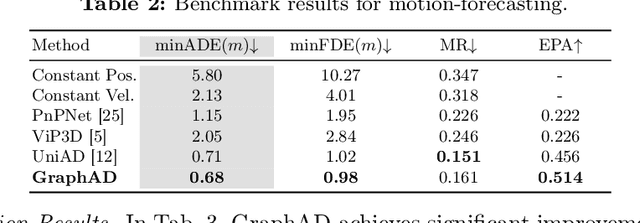
Modeling complicated interactions among the ego-vehicle, road agents, and map elements has been a crucial part for safety-critical autonomous driving. Previous works on end-to-end autonomous driving rely on the attention mechanism for handling heterogeneous interactions, which fails to capture the geometric priors and is also computationally intensive. In this paper, we propose the Interaction Scene Graph (ISG) as a unified method to model the interactions among the ego-vehicle, road agents, and map elements. With the representation of the ISG, the driving agents aggregate essential information from the most influential elements, including the road agents with potential collisions and the map elements to follow. Since a mass of unnecessary interactions are omitted, the more efficient scene-graph-based framework is able to focus on indispensable connections and leads to better performance. We evaluate the proposed method for end-to-end autonomous driving on the nuScenes dataset. Compared with strong baselines, our method significantly outperforms in the full-stack driving tasks, including perception, prediction, and planning. Code will be released at https://github.com/zhangyp15/GraphAD.
3DSFLabelling: Boosting 3D Scene Flow Estimation by Pseudo Auto-labelling
Mar 01, 2024



Learning 3D scene flow from LiDAR point clouds presents significant difficulties, including poor generalization from synthetic datasets to real scenes, scarcity of real-world 3D labels, and poor performance on real sparse LiDAR point clouds. We present a novel approach from the perspective of auto-labelling, aiming to generate a large number of 3D scene flow pseudo labels for real-world LiDAR point clouds. Specifically, we employ the assumption of rigid body motion to simulate potential object-level rigid movements in autonomous driving scenarios. By updating different motion attributes for multiple anchor boxes, the rigid motion decomposition is obtained for the whole scene. Furthermore, we developed a novel 3D scene flow data augmentation method for global and local motion. By perfectly synthesizing target point clouds based on augmented motion parameters, we easily obtain lots of 3D scene flow labels in point clouds highly consistent with real scenarios. On multiple real-world datasets including LiDAR KITTI, nuScenes, and Argoverse, our method outperforms all previous supervised and unsupervised methods without requiring manual labelling. Impressively, our method achieves a tenfold reduction in EPE3D metric on the LiDAR KITTI dataset, reducing it from $0.190m$ to a mere $0.008m$ error.
Detecting As Labeling: Rethinking LiDAR-camera Fusion in 3D Object Detection
Nov 13, 2023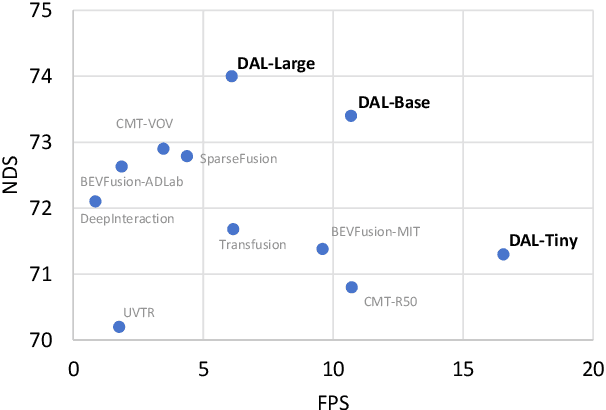

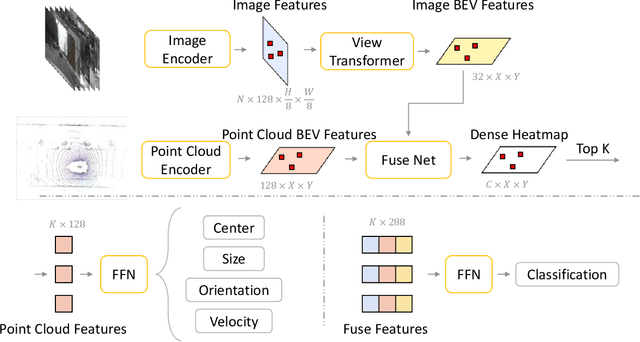
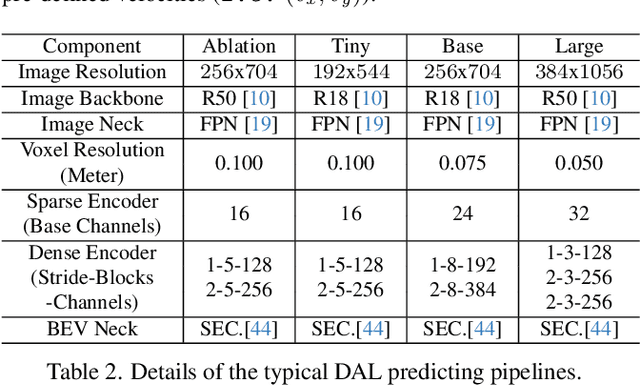
3D object Detection with LiDAR-camera encounters overfitting in algorithm development which is derived from the violation of some fundamental rules. We refer to the data annotation in dataset construction for theory complementing and argue that the regression task prediction should not involve the feature from the camera branch. By following the cutting-edge perspective of 'Detecting As Labeling', we propose a novel paradigm dubbed DAL. With the most classical elementary algorithms, a simple predicting pipeline is constructed by imitating the data annotation process. Then we train it in the simplest way to minimize its dependency and strengthen its portability. Though simple in construction and training, the proposed DAL paradigm not only substantially pushes the performance boundary but also provides a superior trade-off between speed and accuracy among all existing methods. With comprehensive superiority, DAL is an ideal baseline for both future work development and practical deployment. The code has been released to facilitate future work on https://github.com/HuangJunJie2017/BEVDet.
Unconstrained Facial Landmark Localization with Backbone-Branches Fully-Convolutional Networks
Apr 14, 2016



This paper investigates how to rapidly and accurately localize facial landmarks in unconstrained, cluttered environments rather than in the well segmented face images. We present a novel Backbone-Branches Fully-Convolutional Neural Network (BB-FCN), which produces facial landmark response maps directly from raw images without relying on pre-process or sliding window approaches. BB-FCN contains one backbone and a number of network branches with each corresponding to one landmark type, and it operates in a progressive manner. Specifically, the backbone roughly detects the locations of facial landmarks by taking the whole image as input, and the branches further refine the localizations based on a local observation from the backbone's intermediate feature map. Moreover, our backbone-branches architecture does not contain full-connection layers for location regression, leading to efficient learning and inference. Our extensive experiments show that our model achieves superior performances over other state-of-the-arts under both the constrained (i.e. with face regions) and the "in the wild" scenarios.
Deep Joint Task Learning for Generic Object Extraction
Feb 03, 2015



This paper investigates how to extract objects-of-interest without relying on hand-craft features and sliding windows approaches, that aims to jointly solve two sub-tasks: (i) rapidly localizing salient objects from images, and (ii) accurately segmenting the objects based on the localizations. We present a general joint task learning framework, in which each task (either object localization or object segmentation) is tackled via a multi-layer convolutional neural network, and the two networks work collaboratively to boost performance. In particular, we propose to incorporate latent variables bridging the two networks in a joint optimization manner. The first network directly predicts the positions and scales of salient objects from raw images, and the latent variables adjust the object localizations to feed the second network that produces pixelwise object masks. An EM-type method is presented for the optimization, iterating with two steps: (i) by using the two networks, it estimates the latent variables by employing an MCMC-based sampling method; (ii) it optimizes the parameters of the two networks unitedly via back propagation, with the fixed latent variables. Extensive experiments suggest that our framework significantly outperforms other state-of-the-art approaches in both accuracy and efficiency (e.g. 1000 times faster than competing approaches).
* 9 pages, 4 figures, NIPS 2014
An Expressive Deep Model for Human Action Parsing from A Single Image
Feb 02, 2015

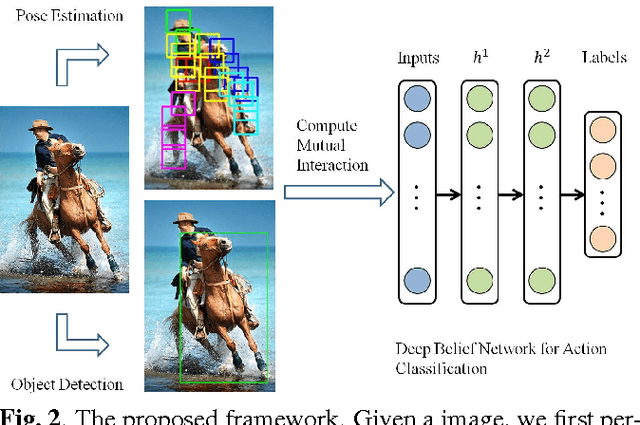

This paper aims at one newly raising task in vision and multimedia research: recognizing human actions from still images. Its main challenges lie in the large variations in human poses and appearances, as well as the lack of temporal motion information. Addressing these problems, we propose to develop an expressive deep model to naturally integrate human layout and surrounding contexts for higher level action understanding from still images. In particular, a Deep Belief Net is trained to fuse information from different noisy sources such as body part detection and object detection. To bridge the semantic gap, we used manually labeled data to greatly improve the effectiveness and efficiency of the pre-training and fine-tuning stages of the DBN training. The resulting framework is shown to be robust to sometimes unreliable inputs (e.g., imprecise detections of human parts and objects), and outperforms the state-of-the-art approaches.