 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterising Toxicity in Generative Large Language Models
Jan 10, 2026In recent years, the advent of the attention mechanism has significantly advanced the field of natural language processing (NLP), revolutionizing text processing and text generation. This has come about through transformer-based decoder-only architectures, which have become ubiquitous in NLP due to their impressive text processing and generation capabilities. Despite these breakthroughs, language models (LMs) remain susceptible to generating undesired outputs: inappropriate, offensive, or otherwise harmful responses. We will collectively refer to these as ``toxic'' outputs. Although methods like reinforcement learning from human feedback (RLHF) have been developed to align model outputs with human values, these safeguards can often be circumvented through carefully crafted prompts. Therefore, this paper examines the extent to which LLMs generate toxic content when prompted, as well as the linguistic factors -- both lexical and syntactic -- that influence the production of such outputs in generative models.
Multi-Objective Bilevel Learning
Nov 11, 2025As machine learning (ML) applications grow increasingly complex in recent years, modern ML frameworks often need to address multiple potentially conflicting objectives with coupled decision variables across different layers. This creates a compelling need for multi-objective bilevel learning (MOBL). So far, however, the field of MOBL remains in its infancy and many important problems remain under-explored. This motivates us to fill this gap and systematically investigate the theoretical and algorithmic foundation of MOBL. Specifically, we consider MOBL problems with multiple conflicting objectives guided by preferences at the upper-level subproblem, where part of the inputs depend on the optimal solution of the lower-level subproblem. Our goal is to develop efficient MOBL optimization algorithms to (1) identify a preference-guided Pareto-stationary solution with low oracle complexity; and (2) enable systematic Pareto front exploration. To this end, we propose a unifying algorithmic framework called weighted-Chebyshev multi-hyper-gradient-descent (WC-MHGD) for both deterministic and stochastic settings with finite-time Pareto-stationarity convergence rate guarantees, which not only implies low oracle complexity but also induces systematic Pareto front exploration. We further conduct extensive experiments to confirm our theoretical results.
Consensus-based Decentralized Multi-agent Reinforcement Learning for Random Access Network Optimization
Aug 09, 2025With wireless devices increasingly forming a unified smart network for seamless, user-friendly operations, random access (RA) medium access control (MAC) design is considered a key solution for handling unpredictable data traffic from multiple terminals. However, it remains challenging to design an effective RA-based MAC protocol to minimize collisions and ensure transmission fairness across the devices. While existing multi-agent reinforcement learning (MARL) approaches with centralized training and decentralized execution (CTDE) have been proposed to optimize RA performance, their reliance on centralized training and the significant overhead required for information collection can make real-world applications unrealistic. In this work, we adopt a fully decentralized MARL architecture, where policy learning does not rely on centralized tasks but leverages consensus-based information exchanges across devices. We design our MARL algorithm over an actor-critic (AC) network and propose exchanging only local rewards to minimize communication overhead. Furthermore, we provide a theoretical proof of global convergence for our approach. Numerical experiments show that our proposed MARL algorithm can significantly improve RA network performance compared to other baselines.
Finite-Time Global Optimality Convergence in Deep Neural Actor-Critic Methods for Decentralized Multi-Agent Reinforcement Learning
May 24, 2025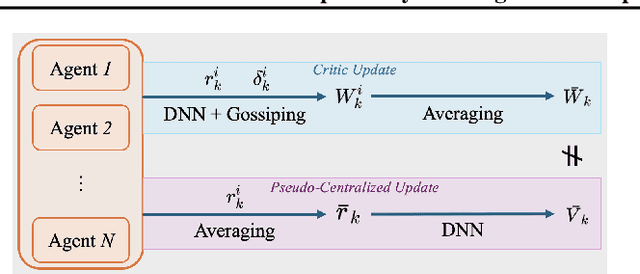



Actor-critic methods for decentralized multi-agent reinforcement learning (MARL) facilitate collaborative optimal decision making without centralized coordination, thus enabling a wide range of applications in practice. To date, however, most theoretical convergence studies for existing actor-critic decentralized MARL methods are limited to the guarantee of a stationary solution under the linear function approximation. This leaves a significant gap between the highly successful use of deep neural actor-critic for decentralized MARL in practice and the current theoretical understanding. To bridge this gap, in this paper, we make the first attempt to develop a deep neural actor-critic method for decentralized MARL, where both the actor and critic components are inherently non-linear. We show that our proposed method enjoys a global optimality guarantee with a finite-time convergence rate of O(1/T), where T is the total iteration times. This marks the first global convergence result for deep neural actor-critic methods in the MARL literature. We also conduct extensive numerical experiments, which verify our theoretical results.
InstanceGaussian: Appearance-Semantic Joint Gaussian Representation for 3D Instance-Level Perception
Nov 28, 2024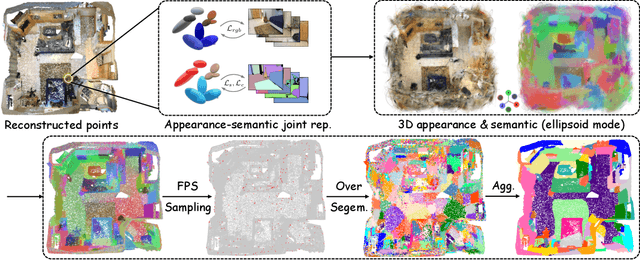
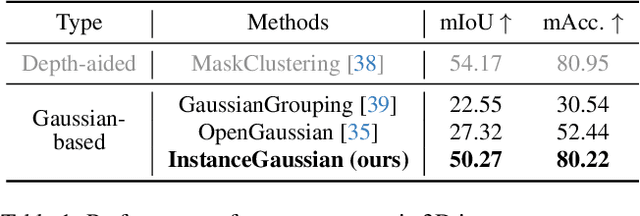
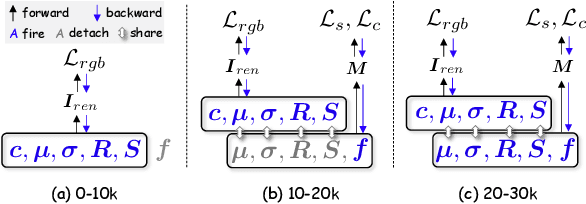
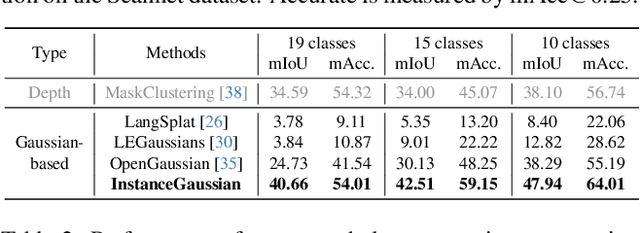
3D scene understanding has become an essential area of research with applications in autonomous driving, robotics, and augmented reality. Recently, 3D Gaussian Splatting (3DGS) has emerged as a powerful approach, combining explicit modeling with neural adaptability to provide efficient and detailed scene representations. However, three major challenges remain in leveraging 3DGS for scene understanding: 1) an imbalance between appearance and semantics, where dense Gaussian usage for fine-grained texture modeling does not align with the minimal requirements for semantic attributes; 2) inconsistencies between appearance and semantics, as purely appearance-based Gaussians often misrepresent object boundaries; and 3) reliance on top-down instance segmentation methods, which struggle with uneven category distributions, leading to over- or under-segmentation. In this work, we propose InstanceGaussian, a method that jointly learns appearance and semantic features while adaptively aggregating instances. Our contributions include: i) a novel Semantic-Scaffold-GS representation balancing appearance and semantics to improve feature representations and boundary delineation; ii) a progressive appearance-semantic joint training strategy to enhance stability and segmentation accuracy; and iii) a bottom-up, category-agnostic instance aggregation approach that addresses segmentation challenges through farthest point sampling and connected component analysis. Our approach achieves state-of-the-art performance in category-agnostic, open-vocabulary 3D point-level segmentation, highlighting the effectiveness of the proposed representation and training strategies. Project page: https://lhj-git.github.io/InstanceGaussian/
S3-SLAM: Sparse Tri-plane Encoding for Neural Implicit SLAM
Apr 28, 2024With the emergence of Neural Radiance Fields (NeRF), neural implicit representations have gained widespread applications across various domains, including simultaneous localization and mapping. However, current neural implicit SLAM faces a challenging trade-off problem between performance and the number of parameters. To address this problem, we propose sparse tri-plane encoding, which efficiently achieves scene reconstruction at resolutions up to 512 using only 2~4% of the commonly used tri-plane parameters (reduced from 100MB to 2~4MB). On this basis, we design S3-SLAM to achieve rapid and high-quality tracking and mapping through sparsifying plane parameters and integrating orthogonal features of tri-plane. Furthermore, we develop hierarchical bundle adjustment to achieve globally consistent geometric structures and reconstruct high-resolution appearance. Experimental results demonstrate that our approach achieves competitive tracking and scene reconstruction with minimal parameters on three datasets. Source code will soon be available.
GraphAD: Interaction Scene Graph for End-to-end Autonomous Driving
Apr 07, 2024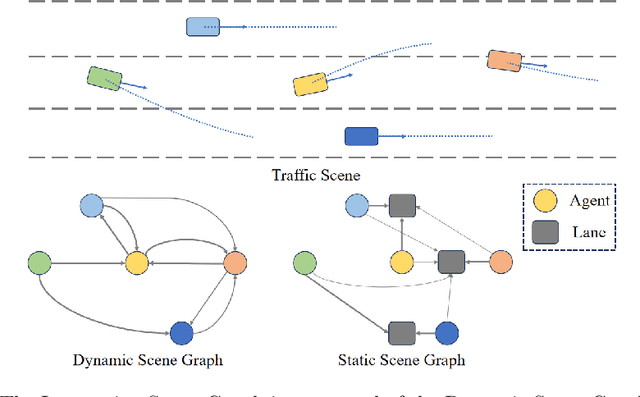
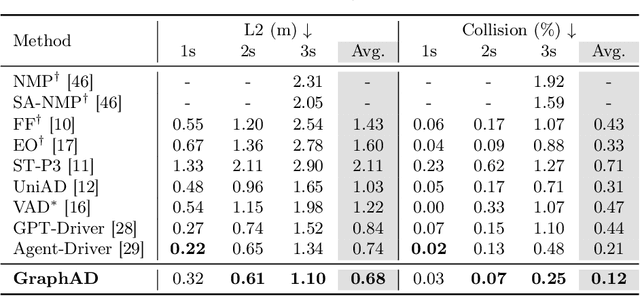
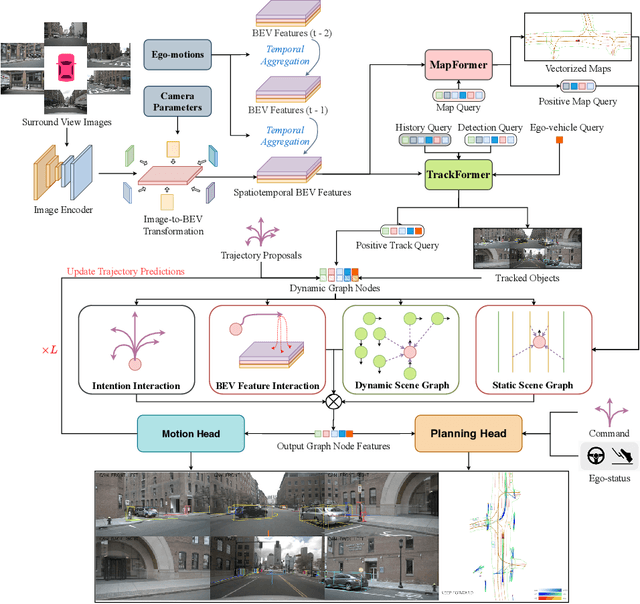
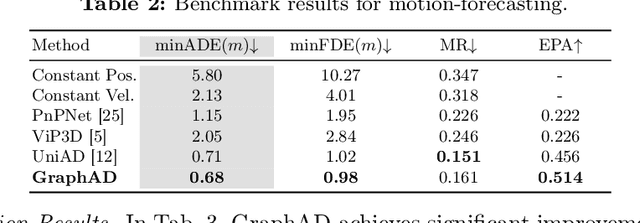
Modeling complicated interactions among the ego-vehicle, road agents, and map elements has been a crucial part for safety-critical autonomous driving. Previous works on end-to-end autonomous driving rely on the attention mechanism for handling heterogeneous interactions, which fails to capture the geometric priors and is also computationally intensive. In this paper, we propose the Interaction Scene Graph (ISG) as a unified method to model the interactions among the ego-vehicle, road agents, and map elements. With the representation of the ISG, the driving agents aggregate essential information from the most influential elements, including the road agents with potential collisions and the map elements to follow. Since a mass of unnecessary interactions are omitted, the more efficient scene-graph-based framework is able to focus on indispensable connections and leads to better performance. We evaluate the proposed method for end-to-end autonomous driving on the nuScenes dataset. Compared with strong baselines, our method significantly outperforms in the full-stack driving tasks, including perception, prediction, and planning. Code will be released at https://github.com/zhangyp15/GraphAD.
Adversarial Attacks on Cooperative Multi-agent Bandits
Nov 03, 2023Cooperative multi-agent multi-armed bandits (CMA2B) consider the collaborative efforts of multiple agents in a shared multi-armed bandit game. We study latent vulnerabilities exposed by this collaboration and consider adversarial attacks on a few agents with the goal of influencing the decisions of the rest. More specifically, we study adversarial attacks on CMA2B in both homogeneous settings, where agents operate with the same arm set, and heterogeneous settings, where agents have distinct arm sets. In the homogeneous setting, we propose attack strategies that, by targeting just one agent, convince all agents to select a particular target arm $T-o(T)$ times while incurring $o(T)$ attack costs in $T$ rounds. In the heterogeneous setting, we prove that a target arm attack requires linear attack costs and propose attack strategies that can force a maximum number of agents to suffer linear regrets while incurring sublinear costs and only manipulating the observations of a few target agents. Numerical experiments validate the effectiveness of our proposed attack strategies.
MARVEL: Multi-Agent Reinforcement-Learning for Large-Scale Variable Speed Limits
Oct 18, 2023



Variable speed limit (VSL) control is a promising traffic management strategy for enhancing safety and mobility. This work introduces MARVEL, a multi-agent reinforcement learning (MARL) framework for implementing large-scale VSL control on freeway corridors using only commonly available data. The agents learn through a reward structure that incorporates adaptability to traffic conditions, safety, and mobility; enabling coordination among the agents. The proposed framework scales to cover corridors with many gantries thanks to a parameter sharing among all VSL agents. The agents are trained in a microsimulation environment based on a short freeway stretch with 8 gantries spanning 7 miles and tested with 34 gantries spanning 17 miles of I-24 near Nashville, TN. MARVEL improves traffic safety by 63.4% compared to the no control scenario and enhances traffic mobility by 14.6% compared to a state-of-the-practice algorithm that has been deployed on I-24. An explainability analysis is undertaken to explore the learned policy under different traffic conditions and the results provide insights into the decision-making process of agents. Finally, we test the policy learned from the simulation-based experiments on real input data from I-24 to illustrate the potential deployment capability of the learned policy.
Adversarial Attacks on Online Learning to Rank with Click Feedback
May 26, 2023



Online learning to rank (OLTR) is a sequential decision-making problem where a learning agent selects an ordered list of items and receives feedback through user clicks. Although potential attacks against OLTR algorithms may cause serious losses in real-world applications, little is known about adversarial attacks on OLTR. This paper studies attack strategies against multiple variants of OLTR. Our first result provides an attack strategy against the UCB algorithm on classical stochastic bandits with binary feedback, which solves the key issues caused by bounded and discrete feedback that previous works can not handle. Building on this result, we design attack algorithms against UCB-based OLTR algorithms in position-based and cascade models. Finally, we propose a general attack strategy against any algorithm under the general click model. Each attack algorithm manipulates the learning agent into choosing the target attack item $T-o(T)$ times, incurring a cumulative cost of $o(T)$. Experiments on synthetic and real data further validate the effectiveness of our proposed attack algorithms.